了解区块链是如何工作的最快的方法是构建一个。

你看到这篇文章是因为和我一样,对加密货币的大热而感到兴奋。并且想知道区块链是如何工作的 —— 它们背后的技术基础是什么。
但是理解区块链并不容易 —— 至少对我来说是这样。我徜徉在各种难懂的视频中,并且因为示例太少而陷入深深的挫败感中。
我喜欢在实践中学习。这会使得我在代码层面上处理主要问题,从而可以让我坚持到底。如果你也是这么做的,在本指南结束的时候,你将拥有一个功能正常的区块链,并且实实在在地理解了它的工作原理。
开始之前 …
记住,区块链是一个 不可更改的、有序的 记录(被称为区块)的链。它们可以包括 交易 、文件或者任何你希望的真实数据。最重要的是它们是通过使用哈希链接到一起的。
如果你不知道哈希是什么,这里有解释。
本指南的目标读者是谁? 你应该能轻松地读、写一些基本的 Python 代码,并能够理解 HTTP 请求是如何工作的,因为我们讨论的区块链将基于 HTTP。
我需要做什么? 确保安装了 Python 3.6+(以及 pip),还需要去安装 Flask 和非常好用的 Requests 库:
pip install Flask==0.12.2 requests==2.18.4
当然,你也需要一个 HTTP 客户端,像 Postman 或者 cURL。哪个都行。
最终的代码在哪里可以找到? 源代码在 这里。
第 1 步:构建一个区块链
打开你喜欢的文本编辑器或者 IDE,我个人喜欢 PyCharm。创建一个名为 blockchain.py 的新文件。我将仅使用一个文件,如果你看晕了,可以去参考 源代码。
描述一个区块链
我们将创建一个 Blockchain 类,它的构造函数将去初始化一个空列表(去存储我们的区块链),以及另一个列表去保存交易。下面是我们的类规划:
class Blockchain(object):
def __init__(self):
self.chain = []
self.current_transactions = []
def new_block(self):
# Creates a new Block and adds it to the chain
pass
def new_transaction(self):
# Adds a new transaction to the list of transactions
pass
@staticmethod
def hash(block):
# Hashes a Block
pass
@property
def last_block(self):
# Returns the last Block in the chain
pass
我们的 Blockchain 类的原型
我们的 Blockchain 类负责管理链。它将存储交易并且有一些为链中增加新区块的辅助性质的方法。现在我们开始去充实一些类的方法。
区块是什么样子的?
每个区块有一个索引、一个时间戳(Unix 时间)、一个交易的列表、一个证明(后面会详细解释)、以及前一个区块的哈希。
单个区块的示例应该是下面的样子:
block = {
'index': 1,
'timestamp': 1506057125.900785,
'transactions': [
{
'sender': "8527147fe1f5426f9dd545de4b27ee00",
'recipient': "a77f5cdfa2934df3954a5c7c7da5df1f",
'amount': 5,
}
],
'proof': 324984774000,
'previous_hash': "2cf24dba5fb0a30e26e83b2ac5b9e29e1b161e5c1fa7425e73043362938b9824"
}
我们的区块链中的块示例
此刻,链的概念应该非常明显 —— 每个新区块包含它自身的信息和前一个区域的哈希。这一点非常重要,因为这就是区块链不可更改的原因:如果攻击者修改了一个早期的区块,那么所有的后续区块将包含错误的哈希。
这样做有意义吗?如果没有,就让时间来埋葬它吧 —— 这就是区块链背后的核心思想。
添加交易到一个区块
我们将需要一种区块中添加交易的方式。我们的 new_transaction() 就是做这个的,它非常简单明了:
class Blockchain(object):
...
def new_transaction(self, sender, recipient, amount):
"""
Creates a new transaction to go into the next mined Block
:param sender: <str> Address of the Sender
:param recipient: <str> Address of the Recipient
:param amount: <int> Amount
:return: <int> The index of the Block that will hold this transaction
"""
self.current_transactions.append({
'sender': sender,
'recipient': recipient,
'amount': amount,
})
return self.last_block['index'] + 1
在 new_transaction() 运行后将在列表中添加一个交易,它返回添加交易后的那个区块的索引 —— 那个区块接下来将被挖矿。提交交易的用户后面会用到这些。
创建新区块
当我们的 Blockchain 被实例化后,我们需要一个创世区块(一个没有祖先的区块)来播种它。我们也需要去添加一些 “证明” 到创世区块,它是挖矿(工作量证明 PoW)的成果。我们在后面将讨论更多挖矿的内容。
除了在我们的构造函数中创建创世区块之外,我们还需要写一些方法,如 new_block()、new_transaction() 以及 hash():
import hashlib
import json
from time import time
class Blockchain(object):
def __init__(self):
self.current_transactions = []
self.chain = []
# Create the genesis block
self.new_block(previous_hash=1, proof=100)
def new_block(self, proof, previous_hash=None):
"""
Create a new Block in the Blockchain
:param proof: <int> The proof given by the Proof of Work algorithm
:param previous_hash: (Optional) <str> Hash of previous Block
:return: <dict> New Block
"""
block = {
'index': len(self.chain) + 1,
'timestamp': time(),
'transactions': self.current_transactions,
'proof': proof,
'previous_hash': previous_hash or self.hash(self.chain[-1]),
}
# Reset the current list of transactions
self.current_transactions = []
self.chain.append(block)
return block
def new_transaction(self, sender, recipient, amount):
"""
Creates a new transaction to go into the next mined Block
:param sender: <str> Address of the Sender
:param recipient: <str> Address of the Recipient
:param amount: <int> Amount
:return: <int> The index of the Block that will hold this transaction
"""
self.current_transactions.append({
'sender': sender,
'recipient': recipient,
'amount': amount,
})
return self.last_block['index'] + 1
@property
def last_block(self):
return self.chain[-1]
@staticmethod
def hash(block):
"""
Creates a SHA-256 hash of a Block
:param block: <dict> Block
:return: <str>
"""
# We must make sure that the Dictionary is Ordered, or we'll have inconsistent hashes
block_string = json.dumps(block, sort_keys=True).encode()
return hashlib.sha256(block_string).hexdigest()
上面的内容简单明了 —— 我添加了一些注释和文档字符串,以使代码清晰可读。到此为止,表示我们的区块链基本上要完成了。但是,你肯定想知道新区块是如何被创建、打造或者挖矿的。
理解工作量证明
工作量证明 (PoW)算法是在区块链上创建或者挖出新区块的方法。PoW 的目标是去撞出一个能够解决问题的数字。这个数字必须满足“找到它很困难但是验证它很容易”的条件 —— 网络上的任何人都可以计算它。这就是 PoW 背后的核心思想。
我们来看一个非常简单的示例来帮助你了解它。
我们来解决一个问题,一些整数 x 乘以另外一个整数 y 的结果的哈希值必须以 0 结束。因此,hash(x * y) = ac23dc…0。为简单起见,我们先把 x = 5 固定下来。在 Python 中的实现如下:
from hashlib import sha256
x = 5
y = 0 # We don't know what y should be yet...
while sha256(f'{x*y}'.encode()).hexdigest()[-1] != "0":
y += 1
print(f'The solution is y = {y}')
在这里的答案是 y = 21。因为它产生的哈希值是以 0 结尾的:
hash(5 * 21) = 1253e9373e...5e3600155e860
在比特币中,工作量证明算法被称之为 Hashcash。与我们上面的例子没有太大的差别。这就是矿工们进行竞赛以决定谁来创建新块的算法。一般来说,其难度取决于在一个字符串中所查找的字符数量。然后矿工会因其做出的求解而得到奖励的币——在一个交易当中。
网络上的任何人都可以很容易地去核验它的答案。
实现基本的 PoW
为我们的区块链来实现一个简单的算法。我们的规则与上面的示例类似:
找出一个数字 p,它与前一个区块的答案进行哈希运算得到一个哈希值,这个哈希值的前四位必须是由 0 组成。
import hashlib
import json
from time import time
from uuid import uuid4
class Blockchain(object):
...
def proof_of_work(self, last_proof):
"""
Simple Proof of Work Algorithm:
- Find a number p' such that hash(pp') contains leading 4 zeroes, where p is the previous p'
- p is the previous proof, and p' is the new proof
:param last_proof: <int>
:return: <int>
"""
proof = 0
while self.valid_proof(last_proof, proof) is False:
proof += 1
return proof
@staticmethod
def valid_proof(last_proof, proof):
"""
Validates the Proof: Does hash(last_proof, proof) contain 4 leading zeroes?
:param last_proof: <int> Previous Proof
:param proof: <int> Current Proof
:return: <bool> True if correct, False if not.
"""
guess = f'{last_proof}{proof}'.encode()
guess_hash = hashlib.sha256(guess).hexdigest()
return guess_hash[:4] == "0000"
为了调整算法的难度,我们可以修改前导 0 的数量。但是 4 个零已经足够难了。你会发现,将前导 0 的数量每增加一,那么找到正确答案所需要的时间难度将大幅增加。
我们的类基本完成了,现在我们开始去使用 HTTP 请求与它交互。
第 2 步:以 API 方式去访问我们的区块链
我们将使用 Python Flask 框架。它是个微框架,使用它去做端点到 Python 函数的映射很容易。这样我们可以使用 HTTP 请求基于 web 来与我们的区块链对话。
我们将创建三个方法:
/transactions/new 在一个区块上创建一个新交易/mine 告诉我们的服务器去挖矿一个新区块/chain 返回完整的区块链
配置 Flask
我们的 “服务器” 将在我们的区块链网络中产生一个单个的节点。我们来创建一些样板代码:
import hashlib
import json
from textwrap import dedent
from time import time
from uuid import uuid4
from flask import Flask
class Blockchain(object):
...
# Instantiate our Node
app = Flask(__name__)
# Generate a globally unique address for this node
node_identifier = str(uuid4()).replace('-', '')
# Instantiate the Blockchain
blockchain = Blockchain()
@app.route('/mine', methods=['GET'])
def mine():
return "We'll mine a new Block"
@app.route('/transactions/new', methods=['POST'])
def new_transaction():
return "We'll add a new transaction"
@app.route('/chain', methods=['GET'])
def full_chain():
response = {
'chain': blockchain.chain,
'length': len(blockchain.chain),
}
return jsonify(response), 200
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
对上面的代码,我们做添加一些详细的解释:
- Line 15:实例化我们的节点。更多关于 Flask 的知识读 这里。
- Line 18:为我们的节点创建一个随机的名字。
- Line 21:实例化我们的区块链类。
- Line 24–26:创建
/mine 端点,这是一个 GET 请求。 - Line 28–30:创建
/transactions/new 端点,这是一个 POST 请求,因为我们要发送数据给它。 - Line 32–38:创建
/chain 端点,它返回全部区块链。 - Line 40–41:在 5000 端口上运行服务器。
交易端点
这就是对一个交易的请求,它是用户发送给服务器的:
{
"sender": "my address",
"recipient": "someone else's address",
"amount": 5
}
因为我们已经有了添加交易到块中的类方法,剩下的就很容易了。让我们写个函数来添加交易:
import hashlib
import json
from textwrap import dedent
from time import time
from uuid import uuid4
from flask import Flask, jsonify, request
...
@app.route('/transactions/new', methods=['POST'])
def new_transaction():
values = request.get_json()
# Check that the required fields are in the POST'ed data
required = ['sender', 'recipient', 'amount']
if not all(k in values for k in required):
return 'Missing values', 400
# Create a new Transaction
index = blockchain.new_transaction(values['sender'], values['recipient'], values['amount'])
response = {'message': f'Transaction will be added to Block {index}'}
return jsonify(response), 201
创建交易的方法
挖矿端点
我们的挖矿端点是见证奇迹的地方,它实现起来很容易。它要做三件事情:
- 计算工作量证明
- 因为矿工(我们)添加一个交易而获得报酬,奖励矿工(我们) 1 个币
- 通过将它添加到链上而打造一个新区块
import hashlib
import json
from time import time
from uuid import uuid4
from flask import Flask, jsonify, request
...
@app.route('/mine', methods=['GET'])
def mine():
# We run the proof of work algorithm to get the next proof...
last_block = blockchain.last_block
last_proof = last_block['proof']
proof = blockchain.proof_of_work(last_proof)
# We must receive a reward for finding the proof.
# The sender is "0" to signify that this node has mined a new coin.
blockchain.new_transaction(
sender="0",
recipient=node_identifier,
amount=1,
)
# Forge the new Block by adding it to the chain
previous_hash = blockchain.hash(last_block)
block = blockchain.new_block(proof, previous_hash)
response = {
'message': "New Block Forged",
'index': block['index'],
'transactions': block['transactions'],
'proof': block['proof'],
'previous_hash': block['previous_hash'],
}
return jsonify(response), 200
注意,挖掘出的区块的接收方是我们的节点地址。现在,我们所做的大部分工作都只是与我们的 Blockchain 类的方法进行交互的。到目前为止,我们已经做完了,现在开始与我们的区块链去交互。
第 3 步:与我们的区块链去交互
你可以使用简单的 cURL 或者 Postman 通过网络与我们的 API 去交互。
启动服务器:
$ python blockchain.py
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
我们通过生成一个 GET 请求到 http://localhost:5000/mine 去尝试挖一个区块:
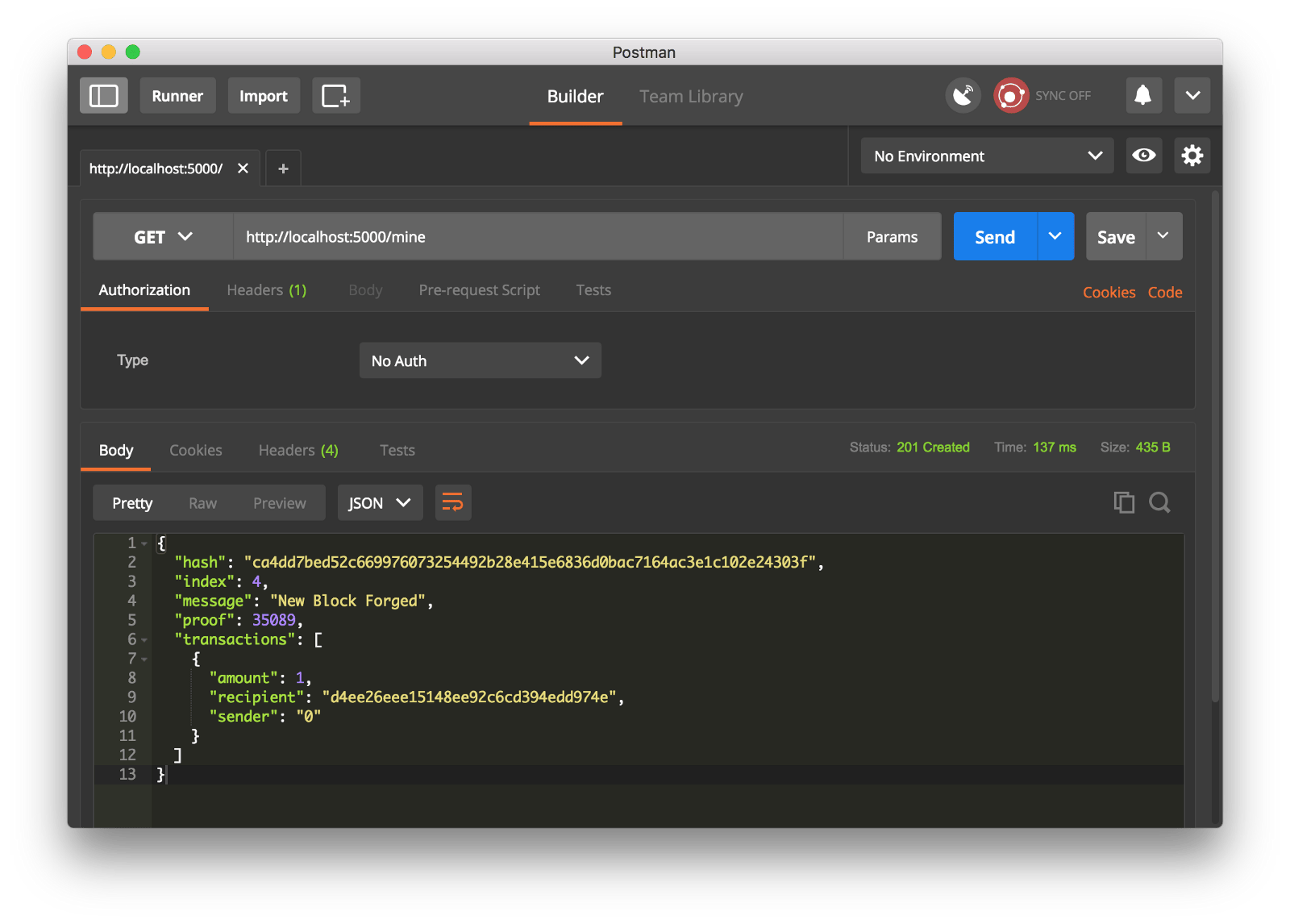
使用 Postman 去生成一个 GET 请求
我们通过生成一个 POST 请求到 http://localhost:5000/transactions/new 去创建一个区块,请求数据包含我们的交易结构:
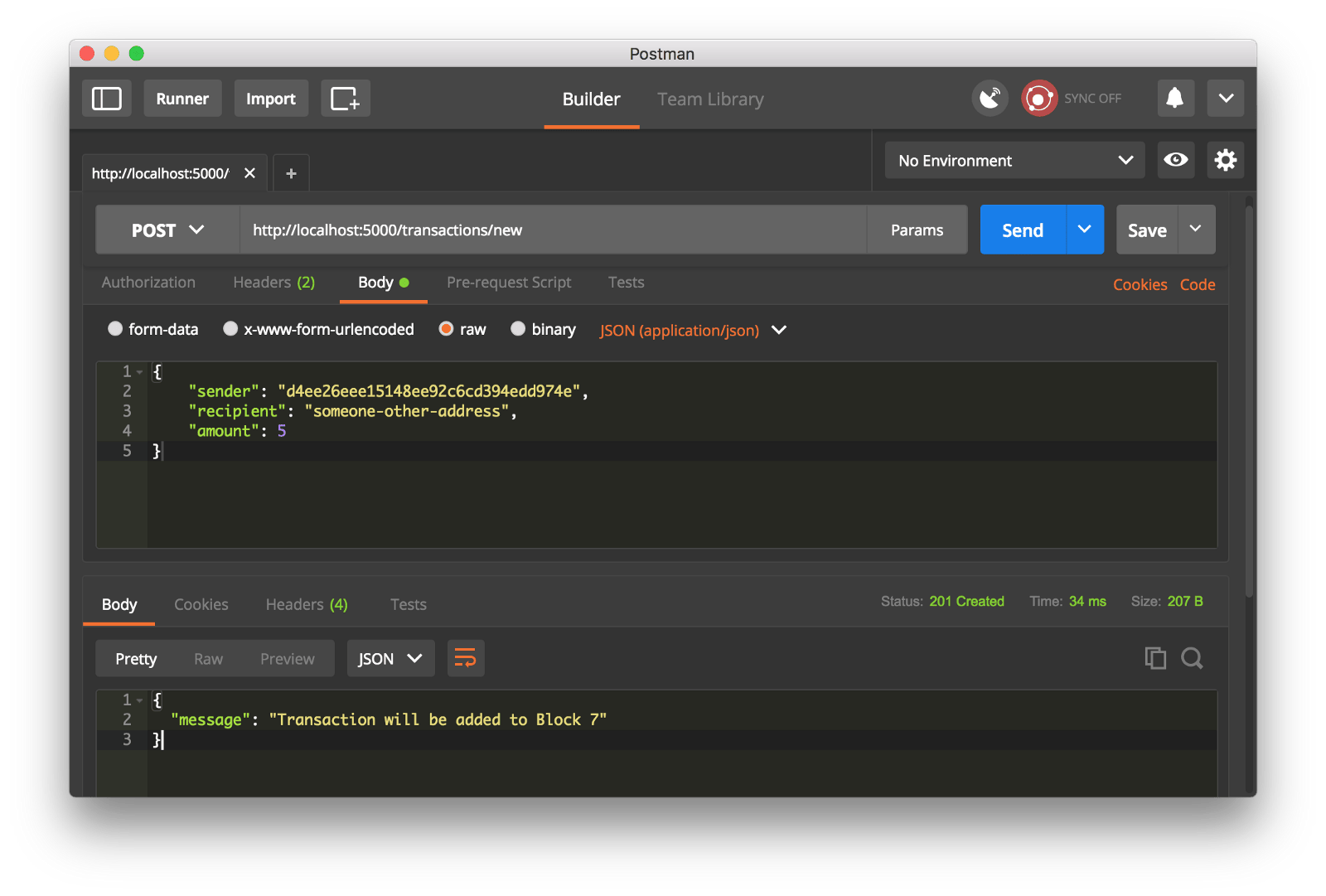
使用 Postman 去生成一个 POST 请求
如果你不使用 Postman,也可以使用 cURL 去生成一个等价的请求:
$ curl -X POST -H "Content-Type: application/json" -d '{
"sender": "d4ee26eee15148ee92c6cd394edd974e",
"recipient": "someone-other-address",
"amount": 5
}' "http://localhost:5000/transactions/new"
我重启动我的服务器,然后我挖到了两个区块,这样总共有了 3 个区块。我们通过请求 http://localhost:5000/chain 来检查整个区块链:
{
"chain": [
{
"index": 1,
"previous_hash": 1,
"proof": 100,
"timestamp": 1506280650.770839,
"transactions": []
},
{
"index": 2,
"previous_hash": "c099bc...bfb7",
"proof": 35293,
"timestamp": 1506280664.717925,
"transactions": [
{
"amount": 1,
"recipient": "8bbcb347e0634905b0cac7955bae152b",
"sender": "0"
}
]
},
{
"index": 3,
"previous_hash": "eff91a...10f2",
"proof": 35089,
"timestamp": 1506280666.1086972,
"transactions": [
{
"amount": 1,
"recipient": "8bbcb347e0634905b0cac7955bae152b",
"sender": "0"
}
]
}
],
"length": 3
}
第 4 步:共识
这是很酷的一个地方。我们已经有了一个基本的区块链,它可以接收交易并允许我们去挖掘出新区块。但是区块链的整个重点在于它是 去中心化的 。而如果它们是去中心化的,那我们如何才能确保它们表示在同一个区块链上?这就是 共识 问题,如果我们希望在我们的网络上有多于一个的节点运行,那么我们将必须去实现一个共识算法。
注册新节点
在我们能实现一个共识算法之前,我们需要一个办法去让一个节点知道网络上的邻居节点。我们网络上的每个节点都保留有一个该网络上其它节点的注册信息。因此,我们需要更多的端点:
/nodes/register 以 URL 的形式去接受一个新节点列表/nodes/resolve 去实现我们的共识算法,由它来解决任何的冲突 —— 确保节点有一个正确的链。
我们需要去修改我们的区块链的构造函数,来提供一个注册节点的方法:
...
from urllib.parse import urlparse
...
class Blockchain(object):
def __init__(self):
...
self.nodes = set()
...
def register_node(self, address):
"""
Add a new node to the list of nodes
:param address: <str> Address of node. Eg. 'http://192.168.0.5:5000'
:return: None
"""
parsed_url = urlparse(address)
self.nodes.add(parsed_url.netloc)
一个添加邻居节点到我们的网络的方法
注意,我们将使用一个 set() 去保存节点列表。这是一个非常合算的方式,它将确保添加的节点是 幂等 的 —— 这意味着不论你将特定的节点添加多少次,它都是精确地只出现一次。
实现共识算法
正如前面提到的,当一个节点与另一个节点有不同的链时就会产生冲突。为解决冲突,我们制定一个规则,即最长的有效的链才是权威的链。换句话说就是,网络上最长的链就是事实上的区块链。使用这个算法,可以在我们的网络上节点之间达到共识。
...
import requests
class Blockchain(object)
...
def valid_chain(self, chain):
"""
Determine if a given blockchain is valid
:param chain: <list> A blockchain
:return: <bool> True if valid, False if not
"""
last_block = chain[0]
current_index = 1
while current_index < len(chain):
block = chain[current_index]
print(f'{last_block}')
print(f'{block}')
print("\n-----------\n")
# Check that the hash of the block is correct
if block['previous_hash'] != self.hash(last_block):
return False
# Check that the Proof of Work is correct
if not self.valid_proof(last_block['proof'], block['proof']):
return False
last_block = block
current_index += 1
return True
def resolve_conflicts(self):
"""
This is our Consensus Algorithm, it resolves conflicts
by replacing our chain with the longest one in the network.
:return: <bool> True if our chain was replaced, False if not
"""
neighbours = self.nodes
new_chain = None
# We're only looking for chains longer than ours
max_length = len(self.chain)
# Grab and verify the chains from all the nodes in our network
for node in neighbours:
response = requests.get(f'http://{node}/chain')
if response.status_code == 200:
length = response.json()['length']
chain = response.json()['chain']
# Check if the length is longer and the chain is valid
if length > max_length and self.valid_chain(chain):
max_length = length
new_chain = chain
# Replace our chain if we discovered a new, valid chain longer than ours
if new_chain:
self.chain = new_chain
return True
return False
第一个方法 valid_chain() 是负责来检查链是否有效,它通过遍历区块链上的每个区块并验证它们的哈希和工作量证明来检查这个区块链是否有效。
resolve_conflicts() 方法用于遍历所有的邻居节点,下载它们的链并使用上面的方法去验证它们是否有效。如果找到有效的链,确定谁是最长的链,然后我们就用最长的链来替换我们的当前的链。
在我们的 API 上来注册两个端点,一个用于添加邻居节点,另一个用于解决冲突:
@app.route('/nodes/register', methods=['POST'])
def register_nodes():
values = request.get_json()
nodes = values.get('nodes')
if nodes is None:
return "Error: Please supply a valid list of nodes", 400
for node in nodes:
blockchain.register_node(node)
response = {
'message': 'New nodes have been added',
'total_nodes': list(blockchain.nodes),
}
return jsonify(response), 201
@app.route('/nodes/resolve', methods=['GET'])
def consensus():
replaced = blockchain.resolve_conflicts()
if replaced:
response = {
'message': 'Our chain was replaced',
'new_chain': blockchain.chain
}
else:
response = {
'message': 'Our chain is authoritative',
'chain': blockchain.chain
}
return jsonify(response), 200
这种情况下,如果你愿意,可以使用不同的机器来做,然后在你的网络上启动不同的节点。或者是在同一台机器上使用不同的端口启动另一个进程。我是在我的机器上使用了不同的端口启动了另一个节点,并将它注册到了当前的节点上。因此,我现在有了两个节点:http://localhost:5000 和 http://localhost:5001。
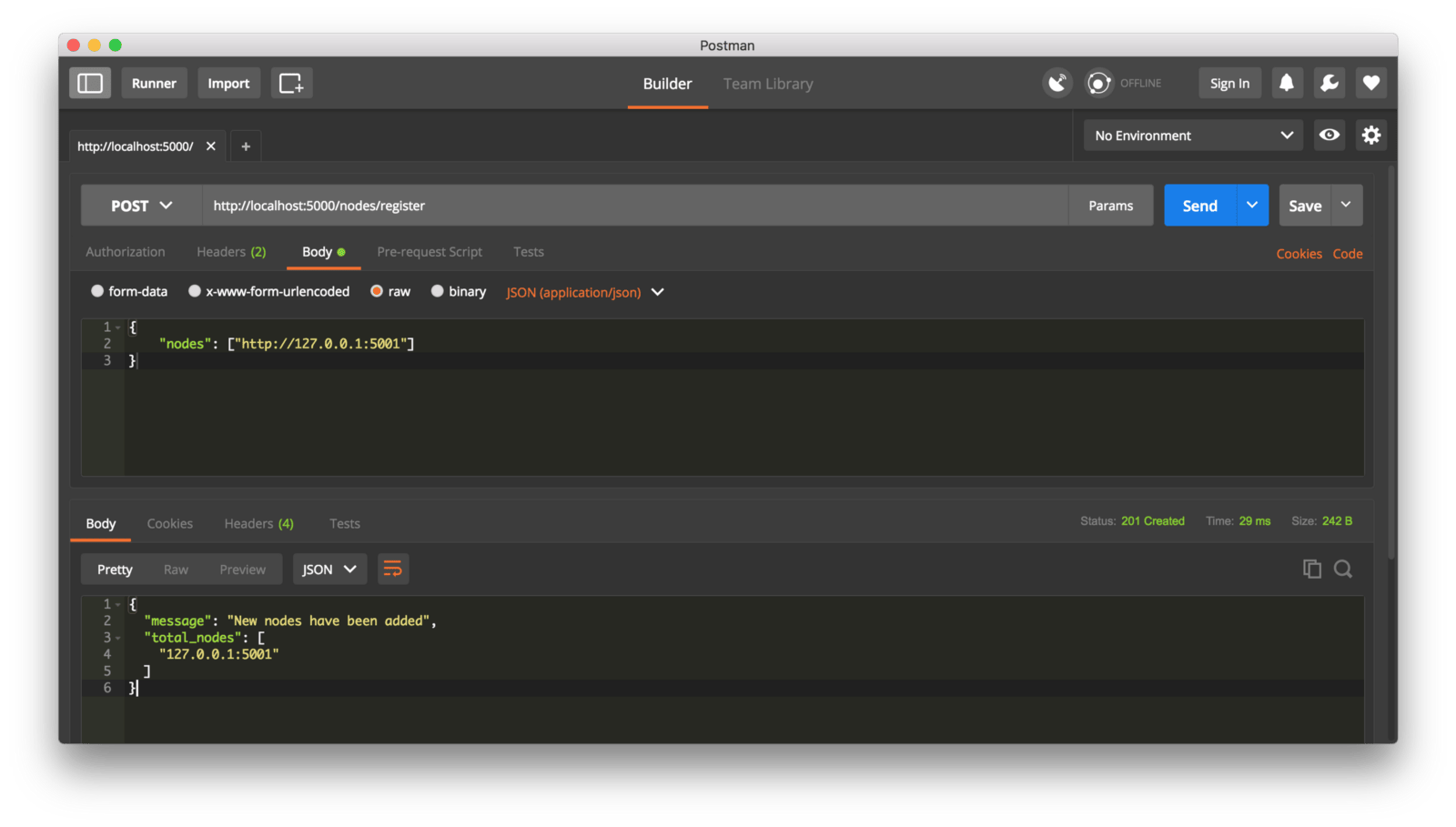
注册一个新节点
我接着在节点 2 上挖出一些新区块,以确保这个链是最长的。之后我在节点 1 上以 GET 方式调用了 /nodes/resolve,这时,节点 1 上的链被共识算法替换成节点 2 上的链了:
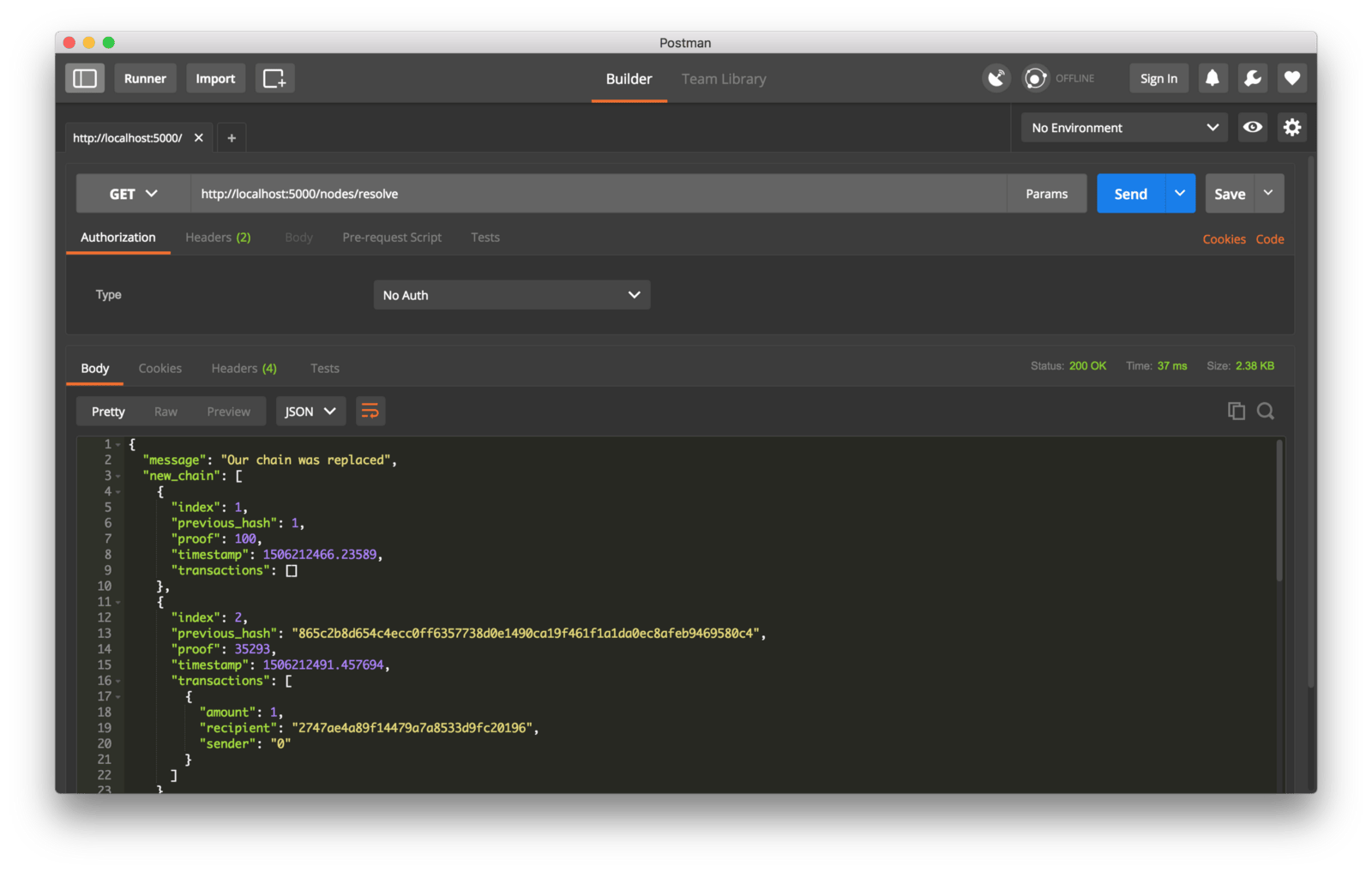
工作中的共识算法
然后将它们封装起来 … 找一些朋友来帮你一起测试你的区块链。
我希望以上内容能够鼓舞你去创建一些新的东西。我是加密货币的狂热拥护者,因此我相信区块链将迅速改变我们对经济、政府和记录保存的看法。
更新: 我正计划继续它的第二部分,其中我将扩展我们的区块链,使它具备交易验证机制,同时讨论一些你可以在其上产生你自己的区块链的方式。(LCTT 译注:第二篇并没有~!)
via: https://hackernoon.com/learn-blockchains-by-building-one-117428612f46
作者:Daniel van Flymen 译者:qhwdw 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出