在 GitLab 我们是如何扩展数据库的

在扩展 GitLab 数据库和我们应用的解决方案,去帮助解决我们的数据库设置中的问题时,我们深入分析了所面临的挑战。
很长时间以来 GitLab.com 使用了一个单个的 PostgreSQL 数据库服务器和一个用于灾难恢复的单个复制。在 GitLab.com 最初的几年,它工作的还是很好的,但是,随着时间的推移,我们看到这种设置的很多问题,在这篇文章中,我们将带你了解我们在帮助解决 GitLab.com 和 GitLab 实例所在的主机时都做了些什么。
例如,数据库长久处于重压之下, CPU 使用率几乎所有时间都处于 70% 左右。并不是因为我们以最好的方式使用了全部的可用资源,而是因为我们使用了太多的(未经优化的)查询去“冲击”服务器。我们意识到需要去优化设置,这样我们就可以平衡负载,使 GitLab.com 能够更灵活地应对可能出现在主数据库服务器上的任何问题。
在我们使用 PostgreSQL 去跟踪这些问题时,使用了以下的四种技术:
- 优化你的应用程序代码,以使查询更加高效(并且理论上使用了很少的资源)。
- 使用一个连接池去减少必需的数据库连接数量(及相关的资源)。
- 跨多个数据库服务器去平衡负载。
- 分片你的数据库
在过去的两年里,我们一直在积极地优化应用程序代码,但它不是一个完美的解决方案,甚至,如果你改善了性能,当流量也增加时,你还需要去应用其它的几种技术。出于本文的目的,我们将跳过优化应用代码这个特定主题,而专注于其它技术。
连接池
在 PostgreSQL 中,一个连接是通过启动一个操作系统进程来处理的,这反过来又需要大量的资源,更多的连接(及这些进程)将使用你的数据库上的更多的资源。 PostgreSQL 也在 max\_connections 设置中定义了一个强制的最大连接数量。一旦达到这个限制,PostgreSQL 将拒绝新的连接, 比如,下面的图表示的设置:
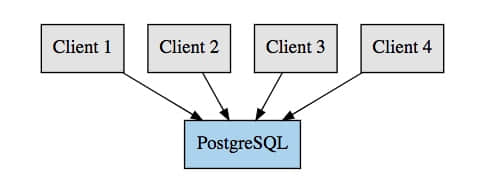
这里我们的客户端直接连接到 PostgreSQL,这样每个客户端请求一个连接。
通过连接池,我们可以有多个客户端侧的连接重复使用一个 PostgreSQL 连接。例如,没有连接池时,我们需要 100 个 PostgreSQL 连接去处理 100 个客户端连接;使用连接池后,我们仅需要 10 个,或者依据我们配置的 PostgreSQL 连接。这意味着我们的连接图表将变成下面看到的那样:
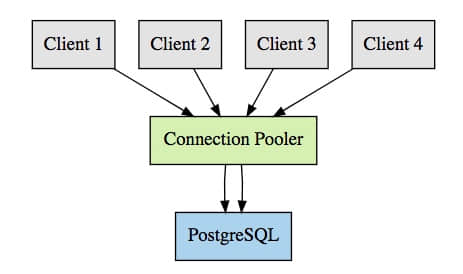
这里我们展示了一个示例,四个客户端连接到 pgbouncer,但不是使用了四个 PostgreSQL 连接,而是仅需要两个。
对于 PostgreSQL 有两个最常用的连接池:
pgpool 有一点特殊,因为它不仅仅是连接池:它有一个内置的查询缓存机制,可以跨多个数据库负载均衡、管理复制等等。
另一个 pgbouncer 是很简单的:它就是一个连接池。
数据库负载均衡
数据库级的负载均衡一般是使用 PostgreSQL 的 “ 热备机 ” 特性来实现的。 热备机是允许你去运行只读 SQL 查询的 PostgreSQL 副本,与不允许运行任何 SQL 查询的普通 备用机 相反。要使用负载均衡,你需要设置一个或多个热备服务器,并且以某些方式去平衡这些跨主机的只读查询,同时将其它操作发送到主服务器上。扩展这样的一个设置是很容易的:(如果需要的话)简单地增加多个热备机以增加只读流量。
这种方法的另一个好处是拥有一个更具弹性的数据库集群。即使主服务器出现问题,仅使用次级服务器也可以继续处理 Web 请求;当然,如果这些请求最终使用主服务器,你可能仍然会遇到错误。
然而,这种方法很难实现。例如,一旦它们包含写操作,事务显然需要在主服务器上运行。此外,在写操作完成之后,我们希望继续使用主服务器一会儿,因为在使用异步复制的时候,热备机服务器上可能还没有这些更改。
分片
分片是水平分割你的数据的行为。这意味着数据保存在特定的服务器上并且使用一个分片键检索。例如,你可以按项目分片数据并且使用项目 ID 做为分片键。当你的写负载很高时,分片数据库是很有用的(除了一个多主设置外,均衡写操作没有其它的简单方法),或者当你有大量的数据并且你不再使用传统方式保存它也是有用的(比如,你不能把它简单地全部放进一个单个磁盘中)。
不幸的是,设置分片数据库是一个任务量很大的过程,甚至,在我们使用诸如 Citus 的软件时也是这样。你不仅需要设置基础设施 (不同的复杂程序取决于是你运行在你自己的数据中心还是托管主机的解决方案),你还得需要调整你的应用程序中很大的一部分去支持分片。
反对分片的案例
在 GitLab.com 上一般情况下写负载是非常低的,同时大多数的查询都是只读查询。在极端情况下,尖峰值达到每秒 1500 元组写入,但是,在大多数情况下不超过每秒 200 元组写入。另一方面,我们可以在任何给定的次级服务器上轻松达到每秒 1000 万元组读取。
存储方面,我们也不使用太多的数据:大约 800 GB。这些数据中的很大一部分是在后台迁移的,这些数据一经迁移后,我们的数据库收缩的相当多。
接下来的工作量就是调整应用程序,以便于所有查询都可以正确地使用分片键。 我们的一些查询包含了一个项目 ID,它是我们使用的分片键,也有许多查询没有包含这个分片键。分片也会影响提交到 GitLab 的改变内容的过程,每个提交者现在必须确保在他们的查询中包含分片键。
最后,是完成这些工作所需要的基础设施。服务器已经完成设置,监视也添加了、工程师们必须培训,以便于他们熟悉上面列出的这些新的设置。虽然托管解决方案可能不需要你自己管理服务器,但它不能解决所有问题。工程师们仍然需要去培训(很可能非常昂贵)并需要为此支付账单。在 GitLab 上,我们也非常乐意提供我们用过的这些工具,这样社区就可以使用它们。这意味着如果我们去分片数据库, 我们将在我们的 Omnibus 包中提供它(或至少是其中的一部分)。确保你提供的服务的唯一方法就是你自己去管理它,这意味着我们不能使用主机托管的解决方案。
最终,我们决定不使用数据库分片,因为它是昂贵的、费时的、复杂的解决方案。
GitLab 的连接池
对于连接池我们有两个主要的诉求:
- 它必须工作的很好(很显然这是必需的)。
- 它必须易于在我们的 Omnibus 包中运用,以便于我们的用户也可以从连接池中得到好处。
用下面两步去评估这两个解决方案(pgpool 和 pgbouncer):
- 执行各种技术测试(是否有效,配置是否容易,等等)。
- 找出使用这个解决方案的其它用户的经验,他们遇到了什么问题?怎么去解决的?等等。
pgpool 是我们考察的第一个解决方案,主要是因为它提供的很多特性看起来很有吸引力。我们其中的一些测试数据可以在 这里 找到。
最终,基于多个因素,我们决定不使用 pgpool 。例如, pgpool 不支持 粘连接 。 当执行一个写入并(尝试)立即显示结果时,它会出现问题。想像一下,创建一个 工单 并立即重定向到这个页面, 没有想到会出现 HTTP 404,这是因为任何用于只读查询的服务器还没有收到数据。针对这种情况的一种解决办法是使用同步复制,但这会给表带来更多的其它问题,而我们希望避免这些问题。
另一个问题是, pgpool 的负载均衡逻辑与你的应用程序是不相干的,是通过解析 SQL 查询并将它们发送到正确的服务器。因为这发生在你的应用程序之外,你几乎无法控制查询运行在哪里。这实际上对某些人也可能是有好处的, 因为你不需要额外的应用程序逻辑。但是,它也妨碍了你在需要的情况下调整路由逻辑。
由于配置选项非常多,配置 pgpool 也是很困难的。或许促使我们最终决定不使用它的原因是我们从过去使用过它的那些人中得到的反馈。即使是在大多数的案例都不是很详细的情况下,我们收到的反馈对 pgpool 通常都持有负面的观点。虽然出现的报怨大多数都与早期版本的 pgpool 有关,但仍然让我们怀疑使用它是否是个正确的选择。
结合上面描述的问题和反馈,最终我们决定不使用 pgpool 而是使用 pgbouncer 。我们用 pgbouncer 执行了一套类似的测试,并且对它的结果是非常满意的。它非常容易配置(而且一开始不需要很多的配置),运用相对容易,仅专注于连接池(而且它真的很好),而且没有明显的负载开销(如果有的话)。也许我唯一的报怨是,pgbouncer 的网站有点难以导航。
使用 pgbouncer 后,通过使用 事务池 我们可以将活动的 PostgreSQL 连接数从几百个降到仅 10 - 20 个。我们选择事务池是因为 Rails 数据库连接是持久的。这个设置中,使用 会话池 不能让我们降低 PostgreSQL 连接数,从而受益(如果有的话)。通过使用事务池,我们可以调低 PostgreSQL 的 max_connections 的设置值,从 3000 (这个特定值的原因我们也不清楚) 到 300 。这样配置的 pgbouncer ,即使在尖峰时,我们也仅需要 200 个连接,这为我们提供了一些额外连接的空间,如 psql 控制台和维护任务。
对于使用事务池的负面影响方面,你不能使用预处理语句,因为 PREPARE 和 EXECUTE 命令也许最终在不同的连接中运行,从而产生错误的结果。 幸运的是,当我们禁用了预处理语句时,并没有测量到任何响应时间的增加,但是我们 确定 测量到在我们的数据库服务器上内存使用减少了大约 20 GB。
为确保我们的 web 请求和后台作业都有可用连接,我们设置了两个独立的池: 一个有 150 个连接的后台进程连接池,和一个有 50 个连接的 web 请求连接池。对于 web 连接需要的请求,我们很少超过 20 个,但是,对于后台进程,由于在 GitLab.com 上后台运行着大量的进程,我们的尖峰值可以很容易达到 100 个连接。
今天,我们提供 pgbouncer 作为 GitLab EE 高可用包的一部分。对于更多的信息,你可以参考 “Omnibus GitLab PostgreSQL High Availability”。
GitLab 上的数据库负载均衡
使用 pgpool 和它的负载均衡特性,我们需要一些其它的东西去分发负载到多个热备服务器上。
对于(但不限于) Rails 应用程序,它有一个叫 Makara 的库,它实现了负载均衡的逻辑并包含了一个 ActiveRecord 的缺省实现。然而,Makara 也有一些我们认为是有些遗憾的问题。例如,它支持的粘连接是非常有限的:当你使用一个 cookie 和一个固定的 TTL 去执行一个写操作时,连接将粘到主服务器。这意味着,如果复制极大地滞后于 TTL,最终你可能会发现,你的查询运行在一个没有你需要的数据的主机上。
Makara 也需要你做很多配置,如所有的数据库主机和它们的角色,没有服务发现机制(我们当前的解决方案也不支持它们,即使它是将来计划的)。 Makara 也 似乎不是线程安全的,这是有问题的,因为 Sidekiq (我们使用的后台进程)是多线程的。 最终,我们希望尽可能地去控制负载均衡的逻辑。
除了 Makara 之外 ,还有一个 Octopus ,它也是内置的负载均衡机制。但是 Octopus 是面向分片数据库的,而不仅是均衡只读查询的。因此,最终我们不考虑使用 Octopus。
最终,我们直接在 GitLab EE构建了自己的解决方案。 添加初始实现的 合并请求 可以在 这里找到,尽管一些更改、提升和修复是以后增加的。
我们的解决方案本质上是通过用一个处理查询的路由的代理对象替换 ActiveRecord::Base.connection 。这可以让我们均衡负载尽可能多的查询,甚至,包括不是直接来自我们的代码中的查询。这个代理对象基于调用方式去决定将查询转发到哪个主机, 消除了解析 SQL 查询的需要。
粘连接
粘连接是通过在执行写入时,将当前 PostgreSQL WAL 位置存储到一个指针中实现支持的。在请求即将结束时,指针短期保存在 Redis 中。每个用户提供他自己的 key,因此,一个用户的动作不会导致其他的用户受到影响。下次请求时,我们取得指针,并且与所有的次级服务器进行比较。如果所有的次级服务器都有一个超过我们的指针的 WAL 指针,那么我们知道它们是同步的,我们可以为我们的只读查询安全地使用次级服务器。如果一个或多个次级服务器没有同步,我们将继续使用主服务器直到它们同步。如果 30 秒内没有写入操作,并且所有的次级服务器还没有同步,我们将恢复使用次级服务器,这是为了防止有些人的查询永远运行在主服务器上。
检查一个次级服务器是否就绪十分简单,它在如下的 Gitlab::Database::LoadBalancing::Host#caught_up? 中实现:
def caught_up?(location)
string = connection.quote(location)
query = "SELECT NOT pg_is_in_recovery() OR " \
"pg_xlog_location_diff(pg_last_xlog_replay_location(), #{string}) >= 0 AS result"
row = connection.select_all(query).first
row && row['result'] == 't'
ensure
release_connection
end
这里的大部分代码是运行原生查询(raw queries)和获取结果的标准的 Rails 代码,查询的最有趣的部分如下:
SELECT NOT pg_is_in_recovery()
OR pg_xlog_location_diff(pg_last_xlog_replay_location(), WAL-POINTER) >= 0 AS result"
这里 WAL-POINTER 是 WAL 指针,通过 PostgreSQL 函数 pg_current_xlog_insert_location() 返回的,它是在主服务器上执行的。在上面的代码片断中,该指针作为一个参数传递,然后它被引用或转义,并传递给查询。
使用函数 pg_last_xlog_replay_location() 我们可以取得次级服务器的 WAL 指针,然后,我们可以通过函数 pg_xlog_location_diff() 与我们的主服务器上的指针进行比较。如果结果大于 0 ,我们就可以知道次级服务器是同步的。
当一个次级服务器被提升为主服务器,并且我们的 GitLab 进程还不知道这一点的时候,添加检查 NOT pg_is_in_recovery() 以确保查询不会失败。在这个案例中,主服务器总是与它自己是同步的,所以它简单返回一个 true。
后台进程
我们的后台进程代码 总是 使用主服务器,因为在后台执行的大部分工作都是写入。此外,我们不能可靠地使用一个热备机,因为我们无法知道作业是否在主服务器执行,也因为许多作业并没有直接绑定到用户上。
连接错误
要处理连接错误,比如负载均衡器不会使用一个视作离线的次级服务器,会增加主机上(包括主服务器)的连接错误,将会导致负载均衡器多次重试。这是确保,在遇到偶发的小问题或数据库失败事件时,不会立即显示一个错误页面。当我们在负载均衡器级别上处理 热备机冲突 的问题时,我们最终在次级服务器上启用了 hot_standby_feedback ,这样就解决了热备机冲突的所有问题,而不会对表膨胀造成任何负面影响。
我们使用的过程很简单:对于次级服务器,我们在它们之间用无延迟试了几次。对于主服务器,我们通过使用越来越快的回退尝试几次。
更多信息你可以查看 GitLab EE 上的源代码:
- https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing.rb
- https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing
数据库负载均衡首次引入是在 GitLab 9.0 中,并且 仅 支持 PostgreSQL。更多信息可以在 9.0 release post 和 documentation 中找到。
Crunchy Data
我们与 Crunchy Data 一起协同工作来部署连接池和负载均衡。不久之前我还是唯一的 数据库专家,它意味着我有很多工作要做。此外,我对 PostgreSQL 的内部细节的和它大量的设置所知有限 (或者至少现在是),这意味着我能做的也有限。因为这些原因,我们雇用了 Crunchy 去帮我们找出问题、研究慢查询、建议模式优化、优化 PostgreSQL 设置等等。
在合作期间,大部分工作都是在相互信任的基础上完成的,因此,我们共享私人数据,比如日志。在合作结束时,我们从一些资料和公开的内容中删除了敏感数据,主要的资料在 gitlab-com/infrastructure#1448,这又反过来导致产生和解决了许多分立的问题。
这次合作的好处是巨大的,它帮助我们发现并解决了许多的问题,如果必须我们自己来做的话,我们可能需要花上几个月的时间来识别和解决它。
幸运的是,最近我们成功地雇佣了我们的 第二个数据库专家 并且我们希望以后我们的团队能够发展壮大。
整合连接池和数据库负载均衡
整合连接池和数据库负载均衡可以让我们去大幅减少运行数据库集群所需要的资源和在分发到热备机上的负载。例如,以前我们的主服务器 CPU 使用率一直徘徊在 70%,现在它一般在 10% 到 20% 之间,而我们的两台热备机服务器则大部分时间在 20% 左右:

在这里, db3.cluster.gitlab.com 是我们的主服务器,而其它的两台是我们的次级服务器。
其它的负载相关的因素,如平均负载、磁盘使用、内存使用也大为改善。例如,主服务器现在的平均负载几乎不会超过 10,而不像以前它一直徘徊在 20 左右:

在业务繁忙期间,我们的次级服务器每秒事务数在 12000 左右(大约为每分钟 740000),而主服务器每秒事务数在 6000 左右(大约每分钟 340000):

可惜的是,在部署 pgbouncer 和我们的数据库负载均衡器之前,我们没有关于事务速率的任何数据。
我们的 PostgreSQL 的最新统计数据的摘要可以在我们的 public Grafana dashboard 上找到。
我们的其中一些 pgbouncer 的设置如下:
| 设置 | 值 |
|---|---|
default_pool_size | 100 |
reserve_pool_size | 5 |
reserve_pool_timeout | 3 |
max_client_conn | 2048 |
pool_mode | transaction |
server_idle_timeout | 30 |
除了前面所说的这些外,还有一些工作要作,比如: 部署服务发现(#2042), 持续改善如何检查次级服务器是否可用(#2866),和忽略落后于主服务器太多的次级服务器 (#2197)。
值得一提的是,到目前为止,我们还没有任何计划将我们的负载均衡解决方案,独立打包成一个你可以在 GitLab 之外使用的库,相反,我们的重点是为 GitLab EE 提供一个可靠的负载均衡解决方案。
如果你对它感兴趣,并喜欢使用数据库、改善应用程序性能、给 GitLab上增加数据库相关的特性(比如: 服务发现),你一定要去查看一下我们的 招聘职位 和 数据库专家手册 去获取更多信息。
via: https://about.gitlab.com/2017/10/02/scaling-the-gitlab-database/
作者:Yorick Peterse 译者:qhwdw 校对:wxy