操作系统何时运行?

请各位思考以下问题:在你阅读本文的这段时间内,计算机中的操作系统在运行吗?又或者仅仅是 Web 浏览器在运行?又或者它们也许均处于空闲状态,等待着你的指示?
这些问题并不复杂,但它们深入涉及到系统软件工作的本质。为了准确回答这些问题,我们需要透彻理解操作系统的行为模型,包括性能、安全和除错等方面。在该系列文章中,我们将以 Linux 为主举例来帮助你建立操作系统的行为模型,OS X 和 Windows 在必要的时候也会有所涉及。对那些深度探索者,我会在适当的时候给出 Linux 内核源码的链接。
这里有一个基本认知,就是,在任意给定时刻,某个 CPU 上仅有一个任务处于活动状态。大多数情形下这个任务是某个用户程序,例如你的 Web 浏览器或音乐播放器,但它也可能是一个操作系统线程。可以确信的是,它是一个任务,不是两个或更多,也不是零个,对,永远是一个。
这听上去可能会有些问题。比如,你的音乐播放器是否会独占 CPU 而阻止其它任务运行?从而使你不能打开任务管理工具去杀死音乐播放器,甚至让鼠标点击也失效,因为操作系统没有机会去处理这些事件。你可能会愤而喊出,“它究竟在搞什么鬼?”,并引发骚乱。
此时便轮到中断大显身手了。中断就好比,一声巨响或一次拍肩后,神经系统通知大脑去感知外部刺激一般。计算机主板上的芯片组同样会中断 CPU 运行以传递新的外部事件,例如键盘上的某个键被按下、网络数据包的到达、一次硬盘读取的完成,等等。硬件外设、主板上的中断控制器和 CPU 本身,它们共同协作实现了中断机制。
中断对于记录我们最珍视的资源——时间——也至关重要。计算机启动过程中,操作系统内核会设置一个硬件计时器以让其产生周期性计时中断,例如每隔 10 毫秒触发一次。每当计时中断到来,内核便会收到通知以更新系统统计信息和盘点如下事项:当前用户程序是否已运行了足够长时间?是否有某个 TCP 定时器超时了?中断给予了内核一个处理这些问题并采取合适措施的机会。这就好像你给自己设置了整天的周期闹铃并把它们用作检查点:我是否应该去做我正在进行的工作?是否存在更紧急的事项?直到你发现 10 年时间已逝去……
这些内核对 CPU 周期性的劫持被称为 滴答 ,也就是说,是中断让你的操作系统滴答了一下。不止如此,中断也被用作处理一些软件事件,如整数溢出和页错误,其中未涉及外部硬件。中断是进入操作系统内核最频繁也是最重要的入口。对于学习电子工程的人而言,这些并无古怪,它们是操作系统赖以运行的机制。
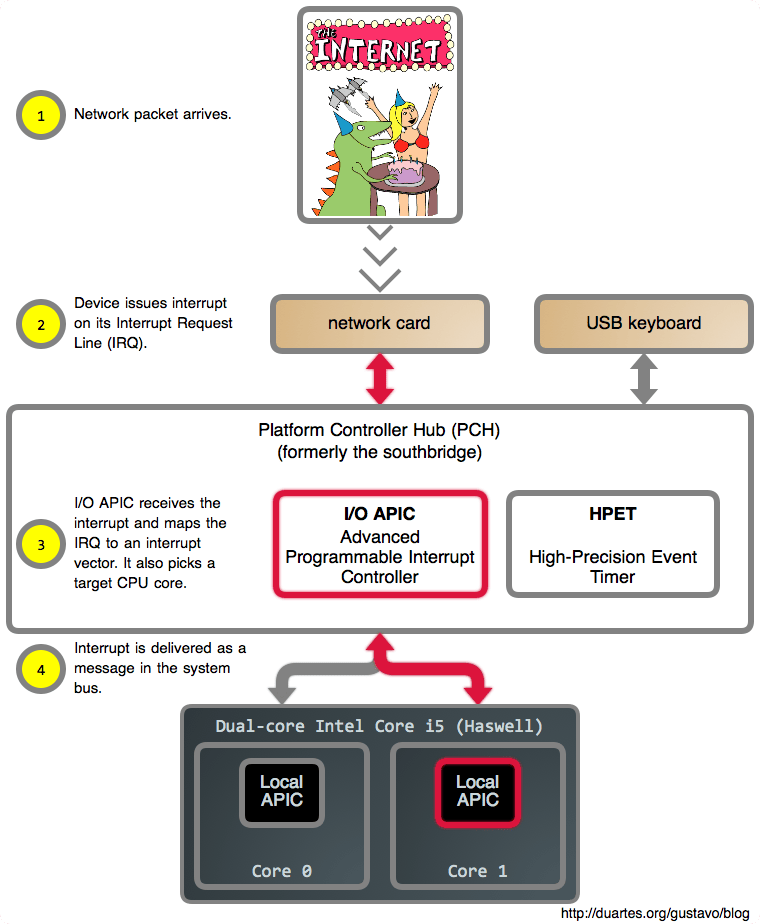
说到这里,让我们再来看一些实际情形。下图示意了 Intel Core i5 系统中的一个网卡中断。图片中的部分元素设置了超链,你可以点击它们以获取更为详细的信息,例如每个设备均被链接到了对应的 Linux 驱动源码。
链接如下:
让我们来仔细研究下。首先,由于系统中存在众多中断源,如果硬件只是通知 CPU “嘿,这里发生了一些事情”然后什么也不做,则不太行得通。这会带来难以忍受的冗长等待。因此,计算机上电时,每个设备都被授予了一根中断线,或者称为 IRQ。这些 IRQ 然后被系统中的中断控制器映射成值介于 0 到 255 之间的中断向量。等到中断到达 CPU,它便具备了一个完好定义的数值,异于硬件的某些其它诡异行为。
相应地,CPU 中还存有一个由内核维护的指针,指向一个包含 255 个函数指针的数组,其中每个函数被用来处理某个特定的中断向量。后文中,我们将继续深入探讨这个数组,它也被称作中断描述符表(IDT)。
每当中断到来,CPU 会用中断向量的值去索引中断描述符表,并执行相应处理函数。这相当于,在当前正在执行任务的上下文中,发生了一个特殊函数调用,从而允许操作系统以较小开销快速对外部事件作出反应。考虑下述场景,Web 服务器在发送数据时,CPU 却间接调用了操作系统函数,这听上去要么很炫酷要么令人惊恐。下图展示了 Vim 编辑器运行过程中一个中断到来的情形。
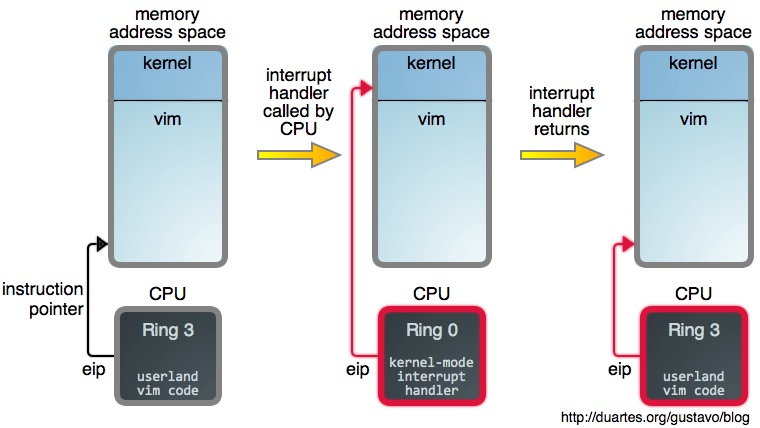
此处请留意,中断的到来是如何触发 CPU 到 Ring 0 内核模式的切换而未有改变当前活跃的任务。这看上去就像,Vim 编辑器直接面向操作系统内核产生了一次神奇的函数调用,但 Vim 还在那里,它的地址空间原封未动,等待着执行流返回。
这很令人振奋,不是么?不过让我们暂且告一段落吧,我需要合理控制篇幅。我知道还没有回答完这个开放式问题,甚至还实质上翻开了新的问题,但你至少知道了在你读这个句子的同时滴答正在发生。我们将在充实了对操作系统动态行为模型的理解之后再回来寻求问题的答案,对 Web 浏览器情形的理解也会变得清晰。如果你仍有问题,尤其是在这篇文章公诸于众后,请尽管提出。我将会在文章或后续评论中回答它们。下篇文章将于明天在 RSS 和 Twitter 上发布。
via: http://duartes.org/gustavo/blog/post/when-does-your-os-run/