使用 Python 和 Asyncio 编写在线多用人游戏(二)

你在 Python 中用过异步编程吗?本文中我会告诉你怎样做,而且用一个能工作的例子来展示它:这是一个流行的贪吃蛇游戏,而且是为多人游戏而设计的。
介绍和理论部分参见“第一部分 异步化”。
3、编写游戏循环主体
游戏循环是每一个游戏的核心。它持续地运行以读取玩家的输入、更新游戏的状态,并且在屏幕上渲染游戏结果。在在线游戏中,游戏循环分为客户端和服务端两部分,所以一般有两个循环通过网络通信。通常客户端的角色是获取玩家输入,比如按键或者鼠标移动,将数据传输给服务端,然后接收需要渲染的数据。服务端处理来自玩家的所有数据,更新游戏的状态,执行渲染下一帧的必要计算,然后将结果传回客户端,例如游戏中对象的新位置。如果没有可靠的理由,不混淆客户端和服务端的角色是一件很重要的事。如果你在客户端执行游戏逻辑的计算,很容易就会和其它客户端失去同步,其实你的游戏也可以通过简单地传递客户端的数据来创建。
游戏循环的一次迭代称为一个 嘀嗒 。嘀嗒是一个事件,表示当前游戏循环的迭代已经结束,下一帧(或者多帧)的数据已经就绪。
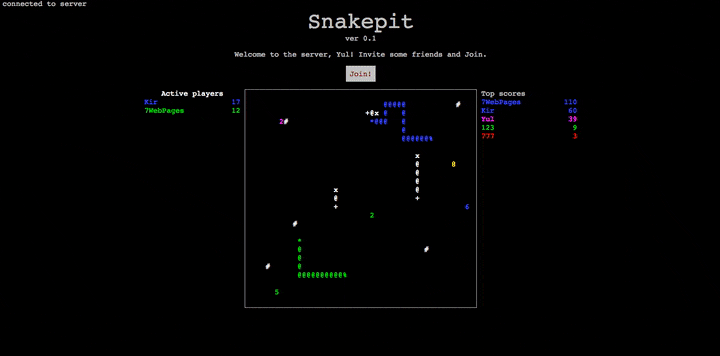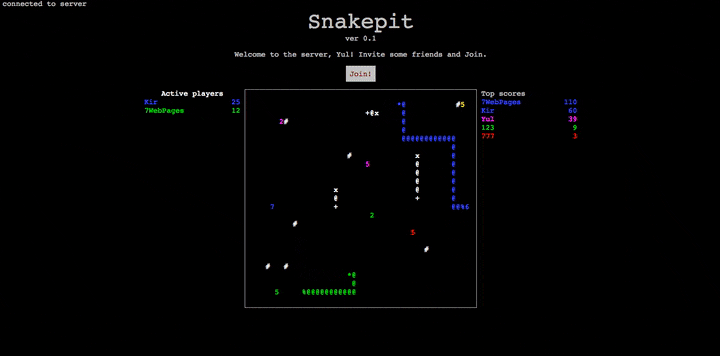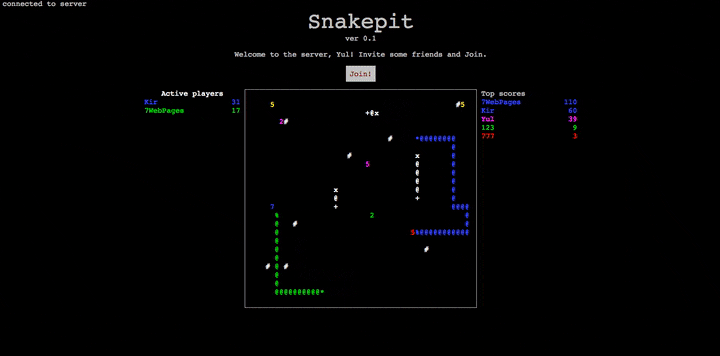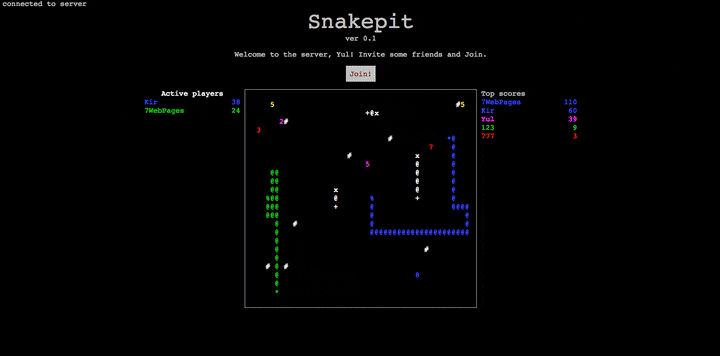
在后面的例子中,我们使用相同的客户端,它使用 WebSocket 从一个网页上连接到服务端。它执行一个简单的循环,将按键码发送给服务端,并显示来自服务端的所有信息。客户端代码戳这里。
例子 3.1:基本游戏循环
我们使用 aiohttp 库来创建游戏服务器。它可以通过 asyncio 创建网页服务器和客户端。这个库的一个优势是它同时支持普通 http 请求和 websocket。所以我们不用其他网页服务器来渲染游戏的 html 页面。
下面是启动服务器的方法:
app = web.Application()
app["sockets"] = []
asyncio.ensure_future(game_loop(app))
app.router.add_route('GET', '/connect', wshandler)
app.router.add_route('GET', '/', handle)
web.run_app(app)
web.run_app 是创建服务主任务的快捷方法,通过它的 run_forever() 方法来执行 asyncio 事件循环。建议你查看这个方法的源码,弄清楚服务器到底是如何创建和结束的。
app 变量就是一个类似于字典的对象,它用于在所连接的客户端之间共享数据。我们使用它来存储连接的套接字的列表。随后会用这个列表来给所有连接的客户端发送消息。asyncio.ensure_future() 调用会启动主游戏循环的任务,每隔2 秒向客户端发送嘀嗒消息。这个任务会在同样的 asyncio 事件循环中和网页服务器并行执行。
有两个网页请求处理器:handle 是提供 html 页面的处理器;wshandler 是主要的 websocket 服务器任务,处理和客户端之间的交互。在事件循环中,每一个连接的客户端都会创建一个新的 wshandler 任务。这个任务会添加客户端的套接字到列表中,以便 game_loop 任务可以给所有的客户端发送消息。然后它将随同消息回显客户端的每个击键。
在启动的任务中,我们在 asyncio 的主事件循环中启动 worker 循环。任务之间的切换发生在它们之间任何一个使用 await语句来等待某个协程结束时。例如 asyncio.sleep 仅仅是将程序执行权交给调度器一段指定的时间;ws.receive 等待 websocket 的消息,此时调度器可能切换到其它任务。
在浏览器中打开主页,连接上服务器后,试试随便按下键。它们的键值会从服务端返回,每隔 2 秒这个数字会被游戏循环中发给所有客户端的嘀嗒消息所覆盖。
我们刚刚创建了一个处理客户端按键的服务器,主游戏循环在后台做一些处理,周期性地同时更新所有的客户端。
例子 3.2: 根据请求启动游戏
在前一个例子中,在服务器的生命周期内,游戏循环一直运行着。但是现实中,如果没有一个人连接服务器,空运行游戏循环通常是不合理的。而且,同一个服务器上可能有不同的“游戏房间”。在这种假设下,每一个玩家“创建”一个游戏会话(比如说,多人游戏中的一个比赛或者大型多人游戏中的副本),这样其他用户可以加入其中。当游戏会话开始时,游戏循环才开始执行。
在这个例子中,我们使用一个全局标记来检测游戏循环是否在执行。当第一个用户发起连接时,启动它。最开始,游戏循环没有执行,标记设置为 False。游戏循环是通过客户端的处理方法启动的。
if app["game_is_running"] == False:
asyncio.ensure_future(game_loop(app))
当 game_loop() 运行时,这个标记设置为 True;当所有客户端都断开连接时,其又被设置为 False。
例子 3.3:管理任务
这个例子用来解释如何和任务对象协同工作。我们把游戏循环的任务直接存储在游戏循环的全局字典中,代替标记的使用。在像这样的一个简单例子中并不一定是最优的,但是有时候你可能需要控制所有已经启动的任务。
if app["game_loop"] is None or \
app["game_loop"].cancelled():
app["game_loop"] = asyncio.ensure_future(game_loop(app))
这里 ensure_future() 返回我们存放在全局字典中的任务对象,当所有用户都断开连接时,我们使用下面方式取消任务:
app["game_loop"].cancel()
这个 cancel() 调用将通知调度器不要向这个协程传递执行权,而且将它的状态设置为已取消:cancelled,之后可以通过 cancelled() 方法来检查是否已取消。这里有一个值得一提的小注意点:当你持有一个任务对象的外部引用时,而这个任务执行中发生了异常,这个异常不会抛出。取而代之的是为这个任务设置一个异常状态,可以通过 exception() 方法来检查是否出现了异常。这种悄无声息地失败在调试时不是很有用。所以,你可能想用抛出所有异常来取代这种做法。你可以对所有未完成的任务显式地调用 result() 来实现。可以通过如下的回调来实现:
app["game_loop"].add_done_callback(lambda t: t.result())
如果我们打算在我们代码中取消这个任务,但是又不想产生 CancelError 异常,有一个检查 cancelled 状态的点:
app["game_loop"].add_done_callback(lambda t: t.result()
if not t.cancelled() else None)
注意仅当你持有任务对象的引用时才需要这么做。在前一个例子,所有的异常都是没有额外的回调,直接抛出所有异常。
例子 3.4:等待多个事件
在许多场景下,在客户端的处理方法中你需要等待多个事件的发生。除了来自客户端的消息,你可能需要等待不同类型事件的发生。比如,如果你的游戏时间有限制,那么你可能需要等一个来自定时器的信号。或者你需要使用管道来等待来自其它进程的消息。亦或者是使用分布式消息系统的网络中其它服务器的信息。
为了简单起见,这个例子是基于例子 3.1。但是这个例子中我们使用 Condition 对象来与已连接的客户端保持游戏循环的同步。我们不保存套接字的全局列表,因为只在该处理方法中使用套接字。当游戏循环停止迭代时,我们使用 Condition.notify_all() 方法来通知所有的客户端。这个方法允许在 asyncio 的事件循环中使用发布/订阅的模式。
为了等待这两个事件,首先我们使用 ensure_future() 来封装任务中这个可等待对象。
if not recv_task:
recv_task = asyncio.ensure_future(ws.receive())
if not tick_task:
await tick.acquire()
tick_task = asyncio.ensure_future(tick.wait())
在我们调用 Condition.wait() 之前,我们需要在它后面获取一把锁。这就是我们为什么先调用 tick.acquire() 的原因。在调用 tick.wait() 之后,锁会被释放,这样其他的协程也可以使用它。但是当我们收到通知时,会重新获取锁,所以在收到通知后需要调用 tick.release() 来释放它。
我们使用 asyncio.wait() 协程来等待两个任务。
done, pending = await asyncio.wait(
[recv_task,
tick_task],
return_when=asyncio.FIRST_COMPLETED)
程序会阻塞,直到列表中的任意一个任务完成。然后它返回两个列表:执行完成的任务列表和仍然在执行的任务列表。如果任务执行完成了,其对应变量赋值为 None,所以在下一个迭代时,它可能会被再次创建。
例子 3.5: 结合多个线程
在这个例子中,我们结合 asyncio 循环和线程,在一个单独的线程中执行主游戏循环。我之前提到过,由于 GIL 的存在,Python 代码的真正并行执行是不可能的。所以使用其它线程来执行复杂计算并不是一个好主意。然而,在使用 asyncio 时结合线程有原因的:当我们使用的其它库不支持 asyncio 时就需要。在主线程中调用这些库会阻塞循环的执行,所以异步使用他们的唯一方法是在不同的线程中使用他们。
我们使用 asyncio 循环的run_in_executor() 方法和 ThreadPoolExecutor 来执行游戏循环。注意 game_loop() 已经不再是一个协程了。它是一个由其它线程执行的函数。然而我们需要和主线程交互,在游戏事件到来时通知客户端。asyncio 本身不是线程安全的,它提供了可以在其它线程中执行你的代码的方法。普通函数有 call_soon_threadsafe(),协程有 run_coroutine_threadsafe()。我们在 notify() 协程中增加了通知客户端游戏的嘀嗒的代码,然后通过另外一个线程执行主事件循环。
def game_loop(asyncio_loop):
print("Game loop thread id {}".format(threading.get_ident()))
async def notify():
print("Notify thread id {}".format(threading.get_ident()))
await tick.acquire()
tick.notify_all()
tick.release()
while 1:
task = asyncio.run_coroutine_threadsafe(notify(), asyncio_loop)
# blocking the thread
sleep(1)
# make sure the task has finished
task.result()
当你执行这个例子时,你会看到 “Notify thread id” 和 “Main thread id” 相等,因为 notify() 协程在主线程中执行。与此同时 sleep(1) 在另外一个线程中执行,因此它不会阻塞主事件循环。
例子 3.6:多进程和扩展
单线程的服务器可能运行得很好,但是它只能使用一个 CPU 核。为了将服务扩展到多核,我们需要执行多个进程,每个进程执行各自的事件循环。这样我们需要在进程间交互信息或者共享游戏的数据。而且在一个游戏中经常需要进行复杂的计算,例如路径查找之类。这些任务有时候在一个游戏嘀嗒中没法快速完成。在协程中不推荐进行费时的计算,因为它会阻塞事件的处理。在这种情况下,将这个复杂任务交给其它并行执行的进程可能更合理。
最简单的使用多个核的方法是启动多个使用单核的服务器,就像之前的例子中一样,每个服务器占用不同的端口。你可以使用 supervisord 或者其它进程控制的系统。这个时候你需要一个像 HAProxy 这样的负载均衡器,使得连接的客户端分布在多个进程间。已经有一些可以连接 asyncio 和一些流行的消息及存储系统的适配系统。例如:
你可以在 github 或者 pypi 上找到其它的软件包,大部分以 aio 开头。
使用网络服务在存储持久状态和交换某些信息时可能比较有效。但是如果你需要进行进程间通信的实时处理,它的性能可能不足。此时,使用标准的 unix 管道可能更合适。asyncio 支持管道,在aiohttp仓库有个 使用管道的服务器的非常底层的例子。
在当前的例子中,我们使用 Python 的高层类库 multiprocessing 来在不同的核上启动复杂的计算,使用 multiprocessing.Queue 来进行进程间的消息交互。不幸的是,当前的 multiprocessing 实现与 asyncio 不兼容。所以每一个阻塞方法的调用都会阻塞事件循环。但是此时线程正好可以起到帮助作用,因为如果在不同线程里面执行 multiprocessing 的代码,它就不会阻塞主线程。所有我们需要做的就是把所有进程间的通信放到另外一个线程中去。这个例子会解释如何使用这个方法。和上面的多线程例子非常类似,但是我们从线程中创建的是一个新的进程。
def game_loop(asyncio_loop):
# coroutine to run in main thread
async def notify():
await tick.acquire()
tick.notify_all()
tick.release()
queue = Queue()
# function to run in a different process
def worker():
while 1:
print("doing heavy calculation in process {}".format(os.getpid()))
sleep(1)
queue.put("calculation result")
Process(target=worker).start()
while 1:
# blocks this thread but not main thread with event loop
result = queue.get()
print("getting {} in process {}".format(result, os.getpid()))
task = asyncio.run_coroutine_threadsafe(notify(), asyncio_loop)
task.result()
这里我们在另外一个进程中运行 worker() 函数。它包括一个执行复杂计算并把计算结果放到 queue 中的循环,这个 queue 是 multiprocessing.Queue 的实例。然后我们就可以在另外一个线程的主事件循环中获取结果并通知客户端,就和例子 3.5 一样。这个例子已经非常简化了,它没有合理的结束进程。而且在真实的游戏中,我们可能需要另外一个队列来将数据传递给 worker。
有一个项目叫 aioprocessing,它封装了 multiprocessing,使得它可以和 asyncio 兼容。但是实际上它只是和上面例子使用了完全一样的方法:从线程中创建进程。它并没有给你带来任何方便,除了它使用了简单的接口隐藏了后面的这些技巧。希望在 Python 的下一个版本中,我们能有一个基于协程且支持 asyncio 的 multiprocessing 库。
注意!如果你从主线程或者主进程中创建了一个不同的线程或者子进程来运行另外一个asyncio事件循环,你需要显式地使用asyncio.new_event_loop()来创建循环,不然的话可能程序不会正常工作。
作者:Kyrylo Subbotin 译者:chunyang-wen 校对:wxy
(题图来自:deviantart.com)