JavaScript 框架对比及案例(React、Vue 及 Hyperapp)

在我的上一篇文章中,我试图解释为什么我认为 Hyperapp 是一个 React 或 Vue 的可用替代品,原因是,我发现它易于起步。许多人批评这篇文章,认为它自以为是,并没有给其它框架一个展示自己的机会。因此,在这篇文章中,我将尽可能客观的通过提供一些最小化的例子来比较这三个框架,以展示它们的能力。
耳熟能详的计时器例子
计时器可能是响应式编程中最常用的例子之一,极其易于理解:
- 你需要一个变量
count保持对计数器的追踪。 - 你需要两个方法来增加或减少
count变量的值。 - 你需要一种方法来渲染
count变量,并将其呈现给用户。 - 你需要挂载到这两个方法上的两个按钮,以便在用户和它们产生交互时变更
count变量。
下述代码是上述所有三个框架的实现:
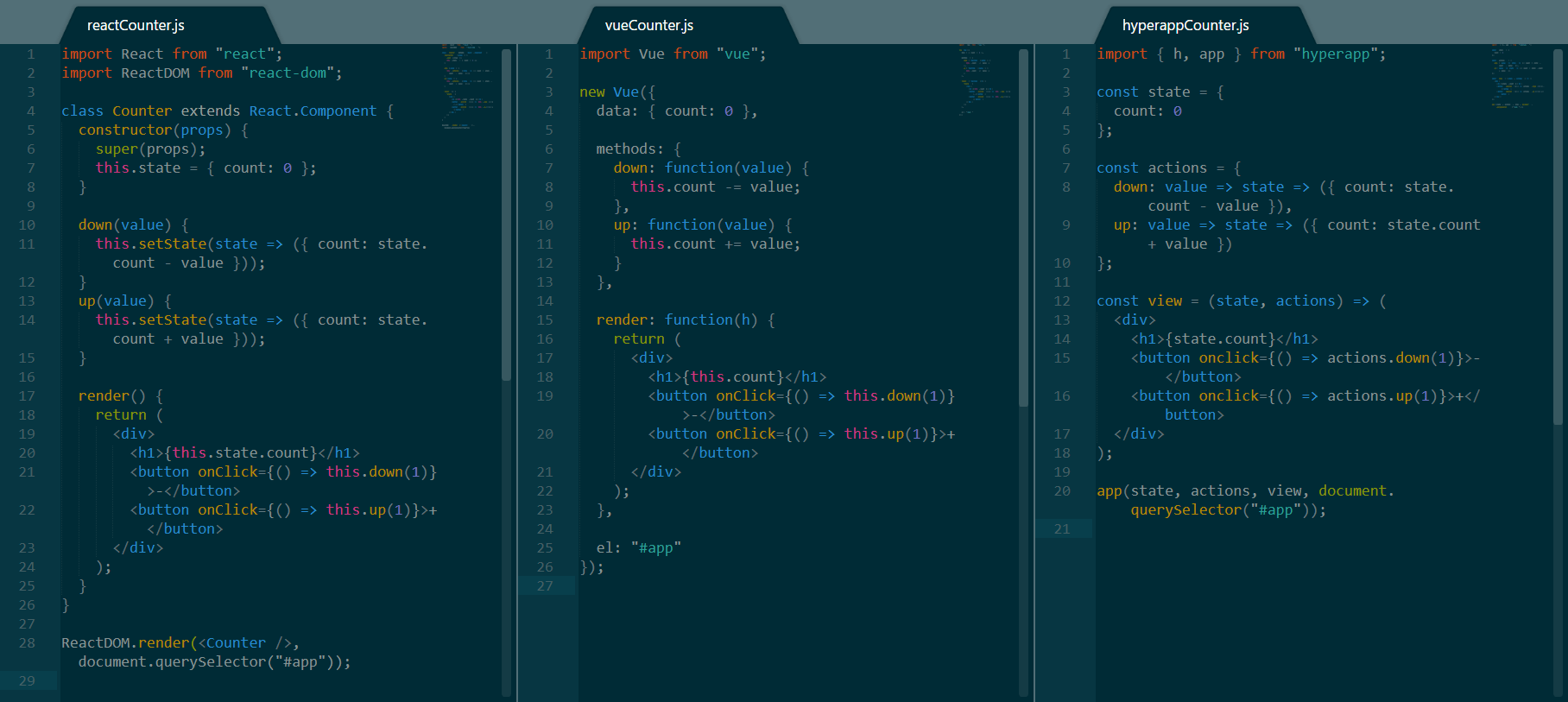
使用 React、Vue 和 Hyperapp 实现的计数器
这里或许会有很多要做的事情,特别是当你并不熟悉其中的一个或多个步骤的时候,因此,我们来一步一步解构这些代码:
- 这三个框架的顶部都有一些
import语句 - React 更推崇面向对象的范式,就是创建一个
Counter组件的class。Vue 遵循类似的范式,通过创建一个新的Vue类的实例并将信息传递给它来实现。最后,Hyperapp 坚持函数范式,同时完全彼此分离view、state和action。 - 就
count变量而言, React 在组件的构造函数内对其进行实例化,而 Vue 和 Hyperapp 则分别是在它们的data和state中设置这些属性。 - 继续看,你可能注意到 React 和 Vue 有相同的方法来与
count变量进行交互。 React 使用继承自React.Component的setState方法来修改它的状态,而 Vue 直接修改this.count。 Hyperapp 使用 ES6 的双箭头语法来实现这个方法,而据我所知,这是唯一一个推荐使用这种语法的框架,React 和 Vue 需要在它们的方法内使用this。另一方面,Hyperapp 的方法需要将状态作为参数,这意味着可以在不同的上下文中重用它们。 - 这三个框架的渲染部分实际上是相同的。唯一的细微差别是 Vue 需要一个函数
h作为参数传递给渲染器,事实上 Hyperapp 使用onclick替代onClick,以及基于每个框架中实现状态的方式引用count变量。 - 最后,所有的三个框架都被挂载到了
#app元素上。每个框架都有稍微不同的语法,Vue 则使用了最直接的语法,通过使用元素选择器而不是使用元素来提供最大的通用性。
计数器案例对比意见
同时比较所有的三个框架,Hyperapp 需要最少的代码来实现计数器,并且它是唯一一个使用函数范式的框架。然而,Vue 的代码在绝对长度上似乎更短一些,元素选择器的挂载方式是一个很好的增强。React 的代码看起来最多,但是并不意味着代码不好理解。
使用异步代码
偶尔你可能需要处理异步代码。最常见的异步操作之一是发送请求给一个 API。为了这个例子的目的,我将使用一个[占位 API] 以及一些假数据来渲染一个文章列表。必须做的事情如下:
- 在状态里保存一个
posts的数组 - 使用一个方法和正确的 URL 来调用
fetch(),等待返回数据,转化为 JSON,并最终使用接收到的数据更新posts变量。 - 渲染一个按钮,这个按钮将调用抓取文章的方法。
- 渲染有主键的
posts列表。
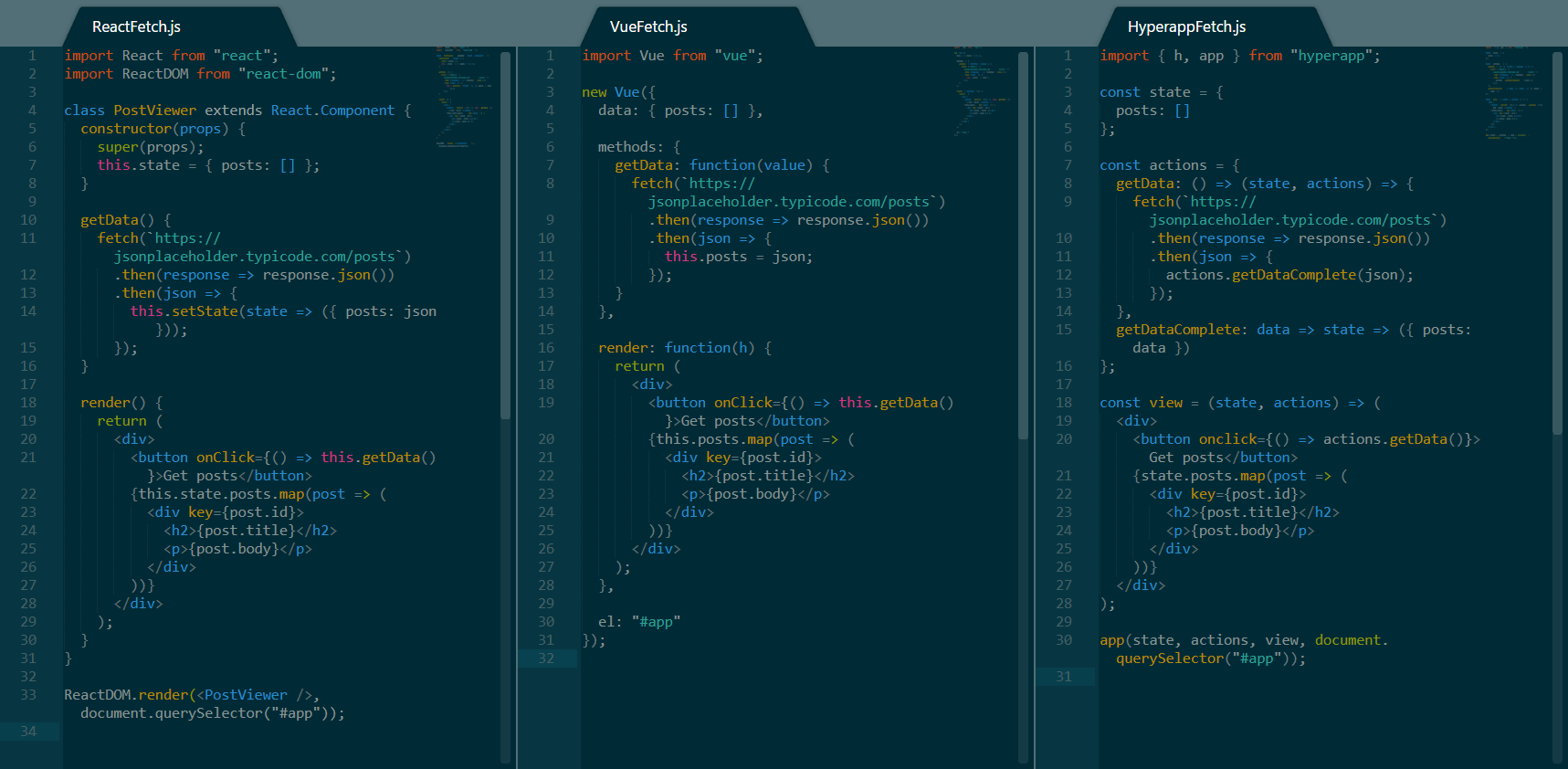
从一个 RESTFul API 抓取数据
让我们分解上面的代码,并比较三个框架:
- 与上面的技术里例子类似,这三个框架之间的存储状态、渲染视图和挂载非常相似。这些差异与上面的讨论相同。
- 在三个框架中使用
fetch()抓取数据都非常简单,并且可以像预期一样工作。然而其中的关键在于, Hyperapp 处理异步操作和其它两种框架有些不同。当数据被接收到并转换为 JSON 时,该操作将调用不同的同步动作以取代直接在异步操作中修改状态。 - 就代码长度而言,Hyperapp 依然只用最少的代码行数实现了相同的结果,但是 Vue 的代码看起来不那么的冗长,同时拥有最少的绝对字符长度。
异步代码对比意见
无论你选择哪种框架,异步操作都非常简单。在应用异步操作时, Hyperapp 可能会迫使你去遵循编写更加函数化和模块化的代码的方式。但是另外两个框架也确实可以做到这一点,并且在这一方面给你提供更多的选择。
To-Do 列表组件案例
在响应式编程中,最出名的例子可能是使用每一个框架里来实现 To-Do 列表。我不打算在这里实现整个部分,我只实现一个无状态的组件,来展示三个框架如何创建更小的可复用的块来协助构建应用程序。
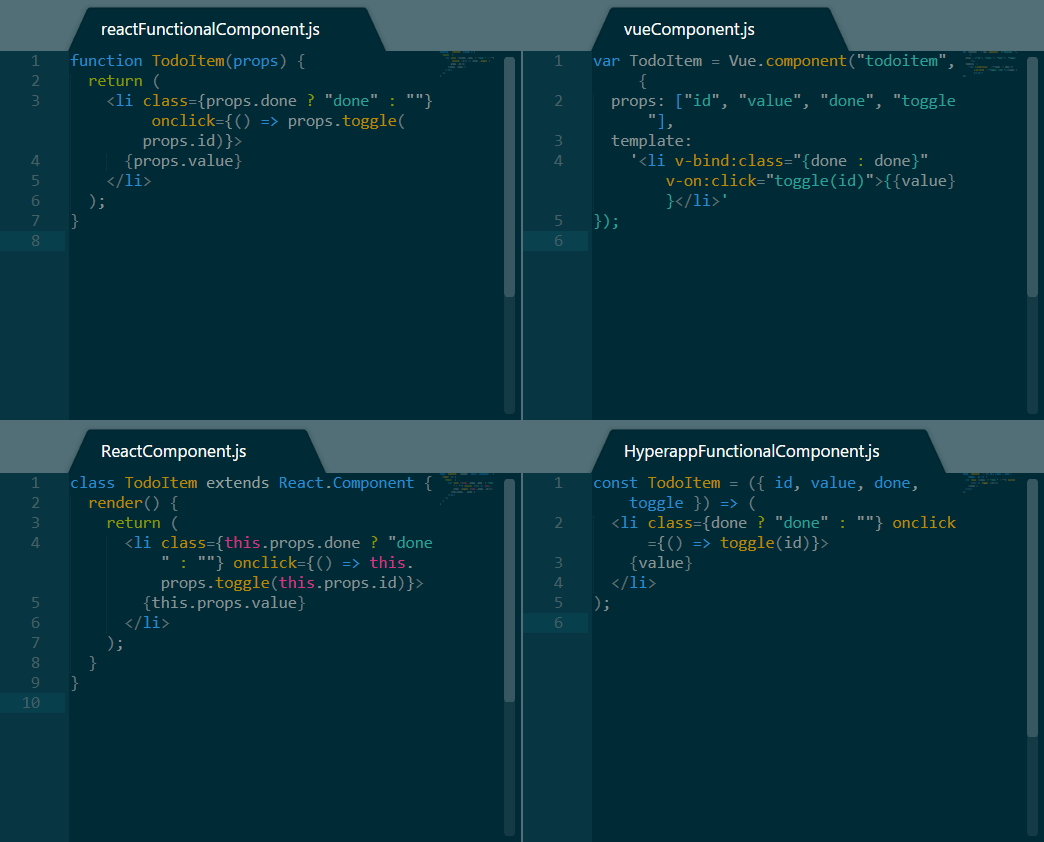
示例 TodoItem 实现
上面的图片展示了每一个框架一个例子,并为 React 提供了一个额外的例子。接下来是我们从它们四个中看到的:
- React 在编程范式上最为灵活。它支持函数组件,也支持类组件。它还支持你在右下角看到的 Hyperapp 组件,无需任何修改。
- Hyperapp 还支持 React 的函数组件实现,这意味着两个框架之间还有很多的实验空间。
- 最后出现的 Vue 有着其合理而又奇怪的语法,即使是对另外两个框架很有经验的人,也不能马上理解其含义。
- 在长度方面,所有的案例代码长度非常相似,在 React 的一些方法中稍微冗长一些。
To-Do 列表项目对比意见
Vue 需要花费一些时间来熟悉,因为它的模板和其它两个框架有一些不同。React 非常的灵活,支持多种不同的方法来创建组件,而 HyperApp 保持一切简单,并提供与 React 的兼容性,以免你希望在某些时刻进行切换。
生命周期方法比较
另一个关键对比是组件的生命周期事件,每一个框架允许你根据你的需要来订阅和处理事件。下面是我根据各框架的 API 参考手册创建的表格:
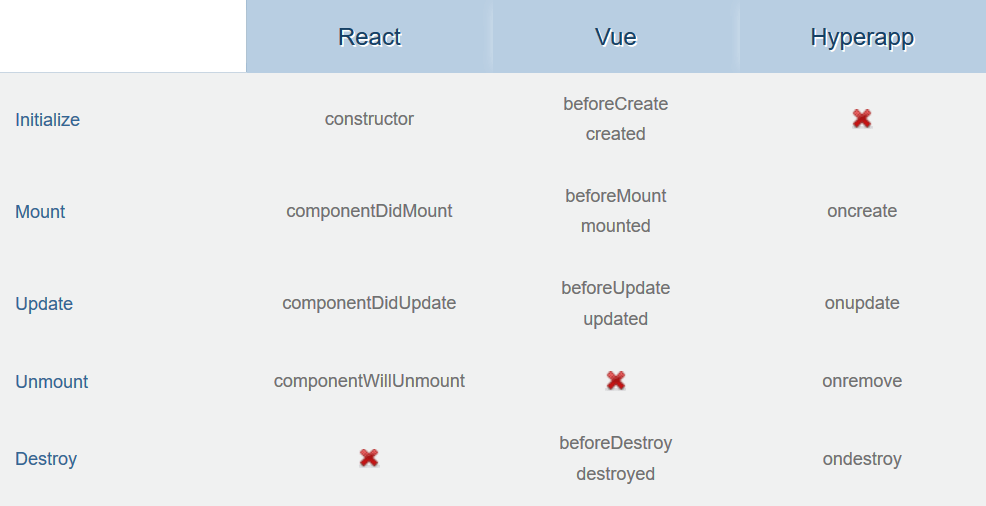
生命周期方式比较
- Vue 提供了最多的生命周期钩子,提供了处理生命周期事件之前或之后发生的任何事件的机会。这能有效帮助管理复杂的组件。
- React 和 Hyperapp 的生命周期钩子非常类似,React 将
unmount和destory绑定在了一起,而 Hyperapp 则将create和mount绑定在了一起。两者在处理生命周期事件方面都提供了相当多的控制。 - Vue 根本没有处理
unmount(据我所理解),而是依赖于destroy事件在组件稍后的生命周期进行处理。 React 不处理destory事件,而是选择只处理unmount事件。最终,HyperApp 不处理create事件,取而代之的是只依赖mount事件。
生命周期对比意见
总的来说,每个框架都提供了生命周期组件,它们帮助你处理组件生命周期中的许多事情。这三个框架都为它们的生命周期提供了钩子,其之间的细微差别,可能源自于实现和方案上的根本差异。通过提供更细粒度的时间处理,Vue 可以更进一步的允许你在开始或结束之后处理生命周期事件。
性能比较
除了易用性和编码技术以外,性能也是大多数开发人员考虑的关键因素,尤其是在进行更复杂的应用程序时。js-framework-benchmark 是一个很好的用于比较框架的工具,所以让我们看看每一组测评数据数组都说了些什么:
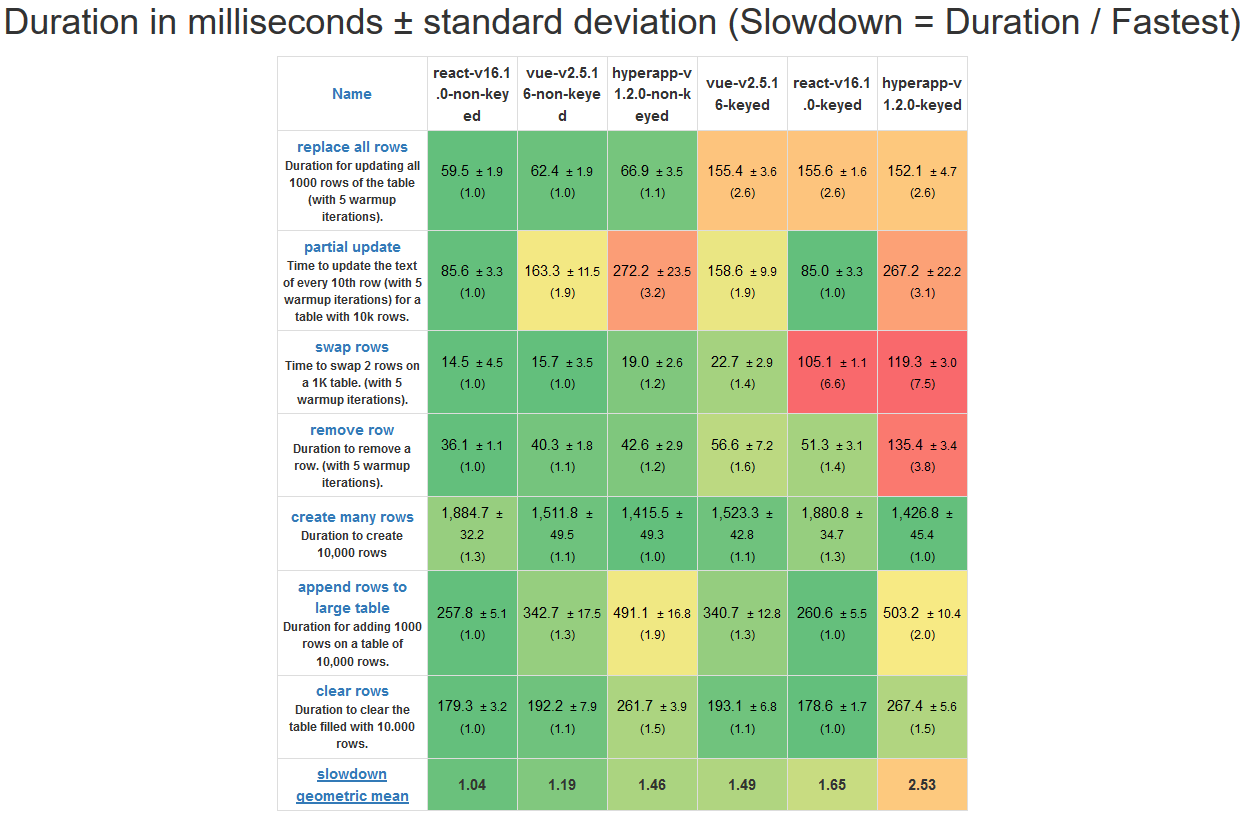
测评操作表
- 与三个框架的有主键操作相比,无主键操作更快。
- 无主键的 React 在所有六种对比中拥有最强的性能,它在所有测试上都有令人深刻的表现。
- 有主键的 Vue 只比有主键的 React 性能稍强,而无主键的 Vue 要比无主键的 React 性能明显差。
- Vue 和 Hyperapp 在进行局部更新的性能测试时遇见了一些问题,与此同时,React 似乎对该问题进行很好的优化。
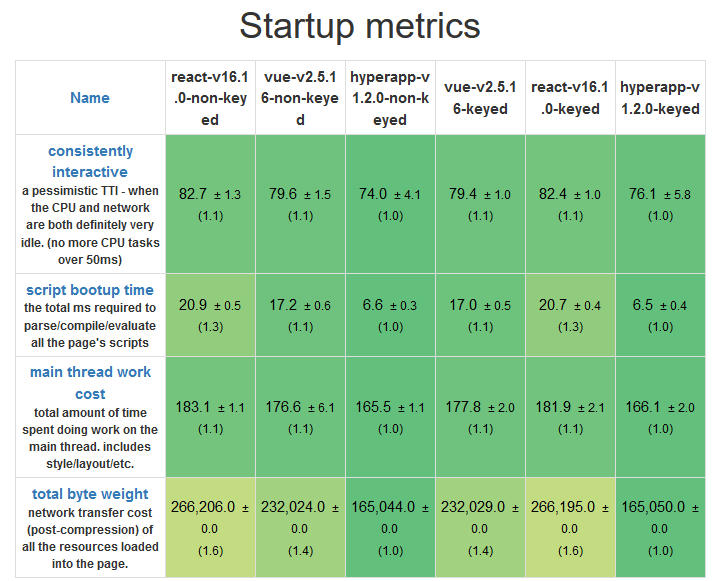
启动测试
- Hyperapp 是三个框架中最轻量的,而 React 和 Vue 有非常小的大小差异。
- Hyperapp 具有最快的启动时间,这得益于它极小的大小和极简的 API
- Vue 在启动上比 React 好一些,但是差异非常小。

内存分配测试
- Hyperapp 是三者中对资源依赖最小的一个,与其它两者相比,任何一个操作都需要更少的内存。
- 资源消耗不是非常高,三者都应该在现代硬件上进行类似的操作。
性能对比意见
如果性能是一个问题,你应该考虑你正在使用什么样的应用程序以及你的需求是什么。看起来 Vue 和 React 用于更复杂的应用程序更好,而 Hyperapp 更适合于更小的应用程序、更少的数据处理和需要快速启动的应用程序,以及需要在低端硬件上工作的应用程序。
但是,要记住,这些测试远不能代表一般场景,所以在现实场景中可能会看到不同的结果。
额外备注
比较 React、Vue 和 Hyperapp 可能像在许多方面比较苹果、橘子。关于这些框架还有一些其它的考虑,它们可以帮助你决定使用另一个框架。
- React 通过引入片段,避免了相邻的 JSX 元素必须封装在父元素中的问题,这些元素允许你将子元素列表分组,而无需向 DOM 添加额外的节点。
- React 还为你提供更高级别的组件,而 VUE 为你提供重用组件功能的 MIXIN。
- Vue 允许使用模板来分离结构和功能,从而更好的分离关注点。
- 与其它两个相比,Hyperapp 感觉像是一个较低级别的 API,它的代码短得多,如果你愿意调整它并学习它的工作原理,那么它可以提供更多的通用性。
结论
我认为如果你已经阅读了这么多,你已经知道哪种工具更适合你的需求。毕竟,这不是讨论哪一个更好,而是讨论哪一个更适合每种情况。总而言之:
- React 是一个非常强大的工具,围绕它有大规模的开发者社区,可能会帮助你找到一个工作。入门并不难,但是掌握它肯定需要很多时间。然而,这是非常值得去花费你的时间全面掌握的。
- 如果你过去曾使用过另外的 JavaScript 框架,Vue 可能看起来有点奇怪,但它也是一个非常有趣的工具。如果 React 不是你所喜欢的,那么它可能是一个可行的、值得学习的选择。它有一些非常酷的内置功能,其社区也在增长中,甚至可能要比 React 增长还要快。
- 最后,Hyperapp 是一个为小型项目而生的很酷的小框架,也是初学者入门的好地方。它提供比 React 或 Vue 更少的工具,但是它能帮助你快速构建原型并理解许多基本原理。你为它编写的许多代码和其它两个框架兼容,要么立即能用,或者是稍做更改就行,你可以在对它们中另外一个有信心时切换框架。
作者简介:
喜欢编码的 Web 开发者,“30 秒编码” ( https://30secondsofcode.org/)和mini.css框架(http://minicss.org ) 的创建者。
via: https://hackernoon.com/javascript-framework-comparison-with-examples-react-vue-hyperapp-97f064fb468d
作者:Angelos Chalaris
译者:Bestony
校对:wxy