昨天,Facebook 发生了由 BGP 引起的离线事故。我对学习更多关于 BGP 的知识已经隐约感兴趣了很长时间,所以我阅读了一些文章。
我感到很沮丧,因为没有一篇文章告诉我如何在我的电脑上实际查找与 BGP 有关的信息,因此我 写了一条询问有关工具的推特。
我一如既往地得到了一堆有用的回复,所以这篇博文展示了一些你可以用来查询 BGP 信息的工具。这篇文章中可能会有较多的错误,因为我对 BGP 不是很了解。
我不能发布 BGP 路由
我从来没有了解过 BGP 的原因之一是,据我所知,我没有在互联网上发布 BGP 路由的权限。
对于大多数网络协议,如果需要,你可以非常轻松地自己实现该协议。例如,你可以:
- 发行你自己的 TLS 证书
- 编写你自己的 HTTP 服务器
- 编写你自己的 TCP 实现
- 为你的域名编写你自己的权威 DNS 服务器(我现在正在为一个小项目尝试这样做)
- 建立你自己的证书机构(CA)
但是对于 BGP,我认为除非你拥有自己的 ASN,否则你不能自己发布路由(你可以在你的家庭网络上实现 BGP,但这对我来说有点无聊,当我做实验的时候,我希望它们真的在真正的互联网上)。
无论如何,尽管我不能用它做实验,但我仍然认为它超级有趣,因为我喜欢网络,所以我将向你展示我找到的一些用来学习 BGP 的工具。
首先我们来谈谈 BGP 的一些术语。我打算很快掠过,因为我对工具更感兴趣,而且网上有很多关于 BGP 的高水平解释(比如这篇 cloudflare 的文章)。
AS 是什么?
我们首先需要了解的是 AS(“ 自治系统 ”)。每个 AS:
- 由一个组织拥有(通常是一个大型组织,如你的 ISP、政府、大学、Facebook 等)。
- 控制一组特定的 IP 地址(例如,我的 ISP 的 AS 包括 247,808 个 IP 地址)。
- 有一个编号 ASN(如 1403)。
下面是我通过做一些实验对 AS 的一些观察:
- 一些相当大的科技公司并没有自己的 AS。例如,我在 BGPView 上查看了 Patreon,就我所知,他们没有自己的 AS,他们的主要网站(
patreon.com,104.16.6.49)在 Cloudflare 的 AS 中。 - 一个 AS 可以包括许多国家的 IP。Facebook 的 AS(AS32934)肯定有新加坡、加拿大、尼日利亚、肯尼亚、美国和其他国家的 IP 地址。
- 似乎 IP 地址可以在一个以上的 AS 中。例如,如果我查找 209.216.230.240,它有 2 个 ASN 与之相关:
AS6130 和 AS21581。显然,当这种情况发生时,更具体的路线会被优先考虑 —— 所以到该 IP 的数据包会被路由到 AS21581。
什么是 BGP 路由?
互联网上有很多的路由器。例如,我的 ISP 就有路由器。
当我给我的 ISP 发送一个数据包时(例如通过运行 ping 129.134.30.0),我的 ISP 的路由器需要弄清楚如何将我的数据包实际送到 IP 地址 129.134.30.0。
路由器计算的方法是,它有一个路由表:这是个有一堆 IP 地址范围的列表(比如 129.134.30.0/23),以及它知道的到达该子网的路由。
下面是一个 129.134.30.0/23 (Facebook 的一个子网)的真实路由的例子。这不是来自我的 ISP。
11670 32934
206.108.35.2 from 206.108.35.254 (206.108.35.254)
Origin IGP, metric 0, valid, external
Community: 3856:55000
Last update: Mon Oct 4 21:17:33 2021
我认为这是在说通往 129.134.30.0 的一条路径是通过机器 206.108.35.2,这是在它的本地网络上。所以路由器接下来可能会把我的 ping 包发送到 206.108.35.2,然后 206.108.35.2 会知道如何把它送到 Facebook。开头的两个数字(11670 32934)是 ASN。
BGP 是什么?
我对 BGP 的理解非常浅薄,它是一个公司用来公布 BGP 路由的协议。
昨天发生在 Facebook 身上的事情基本上是他们发布了一个 BGP 公告,撤销了他们所有的 BGP 路由,所以世界上的每个路由器都删除了所有与 Facebook 有关的路由,没有流量可以到达那里。
好了,现在我们已经涵盖了一些基本的术语,让我们来谈谈你可以用来查看 AS 和 BGP 的工具吧!
工具 1:用 BGPView 查看你的 ISP 的 AS
为了使 AS 这个东西不那么抽象,让我们用一个叫做 BGPView的 工具来看看一个真实的 AS。
我的 ISP(EBOX)拥有 AS 1403。这是 我的 ISP 拥有的 IP 地址。如果我查找我的计算机的公共 IPv4 地址,我可以看到它是我的 ISP 拥有的IP地址之一:它在 104.163.128.0/17 块中。
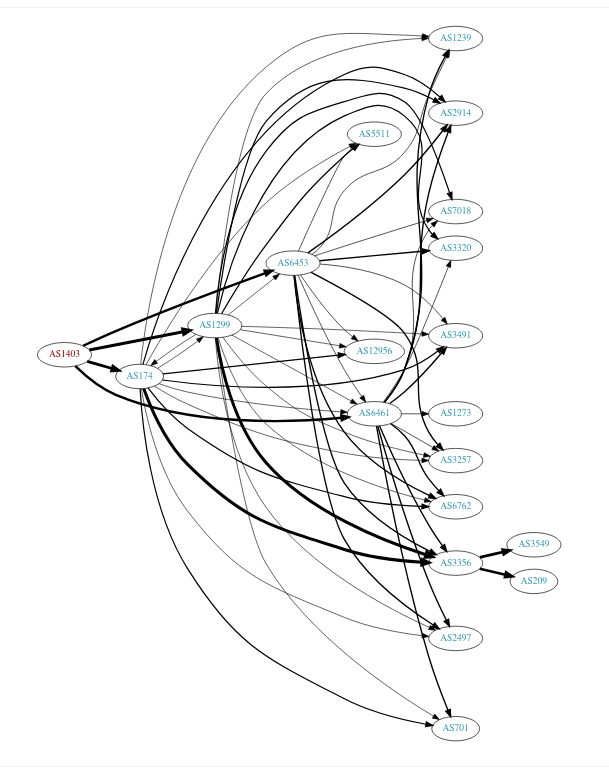
BGPView 也有这个图,显示了我的 ISP 与其他 AS 的连接情况。
工具 2:traceroute -A 和 mtr -z
好了,我们感兴趣的是 AS 。让我们看看我从哪些 AS 中穿过。
traceroute 和 mtr 都有选项可以告诉你每个 IP 的 ASN。其选项分别是 traceroute -A 和 mtr -z。
让我们看看我用 mtr 在去 facebook.com 的路上经过了哪些 AS!
$ mtr -z facebook.com
1. AS??? LEDE.lan
2. AS1403 104-163-190-1.qc.cable.ebox.net
3. AS??? 10.170.192.58
4. AS1403 0.et-5-2-0.er1.mtl7.yul.ebox.ca
5. AS1403 0.ae17.er2.mtl3.yul.ebox.ca
6. AS1403 0.ae0.er1.151fw.yyz.ebox.ca
7. AS??? facebook-a.ip4.torontointernetxchange.net
8. AS32934 po103.psw01.yyz1.tfbnw.net
9. AS32934 157.240.38.75
10. AS32934 edge-star-mini-shv-01-yyz1.facebook.com
这很有意思,看起来我们直接从我的 ISP 的 AS(1403)到 Facebook 的 AS(32934),中间有一个“互联网交换”。
我不确定 互联网交换 (IX)是什么,但我知道它是互联网的一个极其重要的部分。不过这将是以后的事了。我猜是,它是互联网中实现“对等”的部分,就假设它是一个有巨大的交换机的机房,里面有无限的带宽,一堆不同的公司把他们的电脑放在里面,这样他们就可以互相发送数据包。
mtr 用 DNS 查找 ASN
我对 mtr 如何查找 ASN 感到好奇,所以我使用了 strace。我看到它看起来像是在使用 DNS,所以我运行了 dnspeep,然后就看到了!
$ sudo dnspeep
...
TXT 1.190.163.104.origin.asn.cymru.com 192.168.1.1 TXT: 1403 | 104.163.176.0/20 | CA | arin | 2014-08-14, TXT: 1403 | 104.163.160.0/19 | CA | arin | 2014-08-14, TXT: 1403 | 104.163.128.0/17 | CA | arin | 2014-08-14
...
所以,看起来我们可以通过查找 1.190.163.104.origin.asn.cymru.com 上的 txt 记录找到 104.163.190.1 的 ASN,像这样:
$ dig txt 1.190.163.104.origin.asn.cymru.com
1.190.163.104.origin.asn.cymru.com. 13911 IN TXT "1403 | 104.163.160.0/19 | CA | arin | 2014-08-14"
1.190.163.104.origin.asn.cymru.com. 13911 IN TXT "1403 | 104.163.128.0/17 | CA | arin | 2014-08-14"
1.190.163.104.origin.asn.cymru.com. 13911 IN TXT "1403 | 104.163.176.0/20 | CA | arin | 2014-08-14"
这很好!让我们继续前进吧。
工具 3:数据包交换所的观察镜
PCH(“ 数据包交换所 ”)是运行大量互联网交换点的组织。“ 观察镜 ”似乎是一个通用术语,指的是让你从另一个人的计算机上运行网络命令的 Web 表单。有一些观察镜不支持 BGP,但我只对那些能显示 BGP 路由信息的观察镜感兴趣。
这里是 PCH 的观察镜: https://www.pch.net/tools/looking_glass/ 。
在该网站的 Web 表单中,我选择了多伦多 IX(“TORIX”),因为 mtr 说我是用它来访问 facebook.com 的。
操作 1:显示 ip bgp 摘要
下面是输出结果。我修改了其中的一些内容:
IPv4 Unicast Summary:
BGP router identifier 74.80.118.4, local AS number 3856 vrf-id 0
BGP table version 33061919
RIB entries 513241, using 90 MiB of memory
Peers 147, using 3003 KiB of memory
Peer groups 8, using 512 bytes of memory
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
...
206.108.34.248 4 1403 484672 466938 0 0 0 05w3d03h 50
...
206.108.35.2 4 32934 482088 466714 0 0 0 01w6d07h 38
206.108.35.3 4 32934 482019 466475 0 0 0 01w0d06h 38
...
Total number of neighbors 147
我的理解是,多伦多 IX(“TORIX”)直接连接到我的 ISP (EBOX,AS 1403)和 Facebook(AS 32934)。
操作 2:显示 ip bgp 129.134.30.0
这是筛选自 show ip bgp 对 129.134.30.0(Facebook 的一个 IP 地址)的输出:
BGP routing table entry for 129.134.30.0/23
Paths: (4 available, best #4, table default)
Advertised to non peer-group peers:
206.220.231.55
11670 32934
206.108.35.2 from 206.108.35.254 (206.108.35.254)
Origin IGP, metric 0, valid, external
Community: 3856:55000
Last update: Mon Oct 4 21:17:33 2021
11670 32934
206.108.35.2 from 206.108.35.253 (206.108.35.253)
Origin IGP, metric 0, valid, external
Community: 3856:55000
Last update: Mon Oct 4 21:17:31 2021
32934
206.108.35.3 from 206.108.35.3 (157.240.58.225)
Origin IGP, metric 0, valid, external, multipath
Community: 3856:55000
Last update: Mon Oct 4 21:17:27 2021
32934
206.108.35.2 from 206.108.35.2 (157.240.58.182)
Origin IGP, metric 0, valid, external, multipath, best (Older Path)
Community: 3856:55000
Last update: Mon Oct 4 21:17:27 2021
这似乎是在说,从该 IX 到 Facebook 有 4 条路线。
魁北克 IX 似乎对 Facebook 一无所知。
我也试过从魁北克 IX(“QIX”,它可能离我更近,因为我住在蒙特利尔而不是多伦多)做同样的事情。但 QIX 似乎对 Facebook 一无所知:当我输入129.134.30.0 时,它只是说 “% 网络不在表中”。
所以我想这就是为什么我被送到多伦多 IX 而不是魁北克的 IX。
更多的 BGP 观察镜
这里还有一些带观察镜的网站,可以从其他角度给你类似的信息。它们似乎都支持相同的 show ip bgp 语法,也许是因为他们运行的是同一个软件?我不太确定。
似乎有很多这样的观察镜服务,远不止这 3 个列表。
这里有一个与这个列表上的一个服务器进行会话的例子:route-views.routeviews.org。这次我是通过 telnet 连接的,而不是通过 Web 表单,但输出的格式看起来是一样的。
$ telnet route-views.routeviews.org
route-views>show ip bgp 31.13.80.36
BGP routing table entry for 31.13.80.0/24, version 1053404087
Paths: (23 available, best #2, table default)
Not advertised to any peer
Refresh Epoch 1
3267 1299 32934
194.85.40.15 from 194.85.40.15 (185.141.126.1)
Origin IGP, metric 0, localpref 100, valid, external
path 7FE0C3340190 RPKI State valid
rx pathid: 0, tx pathid: 0
Refresh Epoch 1
6939 32934
64.71.137.241 from 64.71.137.241 (216.218.252.164)
Origin IGP, localpref 100, valid, external, best
path 7FE135DB6500 RPKI State valid
rx pathid: 0, tx pathid: 0x0
Refresh Epoch 1
701 174 32934
137.39.3.55 from 137.39.3.55 (137.39.3.55)
Origin IGP, localpref 100, valid, external
path 7FE1604D3AF0 RPKI State valid
rx pathid: 0, tx pathid: 0
Refresh Epoch 1
20912 3257 1299 32934
212.66.96.126 from 212.66.96.126 (212.66.96.126)
Origin IGP, localpref 100, valid, external
Community: 3257:8095 3257:30622 3257:50001 3257:53900 3257:53904 20912:65004
path 7FE1195AF140 RPKI State valid
rx pathid: 0, tx pathid: 0
Refresh Epoch 1
7660 2516 1299 32934
203.181.248.168 from 203.181.248.168 (203.181.248.168)
Origin IGP, localpref 100, valid, external
Community: 2516:1030 7660:9001
path 7FE0D195E7D0 RPKI State valid
rx pathid: 0, tx pathid: 0
这里有几个路由的选择:
3267 1299 329346939 32934701 174 3293420912 3257 1299 329347660 2516 1299 32934
我想这些都有不止一个 AS 的原因是,31.13.80.36 是 Facebook 在多伦多的 IP 地址,所以这个服务器(可能在美国西海岸,我不确定)不能直接连接到它,它需要先到另一个 AS。所以所有的路由都有一个或多个 ASN。
最短的是 6939(“Hurricane Electric”),它是一个 “全球互联网骨干”。他们也有自己的 Hurricane Electric 观察镜 页面。
工具 4:BGPlay
到目前为止,所有其他的工具都只是向我们展示了 Facebook 路由的当前状态,其中一切正常,但这第四个工具让我们看到了这个 Facebook BGP 互联网灾难的历史。这是一个 GUI 工具,所以我将包括一堆屏幕截图。
该工具在 https://stat.ripe.net/special/bgplay。我输入了 IP 地址 129.134.30.12(Facebook 的一个 IP),如果你想一起试试。
首先,让我们看看一切出错之前的状态。我点击了在 10 月 4 日 13:11:28 的时间线,得到了这个结果:

我最初发现这很让人不知所措。发生了什么事?但后来有人在推特上指出,下一个要看的地方是点击 Facebook 灾难发生后的时间线(10 月 4 日 18 点 38 分)。

很明显,这张图有问题:所有的 BGP 路线都不见了!哦,不要!
顶部的文字显示了最后一条 Facebook BGP 路由的消失:
Type: W > withdrawal Involving: 129.134.30.0/24
Short description: The route 50869, 25091, 32934 has been withdrawn.
Date and time: 2021-10-04 16:02:33 Collected by: 20-91.206.53.12
如果我再点击“ 快进 ”按钮,我们看到 BGP 路由开始回来了。

第一个宣告的是 137409 32934。但我不认为这实际上是第一个宣布的,在同一秒内有很多路由宣告(在 2021-10-04 21:00:40),我认为 BGPlay 内部的排序是任意的。
如果我再次点击“ 快进 ”按钮,越来越多的路由开始回来,路由开始恢复正常。
我发现在 BGPlay 里看这个故障真的很有趣,尽管一开始界面很混乱。
也许了解一下 BGP 是很重要的?
我在这篇文章的开头说,你不能改变 BGP 路由,但后来我想起在 2016 年或 2017 年,有一个 Telia 路由问题,给我们的工作造成了一些小的网络问题。而当这种情况发生时,了解为什么你的客户无法到达你的网站其实是很有用的,即使它完全不受你控制。当时我不知道这些工具,但我希望能知道!
我认为对于大多数公司来说,应对由其他人的错误 BGP 路由造成的中断,你所能做的就是“什么都不做,等待它得到修复”,但能够\_自信地\_什么都不做是很好的。
一些发布 BGP 路由的方法
如果你想(作为一个业余爱好者)真正发布 BGP 路由,这里有一些评论中的链接:
目前就这些了
我想还有很多 BGP 工具(比如 PCH 有一堆 路由数据的每日快照,看起来很有趣),但这篇文章已经很长了,而且我今天还有其他事情要做。
我对我作为一个普通人可以得到这么多关于 BGP 的信息感到惊讶,我一直认为它是一个“秘密的网络巫师”这样的东西,但显然有各种公共机器,任何人都可以直接 telnet 到它并用来查看路由表!没想到!
via: https://jvns.ca/blog/2021/10/05/tools-to-look-at-bgp-routes/
作者:Julia Evans 选题:lujun9972 译者:wxy 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出