五分钟创建定制 GUI。

对于 .exe 类型的程序文件,我们可以通过双击鼠标左键打开;但对于 .py 类型的 Python 程序,几乎不会有人尝试同样的操作。对于一个(非程序员类型的)典型用户,他们双击打开 .exe 文件时预期弹出一个可以交互的窗体。基于 Tkinter,可以通过 标准 Python 安装 的方式提供 GUI,但很多程序都不太可能这样做。
如果打开 Python 程序并进入 GUI 界面变得如此容易,以至于真正的初学者也可以掌握,会怎样呢?会有人感兴趣并使用吗?这个问题不好回答,因为直到今天创建自定义 GUI 布局仍不是件容易的事情。
在为程序或脚本增加 GUI 这件事上,似乎存在能力的“错配”。(缺乏这方面能力的)真正的初学者被迫只能使用命令行方式,而很多(具备这方面能力的)高级程序员却不愿意花时间创建一个 Tkinter GUI。
GUI 框架
Python 的 GUI 框架并不少,其中 Tkinter,wxPython,Qt 和 Kivy 是几种比较主流的框架。此外,还有不少在上述框架基础上封装的简化框架,例如 EasyGUI,PyGUI 和 Pyforms 等。
但问题在于,对于初学者(这里是指编程经验不超过 6 个月的用户)而言,即使是最简单的主流框架,他们也无从下手;他们也可以选择封装过的(简化)框架,但仍难以甚至无法创建自定义 GUI 布局 。即便学会了某种(简化)框架,也需要编写连篇累牍的代码。
PySimpleGUI 尝试解决上述 GUI 难题,它提供了一种简单明了、易于理解、方便自定义的 GUI 接口。如果使用 PySimpleGUI,很多复杂的 GUI 也仅需不到 20 行代码。
秘诀
PySimpleGUI 极为适合初学者的秘诀在于,它已经包含了绝大多数原本需要用户编写的代码。PySimpleGUI 会处理按钮 回调 ,无需用户编写代码。对于初学者,在几周内掌握函数的概念已经不容易了,要求其理解回调函数似乎有些强人所难。
在大部分 GUI 框架中,布局 GUI 小部件 通常需要写一些代码,每个小部件至少 1-2 行。PySimpleGUI 使用了 “auto-packer” 技术,可以自动创建布局。因而,布局 GUI 窗口不再需要 pack 或 grid 系统。
(LCTT 译注:这里提到的 pack 和 grid 都是 Tkinter 的布局管理器,另外一种叫做 place 。)
最后,PySimpleGUI 框架编写中有效地利用了 Python 语言特性,降低用户代码量并简化 GUI 数据返回的方式。在 窗体 布局中创建小部件时,小部件会被部署到对应的布局中,无需额外的代码。
GUI 是什么?
绝大多数 GUI 只完成一件事情:收集用户数据并返回。在程序员看来,可以归纳为如下的函数调用:
button, values = GUI_Display(gui_layout)
绝大多数 GUI 支持的用户行为包括鼠标点击(例如,“确认”,“取消”,“保存”,“是”和“否”等)和内容输入。GUI 本质上可以归结为一行代码。
这也正是 PySimpleGUI (的简单 GUI 模式)的工作原理。当执行命令显示 GUI 后,除非点击鼠标关闭窗体,否则不会执行任何代码。
当然还有更复杂的 GUI,其中鼠标点击后窗口并不关闭;例如,机器人的远程控制界面,聊天窗口等。这类复杂的窗体也可以用 PySimpleGUI 创建。
快速创建 GUI
PySimpleGUI 什么时候有用呢?显然,是你需要 GUI 的时候。仅需不超过 5 分钟,就可以让你创建并尝试 GUI。最便捷的 GUI 创建方式就是从 PySimpleGUI 经典实例中拷贝一份代码。具体操作流程如下:
- 找到一个与你需求最接近的 GUI
- 从经典实例中拷贝代码
- 粘贴到 IDE 中并运行
下面我们看一下书中的第一个 经典实例 :
import PySimpleGUI as sg
# Very basic form. Return values as a list
form = sg.FlexForm('Simple data entry form') # begin with a blank form
layout = [
[sg.Text('Please enter your Name, Address, Phone')],
[sg.Text('Name', size=(15, 1)), sg.InputText('name')],
[sg.Text('Address', size=(15, 1)), sg.InputText('address')],
[sg.Text('Phone', size=(15, 1)), sg.InputText('phone')],
[sg.Submit(), sg.Cancel()]
]
button, values = form.LayoutAndRead(layout)
print(button, values[0], values[1], values[2])
运行后会打开一个大小适中的窗体。
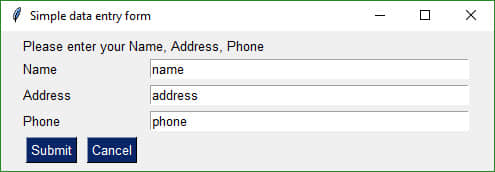
如果你只是想收集一些字符串类型的值,拷贝上述经典实例中的代码,稍作修改即可满足你的需求。
你甚至可以只用 5 行代码创建一个自定义 GUI 布局。
import PySimpleGUI as sg
form = sg.FlexForm('My first GUI')
layout = [ [sg.Text('Enter your name'), sg.InputText()],
[sg.OK()] ]
button, (name,) = form.LayoutAndRead(layout)
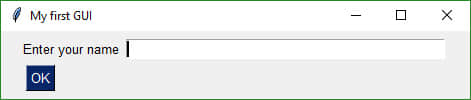
5 分钟内创建一个自定义 GUI
在简单布局的基础上,通过修改经典实例中的代码,5 分钟内即可使用 PySimpleGUI 创建自定义布局。
在 PySimpleGUI 中, 小部件 被称为 元素 。元素的名称与编码中使用的名称保持一致。
(LCTT 译注:Tkinter 中使用小部件这个词)
核心元素
Text
InputText
Multiline
InputCombo
Listbox
Radio
Checkbox
Spin
Output
SimpleButton
RealtimeButton
ReadFormButton
ProgressBar
Image
Slider
Column
元素简写
PySimpleGUI 还包含两种元素简写方式。一种是元素类型名称简写,例如 T 用作 Text 的简写;另一种是元素参数被配置了默认值,你可以无需指定所有参数,例如 Submit 按钮默认的文本就是 “Submit”。
T = Text
Txt = Text
In = InputText
Input = IntputText
Combo = InputCombo
DropDown = InputCombo
Drop = InputCombo
(LCTT 译注:第一种简写就是 Python 类的别名,第二种简写是在返回元素对象的 Python 函数定义时指定了参数的默认值)
按钮简写
一些通用按钮具有简写实现,包括:
FolderBrowse
FileBrowse
FileSaveAs
Save
Submit
OK
Ok (LCTT 译注:这里 `k` 是小写)
Cancel
Quit
Exit
Yes
No
此外,还有通用按钮功能对应的简写:
SimpleButton
ReadFormButton
RealtimeButton
(LCTT 译注:其实就是返回 Button 类实例的函数)
上面就是 PySimpleGUI 支持的全部元素。如果不在上述列表之中,就不会在你的窗口布局中生效。
(LCTT 译注:上述都是 PySimpleGUI 的类名、类别名或返回实例的函数,自然只能使用列表内的。)
GUI 设计模式
对于 GUI 程序,创建并展示窗口的调用大同小异,差异在于元素的布局。
设计模式代码与上面的例子基本一致,只是移除了布局:
import PySimpleGUI as sg
form = sg.FlexForm('Simple data entry form')
# Define your form here (it's a list of lists)
button, values = form.LayoutAndRead(layout)
(LCTT 译注:这段代码无法运行,只是为了说明每个程序都会用到的设计模式。)
对于绝大多数 GUI,编码流程如下:
- 创建窗体对象
- 以“列表的列表”的形式定义 GUI
- 展示 GUI 并获取元素的值
上述流程与 PySimpleGUI 设计模式部分的代码一一对应。
GUI 布局
要创建自定义 GUI,首先要将窗体分割成多个行,因为窗体是一行一行定义的。然后,在每一行中从左到右依次放置元素。
我们得到的就是一个“列表的列表”,类似如下:
layout = [ [Text('Row 1')],
[Text('Row 2'), Checkbox('Checkbox 1', OK()), Checkbox('Checkbox 2'), OK()] ]
上述布局对应的效果如下:
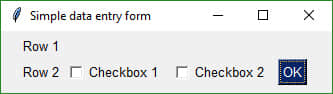
展示 GUI
当你完成布局、拷贝完用于创建和展示窗体的代码后,下一步就是展示窗体并收集用户数据。
下面这行代码用于展示窗体并返回收集的数据:
button, values = form.LayoutAndRead(layout)
窗体返回的结果由两部分组成:一部分是被点击按钮的名称,另一部分是一个列表,包含所有用户输入窗体的值。
在这个例子中,窗体显示后用户直接点击 “OK” 按钮,返回的结果如下:
button == 'OK'
values == [False, False]
Checkbox 类型元素返回 True 或 False 类型的值。由于默认处于未选中状态,两个元素的值都是 False。
显示元素的值
一旦从 GUI 获取返回值,检查返回变量中的值是个不错的想法。与其使用 print 语句进行打印,我们不妨坚持使用 GUI 并在一个窗口中输出这些值。
(LCTT 译注:考虑使用的是 Python 3 版本,print 应该是函数而不是语句。)
在 PySimpleGUI 中,有多种消息框可供选取。传递给消息框(函数)的数据会被显示在消息框中;函数可以接受任意数目的参数,你可以轻松的将所有要查看的变量展示出来。
在 PySimpleGUI 中,最常用的消息框是 MsgBox。要展示上面例子中的数据,只需编写一行代码:
MsgBox('The GUI returned:', button, values)
整合
好了,你已经了解了基础知识,让我们创建一个包含尽可能多 PySimpleGUI 元素的窗体吧!此外,为了更好的感观效果,我们将采用绿色/棕褐色的配色方案。
import PySimpleGUI as sg
sg.ChangeLookAndFeel('GreenTan')
form = sg.FlexForm('Everything bagel', default_element_size=(40, 1))
column1 = [[sg.Text('Column 1', background_color='#d3dfda', justification='center', size=(10,1))],
[sg.Spin(values=('Spin Box 1', '2', '3'), initial_value='Spin Box 1')],
[sg.Spin(values=('Spin Box 1', '2', '3'), initial_value='Spin Box 2')],
[sg.Spin(values=('Spin Box 1', '2', '3'), initial_value='Spin Box 3')]]
layout = [
[sg.Text('All graphic widgets in one form!', size=(30, 1), font=("Helvetica", 25))],
[sg.Text('Here is some text.... and a place to enter text')],
[sg.InputText('This is my text')],
[sg.Checkbox('My first checkbox!'), sg.Checkbox('My second checkbox!', default=True)],
[sg.Radio('My first Radio! ', "RADIO1", default=True), sg.Radio('My second Radio!', "RADIO1")],
[sg.Multiline(default_text='This is the default Text should you decide not to type anything', size=(35, 3)),
sg.Multiline(default_text='A second multi-line', size=(35, 3))],
[sg.InputCombo(('Combobox 1', 'Combobox 2'), size=(20, 3)),
sg.Slider(range=(1, 100), orientation='h', size=(34, 20), default_value=85)],
[sg.Listbox(values=('Listbox 1', 'Listbox 2', 'Listbox 3'), size=(30, 3)),
sg.Slider(range=(1, 100), orientation='v', size=(5, 20), default_value=25),
sg.Slider(range=(1, 100), orientation='v', size=(5, 20), default_value=75),
sg.Slider(range=(1, 100), orientation='v', size=(5, 20), default_value=10),
sg.Column(column1, background_color='#d3dfda')],
[sg.Text('_' * 80)],
[sg.Text('Choose A Folder', size=(35, 1))],
[sg.Text('Your Folder', size=(15, 1), auto_size_text=False, justification='right'),
sg.InputText('Default Folder'), sg.FolderBrowse()],
[sg.Submit(), sg.Cancel()]
]
button, values = form.LayoutAndRead(layout)
sg.MsgBox(button, values)
看上面要写不少代码,但如果你试着直接使用 Tkinter 框架实现同样的 GUI,你很快就会发现 PySimpleGUI 版本的代码是多么的简洁。
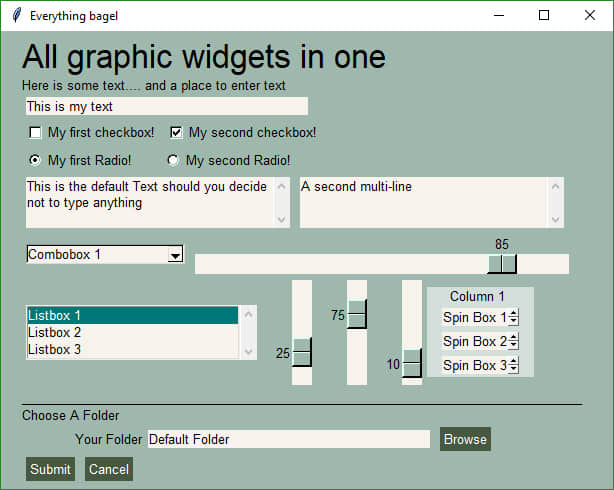
代码的最后一行打开了一个消息框,效果如下:
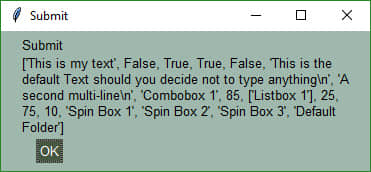
消息框函数中的每一个参数的内容都会被打印到单独的行中。本例的消息框中包含两行,其中第二行非常长而且包含列表嵌套。
建议花一点时间将上述结果与 GUI 中的元素一一比对,这样可以更好的理解这些结果是如何产生的。
为你的程序或脚本添加 GUI
如果你有一个命令行方式使用的脚本,添加 GUI 不一定意味着完全放弃该脚本。一种简单的方案如下:如果脚本不需要命令行参数,那么可以直接使用 GUI 调用该脚本;反之,就按原来的方式运行脚本。
仅需类似如下的逻辑:
if len(sys.argv) == 1:
# collect arguments from GUI
else:
# collect arguements from sys.argv
创建并运行 GUI 最便捷的方式就是从 PySimpleGUI 经典实例中拷贝一份代码并修改。
快来试试吧!给你一直疲于手动执行的脚本增加一些趣味。只需 5-10 分钟即可玩转示例脚本。你可能发现一个几乎满足你需求的经典实例;如果找不到,也很容易自己编写一个。即使你真的玩不转,也只是浪费了 5-10 分钟而已。
资源
安装方式
支持 Tkinter 的系统就支持 PySimpleGUI,甚至包括 树莓派 ,但你需要使用 Python 3。
pip install PySimpleGUI
文档
via: https://opensource.com/article/18/8/pysimplegui
作者:Mike Barnett 选题:lujun9972 译者:pinewall 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出