
巨头之间的终极对决:崛起的新星 Node.js 能否战胜巨人 Apache 和 Nginx?
我和你一样,都阅读过大量散布在互联网各处的意见或事实,其中有一些我认为是可靠的,而其它的可能是谣传,让人难以置信。
我读过的许多信息是相当矛盾的,有人深信 StackOverflow(比如这个和另一个),而其他人展示了一个清晰的令人惊讶的结果,这在推动我自己去做测试来验证结论的过程中扮演了重要的角色。
起初,我做了一些思想准备,我认为我可以避免自己进行实际测试来校验结论的麻烦——在我知道这一切之前我一直这样认为。
尽管如此,回顾之前,似乎我最初的想法是相当准确的,并且被我的测试再次印证。这个事实让我想起了当年我在学校学到的爱因斯坦和他的光电效应的实验,他面临着一个光的波粒二重性的问题,最初的结论是实验受到他的心理状态的影响,即当他期望结果是一个波的时候结果就会是一个波,反之亦然。
也就是说,我坚信我的结果不会在不久的将来被证明二重性,虽然我的心理状态可能在某种程度上对它们有影响。
关于比较
上面我读过一份材料具有一种革新的方式,在我看来,需要了解其自然而然的主观性和作者自身的偏见。
我决定采用这种方式,因此,提前声明以下内容:
开发者花了很多年来打磨他们的作品。那些取得了更高成就的人通常参考很多因素来做出自己的抉择,这是主观的做法;你需要推崇和捍卫你的技术决策。
也就是说,这个比较文章的着眼点不会成为另一篇“哥们,使用适合你的东西就好”的口水文章。我将会根据我的自身经验、需求和偏见提出建议。你可能会同意其中一些观点,反对另外一些;这很好——你的意见会帮助别人做出明智的选择。
感谢 SitePoint 的 Craig Buckler ,重新启发了我对比较类文章的看法——尝试重新忘记自我,并试图让所有的读者心悦诚服。
关于测试
所有的测试都在本地运行:
用于基准测试的工具:ApacheBench,2.3 <$Revision: 1748469 $>
测试包括一系列基准,从 1000 到 10000 个请求以及从 100 到 1000 个的并发请求——结果相当令人惊讶。
此外,我还进行了在高负载下测量服务器功能的压力测试。
至于内容,主要是一个包含一些 Lorem Ipsum 的标题和一张图片静态文件。
Lorem Ipsum 和 ApacheBenchmark
我决定专注于静态文件的原因是因为它们去除了可能对测试产生影响的各种渲染因素,例如:编程语言解释器的速度、解释器与服务器的集成程度等等。
此外,基于我自身的经验,平均网页加载时间很大一部分通常花费在静态内容上,例如图片,因此关注哪个服务器可以节省我们加载静态内容的时间是比较现实的。
除此之外,我还想测试一个更加真实的案例,案例中我在运行不同 CMS 的动态页面(稍后将详细介绍)时对服务器进行基准测试。
服务器
正如我用的是 Gentoo Linux,你就知道我的 HTTP 服务器在一开始就已经经过优化了,因为我在构建系统的时候只使用了我实际需要的东西。也就是说,当我运行我的测试的时候,不会在后台运行任何不必要的代码或加载没用的模块。
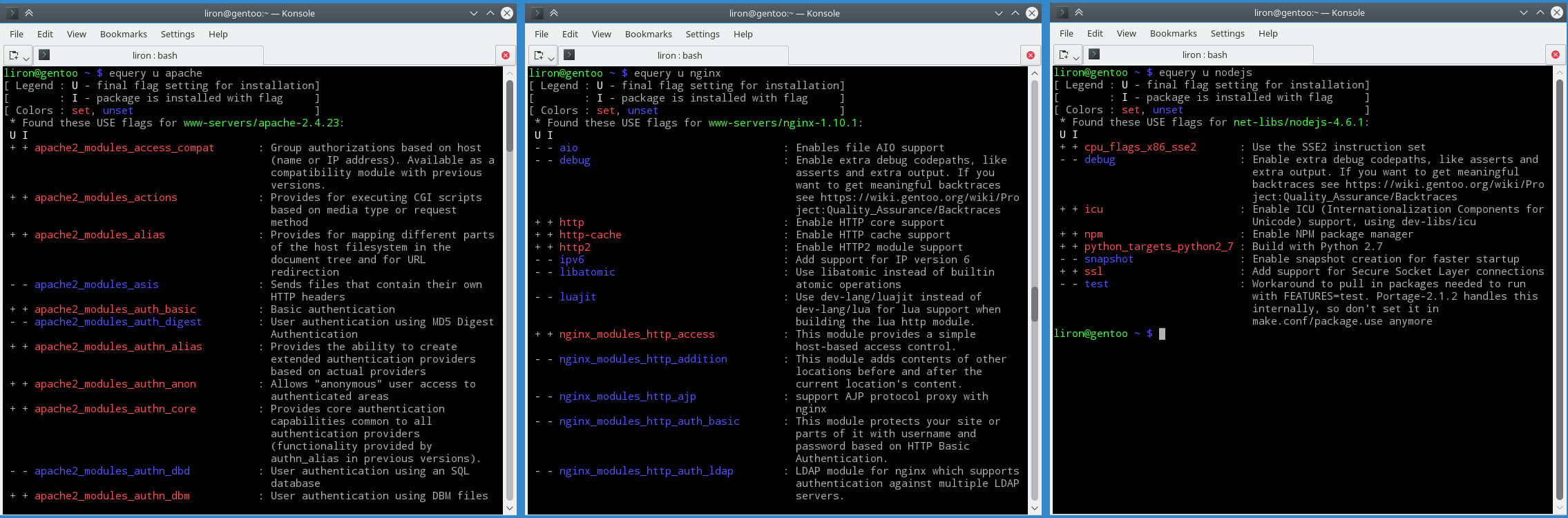
Apache、Nginx 和 Node.js 的使用的配置对比
Apache
$: curl -i http://localhost/index.html
HTTP/1.1 200 OK
Date: Sun, 30 Oct 2016 15:35:44 GMT
Server: Apache
Last-Modified: Sun, 30 Oct 2016 14:13:36 GMT
ETag: "2cf2-54015b280046d"
Accept-Ranges: bytes
Content-Length: 11506
Cache-Control: max-age=600
Expires: Sun, 30 Oct 2016 15:45:44 GMT
Vary: Accept-Encoding
Content-Type: text/html
Apache 配置了 “event mpm”。
Nginx
$: curl -i http://localhost/index.html
HTTP/1.1 200 OK
Server: nginx/1.10.1
Date: Sun, 30 Oct 2016 14:17:30 GMT
Content-Type: text/html
Content-Length: 11506
Last-Modified: Sun, 30 Oct 2016 14:13:36 GMT
Connection: keep-alive
Keep-Alive: timeout=20
ETag: "58160010-2cf2"
Accept-Ranges: bytes
Nginx 包括几个调整:sendfile on、tcp_nopush on 和 tcp_nodelay on。
Node.js
$: curl -i http://127.0.0.1:8080
HTTP/1.1 200 OK
Content-Length: 11506
Etag: 15
Last-Modified: Thu, 27 Oct 2016 14:09:58 GMT
Content-Type: text/html
Date: Sun, 30 Oct 2016 16:39:47 GMT
Connection: keep-alive
在静态测试中使用的 Node.js 服务器是从头定制的,这样可以让它尽可能更加的轻快——没有使用外部模块(Node 核心模块除外)。
测试结果
点击图片以放大:
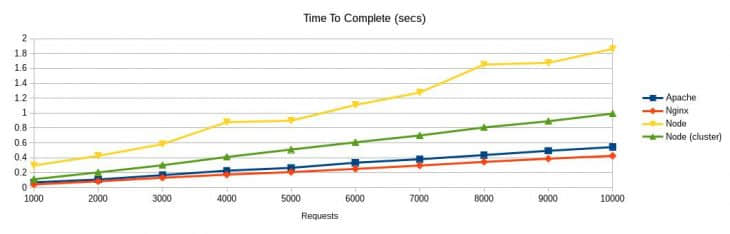
Apache、Nginx 与 Node 的对比:请求负载的性能(每 100 位并发用户)
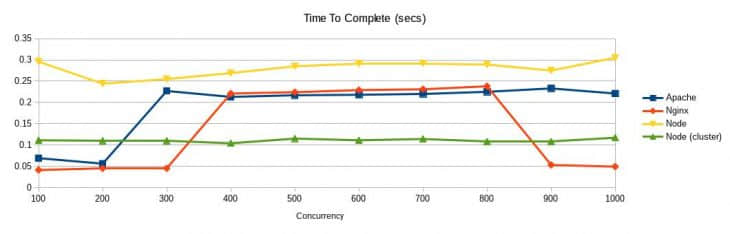
Apache、Nginx 与 Node 的对比:用户负载能力(每 1000 个请求)
压力测试
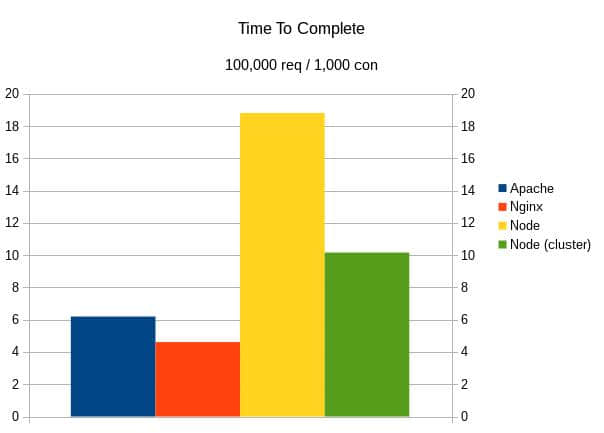
Apache、Nginx 与 Node 的对比:完成 1000 位用户并发的 100000 个请求耗时
我们可以从结果中得到什么?
从以上结果判断,似乎 Nginx 可以在最少的时间内完成最多请求,换句话来说,Nginx 是最快的 HTTP 服务器。
还有一个相当惊人的事实是,在特定的用户并发数和请求数下,Node.js 可以比 Nginx 和 Apache 更快。
但当请求的数量在并发测试中增加的时候,Nginx 将重回领先的位置,这个结果可以让那些陷入 Node.js 的遐想的人清醒一下。
和 Apache、Nginx 不同的是,Node.js 似乎对用户的并发数不太敏感,尤其是在集群节点。如图所示,集群节点在 0.1 秒左右保持一条直线,而 Apache 和 Nginx 都有大约 0.2 秒的波动。
基于上述统计可以得出的结论是:网站比较小,其使用的服务器就无所谓。然而,随着网站的受众越来越多,HTTP 服务器的影响变得愈加明显。
当涉及到每台服务器的原始速度的底线的时候,正如压力测试所描述的,我的感觉是,性能背后最关键的因素不是一些特定的算法,而实际上是运行的每台服务器所用的编程语言。
由于 Apache 和 Nginx 都使用了 C 语言—— AOT 语言(编译型语言),而 Node.js 使用了 JavaScript ——这是一种 JIT 语言(解释型语言)。这意味着 Node.js 在执行程序的过程中还有额外的工作负担。
这意味着我不能仅仅基于上面的结果来下结论,而要做进一步校验,正如你下面看到的结果,当我使用一台经过优化的 Node.js 服务器与流行的 Express 框架时,我得到几乎相同的性能结论。
全面考虑
逝者如斯夫,如果没有服务的内容,HTTP 服务器是没什么用的。因此,在比较 web 服务器的时候,我们必须考虑的一个重要的部分就是我们希望在上面运行的内容。
虽然也有其它的功能,但是 HTTP 服务器最广泛的使用就是运行网站。因此,为了看到每台服务器的性能的实际效果,我决定比较一下世界上使用最广泛的 CMS(内容管理系统)WordPress 和 Ghost —— 内核使用了 JavaScript 的一颗冉冉升起的明星。
基于 JavaScript 的 Ghost 网页能否胜过运行在 PHP 和 Apache / Nginx 上面的 WordPress 页面?
这是一个有趣的问题,因为 Ghost 具有操作工具单一且一致的优点——无需额外的封装,而 WordPress 需要依赖 Apache / Nginx 和 PHP 之间的集成,这可能会导致显著的性能缺陷。
除此之外,PHP 距 Node.js 之间还有一个显著的性能落差,后者更佳,我将在下面简要介绍一下,可能会出现一些与初衷大相径庭的结果。
PHP 与 Node.js 的对决
为了比较 WordPress 和 Ghost,我们必须首先考虑一个影响到两者的基本组件。
基本上,WordPress 是一个基于 PHP 的 CMS,而 Ghost 是基于 Node.js(JavaScript)的。与 PHP 不同,Node.js 有以下优点:
由于有大量的测评文章解释和演示了 Node.js 的原始速度超过 PHP(包括 PHP 7),我不会再进一步阐述这个主题,请你自行用谷歌搜索相关内容。
因此,考虑到 Node.js 的性能优于 PHP,一个 Node.js 的网站的速度要比 Apache / Nginx 和 PHP 的网站快吗?
WordPress 和 Ghost 对决
当比较 WordPress 和 Ghost 时,有些人会说这就像比较苹果和橘子,大多数情况下我同意这个观点,因为 WordPress 是一个完全成熟的 CMS,而 Ghost 基本上只是一个博客平台。
然而,两者仍然有共同竞争的市场,这两者都可以用于向世界发布你的个人文章。
制定一个前提,我们怎么比较两个完全基于不同的代码来运行的平台,包括风格主题和核心功能。
事实上,一个科学的实验测试条件是很难设计的。然而,在这个测试中我对更接近生活的情景更感兴趣,所以 WordPress 和 Ghost 都将保留其主题。因此,这里的目标是使两个平台的网页大小尽可能相似,让 PHP 和 Node.js 在幕后斗智斗勇。
由于结果是根据不同的标准进行测量的,最重要的是尺度不一样,因此在图表中并排显示它们是不公平的。因此,我改为使用表:
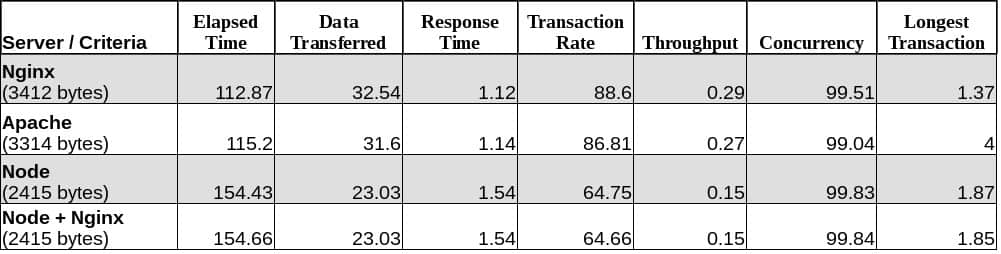
Node、Nginx、Apache 以及运行 WordPress 和 Ghost 的比较。前两行是 WordPress,底部的两行是 Ghost
正如你所见,尽管事实上 Ghost(Node.js)正在加载一个更小的页面(你可能会惊讶 1kb 可以产生这么大的差异),它仍然比同时使用 Nginx 和 Apache 的 WordPress 要慢。
此外,使用 Nginx 代理作为负载均衡器来接管每个 Node 服务器的请求实际上会提升还是降低性能?
那么,根据上面的表格,如果说它产生什么效果的话,它造成了更慢的效果——这是一个合理的结果,因为额外封装一层理所当然会使其变得更慢。当然,上面的数字也表明这点差异可以忽略不计。
但是上表中最重要的一点是,即使 Node.js 比 PHP 快,HTTP 服务器的作用也可能超过某个 web 平台使用的编程语言的重要性。
当然,另一方面,如果加载的页面更多地依赖于服务器端的脚本处理,那么我怀疑结果可能会有点不同。
最后,如果一个 web 平台真的想在这场竞赛里击败 WordPress,从这个比较中得出的结论就是,要想性能占优,必须要定制一些像 PHP-FPM 的工具,它将直接与 JavaScript 通信(而不是作为服务器来运行),因此它可以完全发挥 JavaScript 的力量来达到更好的性能。
via: https://iwf1.com/apache-vs-nginx-vs-node-js-and-what-it-means-about-the-performance-of-wordpress-vs-ghost/
作者:Liron 译者:OneNewLife 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出
(题图来自:deviantart.net)





{kind=link}