如何在 Linux 上从 Google Play 商店里下载 apk 文件
假设你想在你的 Android 设备中安装一个 Android 应用,然而由于某些原因,你不能在 Andord 设备上访问 Google Play 商店(LCTT 译注:显然这对于我们来说是常态)。接着你该怎么做呢?在不访问 Google Play 商店的前提下安装应用的一种可能的方法是,使用其他的手段下载该应用的 APK 文件,然后手动地在 Android 设备上 安装 APK 文件。
在非 Android 设备如常规的电脑和笔记本电脑上,有着几种方式来从 Google Play 商店下载到官方的 APK 文件。例如,使用浏览器插件(例如,针对 Chrome 或针对 Firefox 的插件) 或利用允许你使用浏览器下载 APK 文件的在线的 APK 存档等。假如你不信任这些闭源的插件或第三方的 APK 仓库,这里有另一种手动下载官方 APK 文件的方法,它使用一个名为 GooglePlayDownloader 的开源 Linux 应用。
GooglePlayDownloader 是一个基于 Python 的 GUI 应用,它可以让你从 Google Play 商店上搜索和下载 APK 文件。由于它是完全开源的,你可以放心地使用它。在本篇教程中,我将展示如何在 Linux 环境下,使用 GooglePlayDownloader 来从 Google Play 商店下载 APK 文件。
Python 需求
GooglePlayDownloader 需要使用带有 SNI(Server Name Indication 服务器名称指示)的 Python 来支持 SSL/TLS 通信,该功能由 Python 2.7.9 或更高版本引入。这使得一些旧的发行版本如 Debian 7 Wheezy 及早期版本,Ubuntu 14.04 及早期版本或 CentOS/RHEL 7 及早期版本均不能满足该要求。这里假设你已经有了一个带有 Python 2.7.9 或更高版本的发行版本,可以像下面这样接着安装 GooglePlayDownloader。
在 Ubuntu 上安装 GooglePlayDownloader
在 Ubuntu 上,你可以使用官方构建的 deb 包。有一个条件是你可能需要手动地安装一个必需的依赖。
在 Ubuntu 14.10 上
下载 python-ndg-httpsclient deb 软件包,这是一个较旧的 Ubuntu 发行版本中缺失的依赖。同时还要下载 GooglePlayDownloader 的官方 deb 软件包。
$ wget http://mirrors.kernel.org/ubuntu/pool/main/n/ndg-httpsclient/python-ndg-httpsclient_0.3.2-1ubuntu4_all.deb
$ wget http://codingteam.net/project/googleplaydownloader/download/file/googleplaydownloader_1.7-1_all.deb
如下所示,我们将使用 gdebi 命令 来安装这两个 deb 文件。 gedbi 命令将自动地处理任何其他的依赖。
$ sudo apt-get install gdebi-core
$ sudo gdebi python-ndg-httpsclient_0.3.2-1ubuntu4_all.deb
$ sudo gdebi googleplaydownloader_1.7-1_all.deb
在 Ubuntu 15.04 或更新的版本上
最近的 Ubuntu 发行版本上已经配备了所有需要的依赖,所以安装过程可以如下面那样直接进行。
$ wget http://codingteam.net/project/googleplaydownloader/download/file/googleplaydownloader_1.7-1_all.deb
$ sudo apt-get install gdebi-core
$ sudo gdebi googleplaydownloader_1.7-1_all.deb
在 Debian 上安装 GooglePlayDownloader
由于其 Python 需求, Googleplaydownloader 不能被安装到 Debian 7 Wheezy 或早期版本上,除非你升级了它自备的 Python 版本。
在 Debian 8 Jessie 及更高版本上:
$ wget http://codingteam.net/project/googleplaydownloader/download/file/googleplaydownloader_1.7-1_all.deb
$ sudo apt-get install gdebi-core
$ sudo gdebi googleplaydownloader_1.7-1_all.deb
在 Fedora 上安装 GooglePlayDownloader
由于 GooglePlayDownloader 原本是针对基于 Debian 的发行版本所开发的,假如你想在 Fedora 上使用它,你需要从它的源码开始安装。
首先安装必需的依赖。
$ sudo yum install python-pyasn1 wxPython python-ndg_httpsclient protobuf-python python-requests
然后像下面这样安装它。
$ wget http://codingteam.net/project/googleplaydownloader/download/file/googleplaydownloader_1.7.orig.tar.gz
$ tar -xvf googleplaydownloader_1.7.orig.tar.gz
$ cd googleplaydownloader-1.7
$ chmod o+r -R .
$ sudo python setup.py install
$ sudo sh -c "echo 'python /usr/lib/python2.7/site-packages/googleplaydownloader-1.7-py2.7.egg/googleplaydownloader/googleplaydownloader.py' > /usr/bin/googleplaydownloader"
使用 GooglePlayDownloader 从 Google Play 商店下载 APK 文件
一旦你安装好 GooglePlayDownloader 后,你就可以像下面那样从 Google Play 商店下载 APK 文件。(LCTT 译注:显然你需要让你的 Linux 能爬梯子)
首先通过输入下面的命令来启动该应用:
$ googleplaydownloader
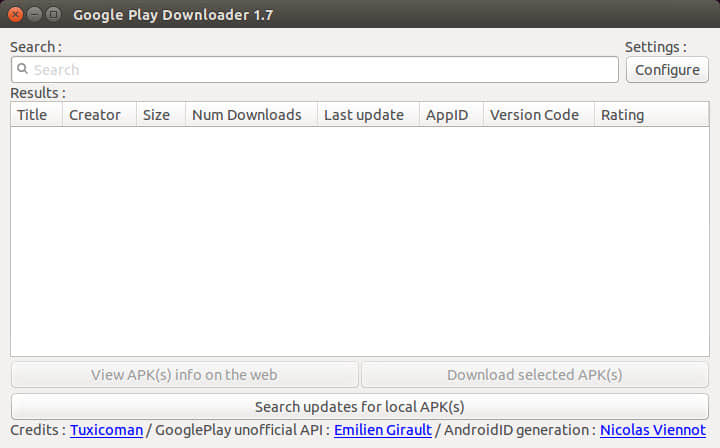
在搜索栏中,输入你想从 Google Play 商店下载的应用的名称。
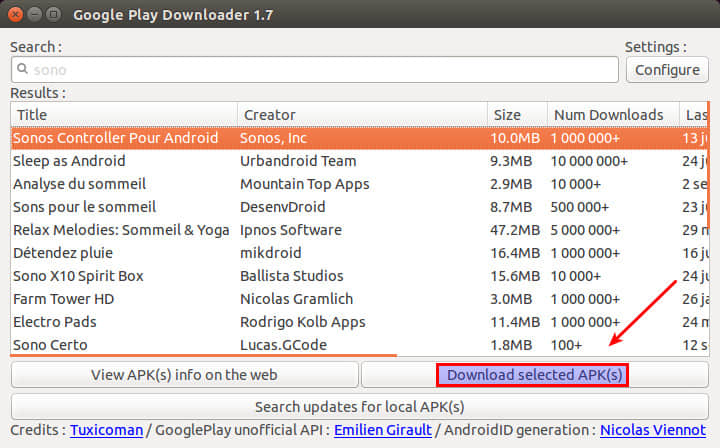
一旦你从搜索列表中找到了该应用,就选择该应用,接着点击 “下载选定的 APK 文件” 按钮。最后你将在你的家目录中找到下载的 APK 文件。现在,你就可以将下载到的 APK 文件转移到你所选择的 Android 设备上,然后手动安装它。
希望这篇教程对你有所帮助。
via: http://xmodulo.com/download-apk-files-google-play-store.html