使用火焰图分析CPU性能回退问题
你能快速定位CPU性能回退的问题么? 如果你的工作环境非常复杂且变化快速,那么使用现有的工具是来定位这类问题是很具有挑战性的。当你花掉数周时间把根因找到时,代码已经又变更了好几轮,新的性能问题又冒了出来。
幸亏有了CPU火焰图(flame graphs),CPU使用率的问题一般都比较好定位。但要处理性能回退问题,就要在修改前后的火焰图之间,不断切换对比,来找出问题所在,这感觉就是像在太阳系中搜寻冥王星。虽然,这种方法可以解决问题,但我觉得应该会有更好的办法。

所以,下面就隆重介绍红/蓝差分火焰图(red/blue differential flame graphs):

上面是一副交互式SVG格式图片(链接)。图中使用了两种颜色来表示状态,红色表示增长,蓝色表示衰减。
这张火焰图中各火焰的形状和大小都是和第二次抓取的profile文件对应的CPU火焰图是相同的。(其中,y轴表示栈的深度,x轴表示样本的总数,栈帧的宽度表示了profile文件中该函数出现的比例,最顶层表示正在运行的函数,再往下就是调用它的栈)
在下面这个案例展示了,在系统升级后,一个工作载荷的CPU使用率上升了。 下面是对应的CPU火焰图(SVG格式)

通常,在标准的火焰图中栈帧和栈塔的颜色是随机选择的。 而在红/蓝差分火焰图中,使用不同的颜色来表示两个profile文件中的差异部分。
在第二个profile中deflate\_slow()函数以及它后续调用的函数运行的次数要比前一次更多,所以在上图中这个栈帧被标为了红色。可以看出问题的原因是ZFS的压缩功能被启用了,而在系统升级前这项功能是关闭的。
这个例子过于简单,我甚至可以不用差分火焰图也能分析出来。但想象一下,如果是在分析一个微小的性能下降,比如说小于5%,而且代码也更加复杂的时候,问题就为那么好处理了。
红/蓝差分火焰图
这个事情我已经讨论了好几年了,最终我自己编写了一个我个人认为有价值的实现。它的工作原理是这样的:
- 抓取修改前的堆栈profile1文件
- 抓取修改后的堆栈profile2文件
- 使用profile2来生成火焰图。(这样栈帧的宽度就是以profile2文件为基准的)
- 使用“2 - 1”的差异来对火焰图重新上色。上色的原则是,如果栈帧在profile2中出现出现的次数更多,则标为红色,否则标为蓝色。色彩是根据修改前后的差异来填充的。
这样做的目的是,同时使用了修改前后的profile文件进行对比,在进行功能验证测试或者评估代码修改对性能的影响时,会非常有用。新的火焰图是基于修改后的profile文件生成(所以栈帧的宽度仍然显示了当前的CPU消耗),通过颜色的对比,就可以了解到系统性能差异的原因。
只有对性能产生直接影响的函数才会标注颜色(比如说,正在运行的函数),它所调用的子函数不会重复标注。
生成红/蓝差分火焰图
我已经把一个简单的代码实现推送到github上(见火焰图),其中新增了一个程序脚本,difffolded.pl。为了展示工具是如何工作的,用Linux perf\_events 来演示一下操作步骤。(你也可以使用其他profiler)
抓取修改前的profile 1文件:
# perf record -F 99 -a -g -- sleep 30
# perf script > out.stacks1
一段时间后 (或者程序代码修改后), 抓取profile 2文件:
# perf record -F 99 -a -g -- sleep 30
# perf script > out.stacks2
现在将 profile 文件进行折叠(fold), 再生成差分火焰图:
$ git clone --depth 1 http://github.com/brendangregg/FlameGraph
$ cd FlameGraph
$ ./stackcollapse-perf.pl ../out.stacks1 > out.folded1
$ ./stackcollapse-perf.pl ../out.stacks2 > out.folded2
$ ./difffolded.pl out.folded1 out.folded2 | ./flamegraph.pl > diff2.svg
difffolded.p只能对“折叠”过的堆栈profile文件进行操作,折叠操作是由前面的stackcollapse系列脚本完成的。(见链接火焰图)。 脚本共输出3列数据,其中一列代表折叠的调用栈,另两列为修改前后profile文件的统计数据。
func_a;func_b;func_c 31 33
[...]
在上面的例子中"funca()->funcb()->func\_c()" 代表调用栈,这个调用栈在profile1文件中共出现了31次,在profile2文件中共出现了33次。然后,使用flamegraph.pl脚本处理这3列数据,会自动生成一张红/蓝差分火焰图。
其他选项
再介绍一些有用的选项:
difffolded.pl -n:这个选项会把两个profile文件中的数据规范化,使其能相互匹配上。如果你不这样做,抓取到所有栈的统计值肯定会不相同,因为抓取的时间和CPU负载都不同。这样的话,看上去要么就是一片红(负载增加),要么就是一片蓝(负载下降)。-n选项对第一个profile文件进行了平衡,这样你就可以得到完整红/蓝图谱。
difffolded.pl -x: 这个选项会把16进制的地址删掉。 profiler时常会无法将地址转换为符号,这样的话栈里就会有16进制地址。如果这个地址在两个profile文件中不同,这两个栈就会认为是不同的栈,而实际上它们是相同的。遇到这样的问题就用-x选项搞定。
flamegraph.pl --negate: 用于颠倒红/蓝配色。 在下面的章节中,会用到这个功能。
不足之处
虽然我的红/蓝差分火焰图很有用,但实际上还是有一个问题:如果一个代码执行路径完全消失了,那么在火焰图中就找不到地方来标注蓝色。你只能看到当前的CPU使用情况,而不知道为什么会变成这样。
一个办法是,将对比顺序颠倒,画一个相反的差分火焰图。例如:

上面的火焰图是以修改前的profile文件为基准,颜色表达了将要发生的情况。右边使用蓝色高亮显示的部分,从中可以看出修改后CPU Idle消耗的CPU时间会变少。(其实,我通常会把cpuidle给过滤掉,使用命令行grep -v cpuidle)
图中把消失的代码也突显了出来(或者应该是说,没有突显),因为修改前并没有使能压缩功能,所以它没有出现在修改前的profile文件了,也就没有了被表为红色的部分。
下面是对应的命令行:
$ ./difffolded.pl out.folded2 out.folded1 | ./flamegraph.pl --negate > diff1.svg
这样,把前面生成diff2.svg一并使用,我们就能得到:
- diff1.svg: 宽度是以修改前profile文件为基准,颜色表明将要发生的情况
- diff2.svg: 宽度是以修改后profile文件为基准,颜色表明已经发生的情况
如果是在做功能验证测试,我会同时生成这两张图。
CPI 火焰图
这些脚本开始是被使用在CPI火焰图的分析上。与比较修改前后的profile文件不同,在分析CPI火焰图时,可以分析CPU工作周期与停顿周期的差异变化,这样可以凸显出CPU的工作状态来。
其他的差分火焰图
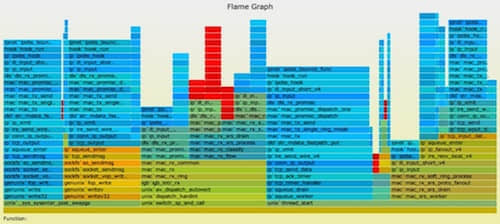
也有其他人做过类似的工作。Robert Mustacchi在不久前也做了一些尝试,他使用的方法类似于代码检视时的标色风格:只显示了差异的部分,红色表示新增(上升)的代码路径,蓝色表示删除(下降)的代码路径。一个关键的差别是栈帧的宽度只体现了差异的样本数。右边是一个例子。这个是个很好的主意,但在实际使用中会感觉有点奇怪,因为缺失了完整profile文件的上下文作为背景,这张图显得有些难以理解。
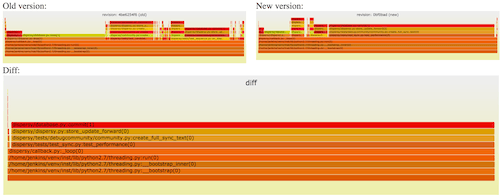
Cor-Paul Bezemer也制作了一种差分显示方法flamegraphdiff,他同时将3张火焰图放在同一张图中,修改前后的标准火焰图各一张,下面再补充了一张差分火焰图,但栈帧宽度也是差异的样本数。 上图是一个例子。在差分图中将鼠标移到栈帧上,3张图中同一栈帧都会被高亮显示。这种方法中补充了两张标准的火焰图,因此解决了上下文的问题。
我们3人的差分火焰图,都各有所长。三者可以结合起来使用:Cor-Paul方法中上方的两张图,可以用我的diff1.svg 和 diff2.svg。下方的火焰图可以用Robert的方式。为保持一致性,下方的火焰图可以用我的着色方式:蓝->白->红。
火焰图正在广泛传播中,现在很多公司都在使用它。如果大家知道有其他的实现差分火焰图的方式,我也不会感到惊讶。(请在评论中告诉我)
结论
如果你遇到了性能回退问题,红/蓝差分火焰图是找到根因的最快方式。这种方式抓取了两张普通的火焰图,然后进行对比,并对差异部分进行标色:红色表示上升,蓝色表示下降。 差分火焰图是以当前(“修改后”)的profile文件作为基准,形状和大小都保持不变。因此你通过色彩的差异就能够很直观的找到差异部分,且可以看出为什么会有这样的差异。
差分火焰图可以应用到项目的每日构建中,这样性能回退的问题就可以及时地被发现和修正。
via: http://www.brendangregg.com/blog/2014-11-09/differential-flame-graphs.html
作者:Brendan Gregg 译者:coloka 校对:wxy