Rancher:一个全面的可用于产品环境的容器管理平台

Docker 作为一款容器化应用的新兴软件,被大多数 IT 公司使用来减少基础设施平台的成本。
通常,没有 GUI 的 Docker 软件对于 Linux 管理员来说很容易,但是对于开发者来就有点困难。当把它搬到生产环境上来,那么它对 Linux 管理员来说也相当不友好。那么,轻松管理 Docker 的最佳解决方案是什么呢?
唯一的办法就是提供 GUI。Docker API 允许第三方应用接入 Docker。在市场上有许多 Docker GUI 应用。我们已经写过一篇关于 Portainer 应用的文章。今天我们来讨论另一个应用,Rancher。
容器让软件开发更容易,让开发者更快的写代码、更好的运行它们。但是,在生产环境上运行容器却很困难。
推荐阅读: Portainer:一个简单的 Docker 管理图形工具
Rancher 简介
Rancher 是一个全面的容器管理平台,它可以让容器在各种基础设施平台的生产环境上部署和运行更容易。它提供了诸如多主机网络、全局/本地负载均衡和卷快照等基础设施服务。它整合了原生 Docker 的管理能力,如 Docker Machine 和 Docker Swarm。它提供了丰富的用户体验,让 DevOps 管理员在更大规模的生产环境上运行 Docker。
访问以下文章可以了解 Linux 系统上安装 Docker。
推荐阅读:
Rancher 特性
- 可以在两分钟内安装 Kubernetes。
- 一键启动应用(90 个流行的 Docker 应用)。
- 部署和管理 Docker 更容易。
- 全面的生产级容器管理平台。
- 可以在生产环境上快速部署容器。
- 强大的自动部署和运营容器技术。
- 模块化基础设施服务。
- 丰富的编排工具。
- Rancher 支持多种认证机制。
怎样安装 Rancher
由于 Rancher 是以轻量级的 Docker 容器方式运行,所以它的安装非常简单。Rancher 是由一组 Docker 容器部署的。只需要简单的启动两个容器就能运行 Rancher。一个容器用作管理服务器,另一个容器在各个节点上作为代理。在 Linux 系统下简单的运行下列命令就能部署 Rancher。
Rancher 服务器提供了两个不同的安装包标签如 stable 和 latest。下列命令将会拉取适合的 Rancher 镜像并安装到你的操作系统上。Rancher 服务器仅需要两分钟就可以启动。
latest:这个标签是他们的最新开发构建。这些构建将通过 Rancher CI 的自动化框架进行验证,不建议在生产环境使用。stable:这是最新的稳定发行版本,推荐在生产环境使用。
Rancher 的安装方法有多种。在这篇教程中我们仅讨论两种方法。
- 以单一容器的方式安装 Rancher(内嵌 Rancher 数据库)
- 以单一容器的方式安装 Rancher(外部数据库)
方法 - 1
运行下列命令以单一容器的方式安装 Rancher 服务器(内嵌数据库)
$ sudo docker run -d --restart=unless-stopped -p 8080:8080 rancher/server:stable
$ sudo docker run -d --restart=unless-stopped -p 8080:8080 rancher/server:latest方法 - 2
你可以在启动 Rancher 服务器时指向外部数据库,而不是使用自带的内部数据库。首先创建所需的数据库,数据库用户为同一个。
> CREATE DATABASE IF NOT EXISTS cattle COLLATE = 'utf8_general_ci' CHARACTER SET = 'utf8';
> GRANT ALL ON cattle.* TO 'cattle'@'%' IDENTIFIED BY 'cattle';
> GRANT ALL ON cattle.* TO 'cattle'@'localhost' IDENTIFIED BY 'cattle';运行下列命令启动 Rancher 去连接外部数据库。
$ sudo docker run -d --restart=unless-stopped -p 8080:8080 rancher/server \
--db-host myhost.example.com --db-port 3306 --db-user username --db-pass password --db-name cattle如果你想测试 Rancher 2.0,使用下列的命令去启动。
$ sudo docker run -d --restart=unless-stopped -p 80:80 -p 443:443 rancher/server:preview通过 GUI 访问 & 安装 Rancher
浏览器输入 http://hostname:8080 或 http://server_ip:8080 去访问 rancher GUI.

怎样注册主机
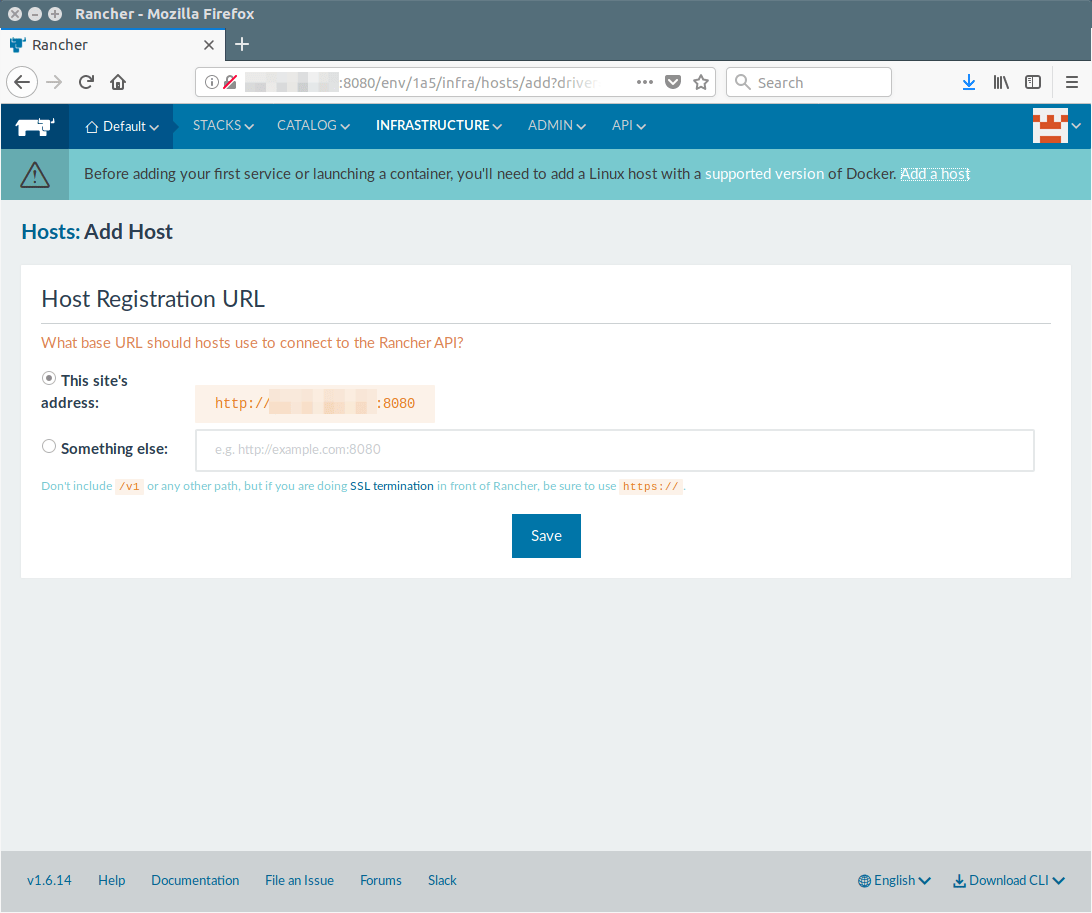
注册你的主机 URL 允许它连接到 Rancher API。这是一次性设置。
接下来,点击主菜单下面的 “Add a Host” 链接或者点击主菜单上的 “INFRASTRUCTURE >> Add Hosts”,点击 “Save” 按钮。
默认情况下,Rancher 里的访问控制认证禁止了访问,因此我们首先需要通过一些方法打开访问控制认证,否则任何人都不能访问 GUI。
点击 “>> Admin >> Access Control”,输入下列的值最后点击 “Enable Authentication” 按钮去打开它。在我这里,是通过 “local authentication” 的方式打开的。
- “Login UserName”: 输入你期望的登录名
- “Full Name”: 输入你的全名
- “Password”: 输入你期望的密码
- “Confirm Password”: 再一次确认密码

注销然后使用新的登录凭证重新登录:
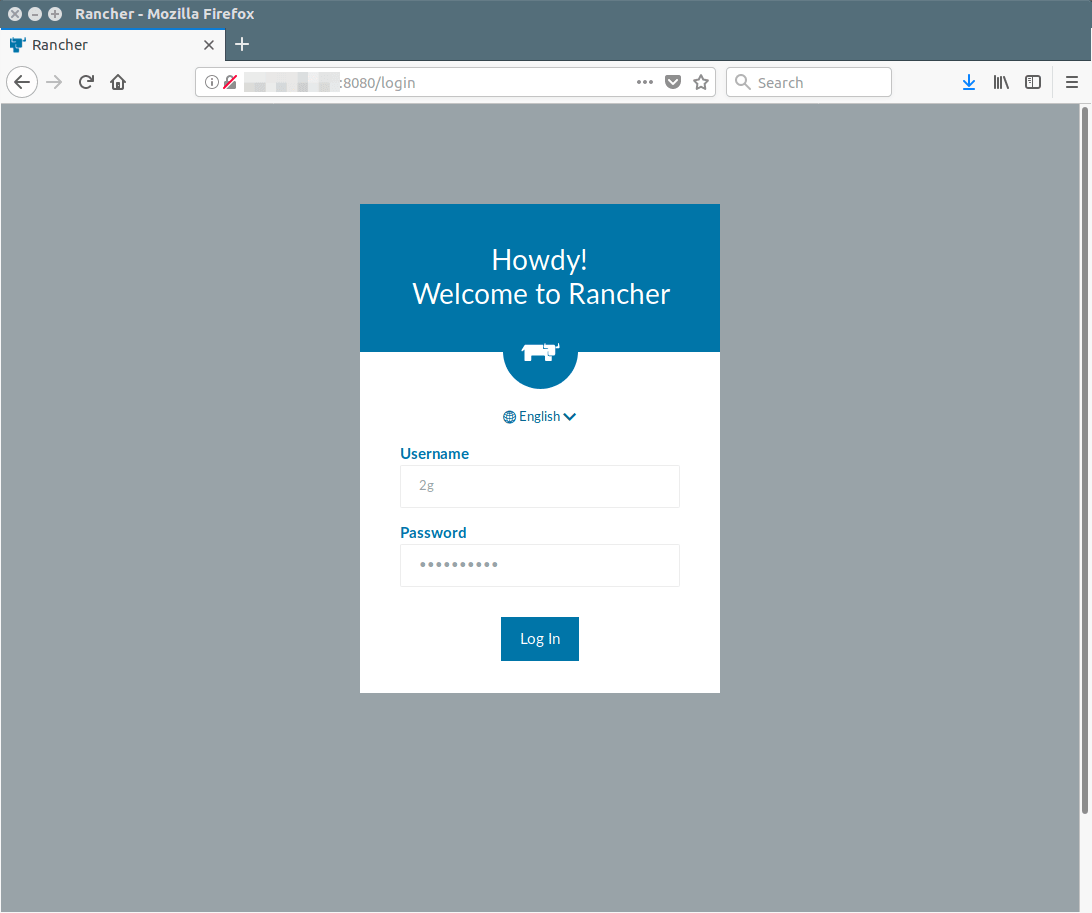
现在,我能看到本地认证已经被打开。

怎样添加主机
注册你的主机后,它将带你进入下一个页面,在那里你能选择不同云服务提供商的 Linux 主机。我们将添加一个主机运行 Rancher 服务,因此选择“custom”选项然后输入必要的信息。
在第 4 步输入你服务器的公有 IP,运行第 5 步列出的命令,最后点击 “close” 按钮。
$ sudo docker run -e CATTLE_AGENT_IP="192.168.56.2" --rm --privileged -v /var/run/docker.sock:/var/run/docker.sock -v /var/lib/rancher:/var/lib/rancher rancher/agent:v1.2.11 http://192.168.56.2:8080/v1/scripts/16A52B9BE2BAB87BB0F5:1546214400000:ODACe3sfis5V6U8E3JASL8jQ
INFO: Running Agent Registration Process, CATTLE_URL=http://192.168.56.2:8080/v1
INFO: Attempting to connect to: http://192.168.56.2:8080/v1
INFO: http://192.168.56.2:8080/v1 is accessible
INFO: Configured Host Registration URL info: CATTLE_URL=http://192.168.56.2:8080/v1 ENV_URL=http://192.168.56.2:8080/v1
INFO: Inspecting host capabilities
INFO: Boot2Docker: false
INFO: Host writable: true
INFO: Token: xxxxxxxx
INFO: Running registration
INFO: Printing Environment
INFO: ENV: CATTLE_ACCESS_KEY=9946BD1DCBCFEF3439F8
INFO: ENV: CATTLE_AGENT_IP=192.168.56.2
INFO: ENV: CATTLE_HOME=/var/lib/cattle
INFO: ENV: CATTLE_REGISTRATION_ACCESS_KEY=registrationToken
INFO: ENV: CATTLE_REGISTRATION_SECRET_KEY=xxxxxxx
INFO: ENV: CATTLE_SECRET_KEY=xxxxxxx
INFO: ENV: CATTLE_URL=http://192.168.56.2:8080/v1
INFO: ENV: DETECTED_CATTLE_AGENT_IP=172.17.0.1
INFO: ENV: RANCHER_AGENT_IMAGE=rancher/agent:v1.2.11
INFO: Launched Rancher Agent: e83b22afd0c023dabc62404f3e74abb1fa99b9a178b05b1728186c9bfca71e8d
等待几秒钟后新添加的主机将会出现。点击 “Infrastructure >> Hosts” 页面。
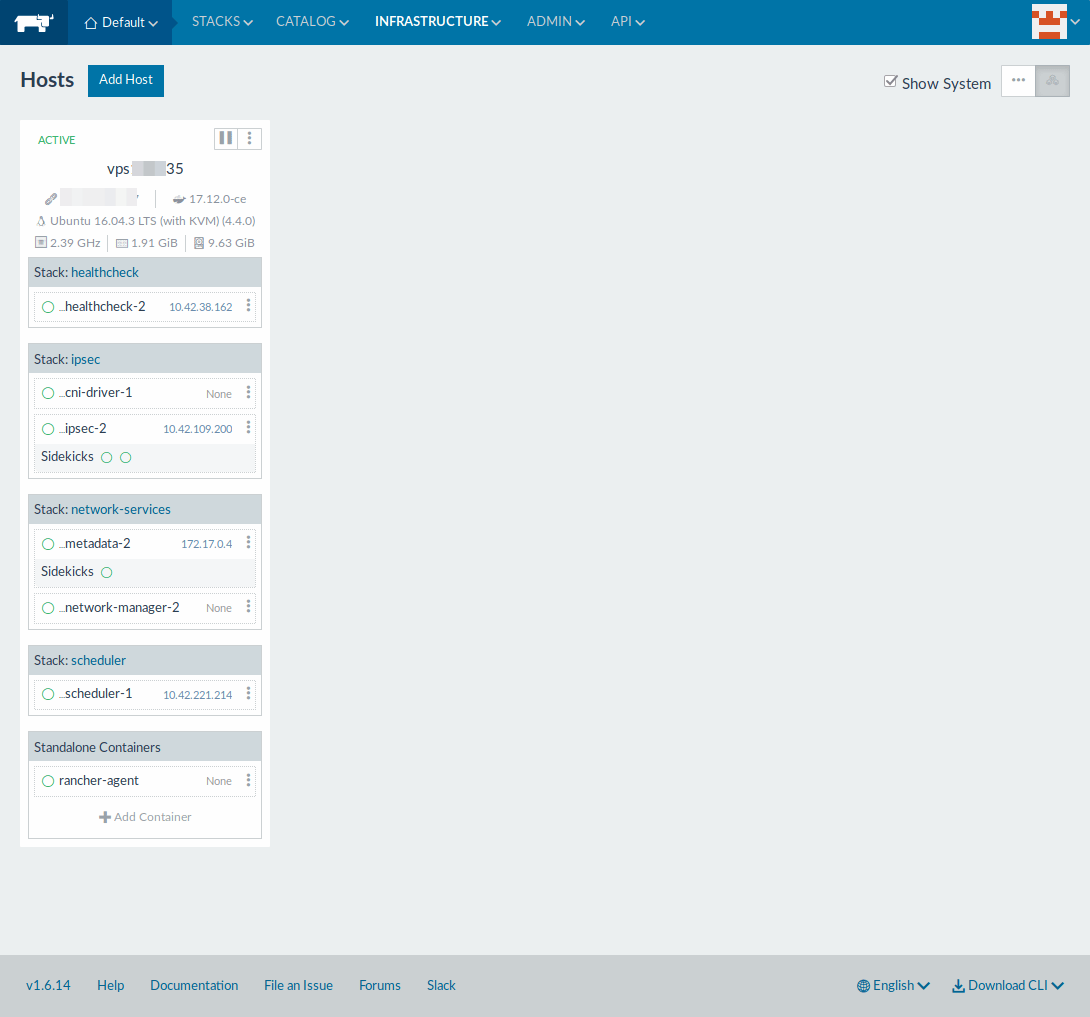
怎样查看容器
只需要点击下列位置就能列出所有容器。点击 “Infrastructure >> Containers” 页面。

怎样创建容器
非常简单,只需点击下列位置就能创建容器。
点击 “Infrastructure >> Containers >> Add Container” 然后输入每个你需要的信息。为了测试,我将创建一个 latest 标签的 CentOS 容器。

在同样的列表位置,点击 “ Infrastructure >> Containers”。

点击容器名展示容器的性能信息,如 CPU、内存、网络和存储。
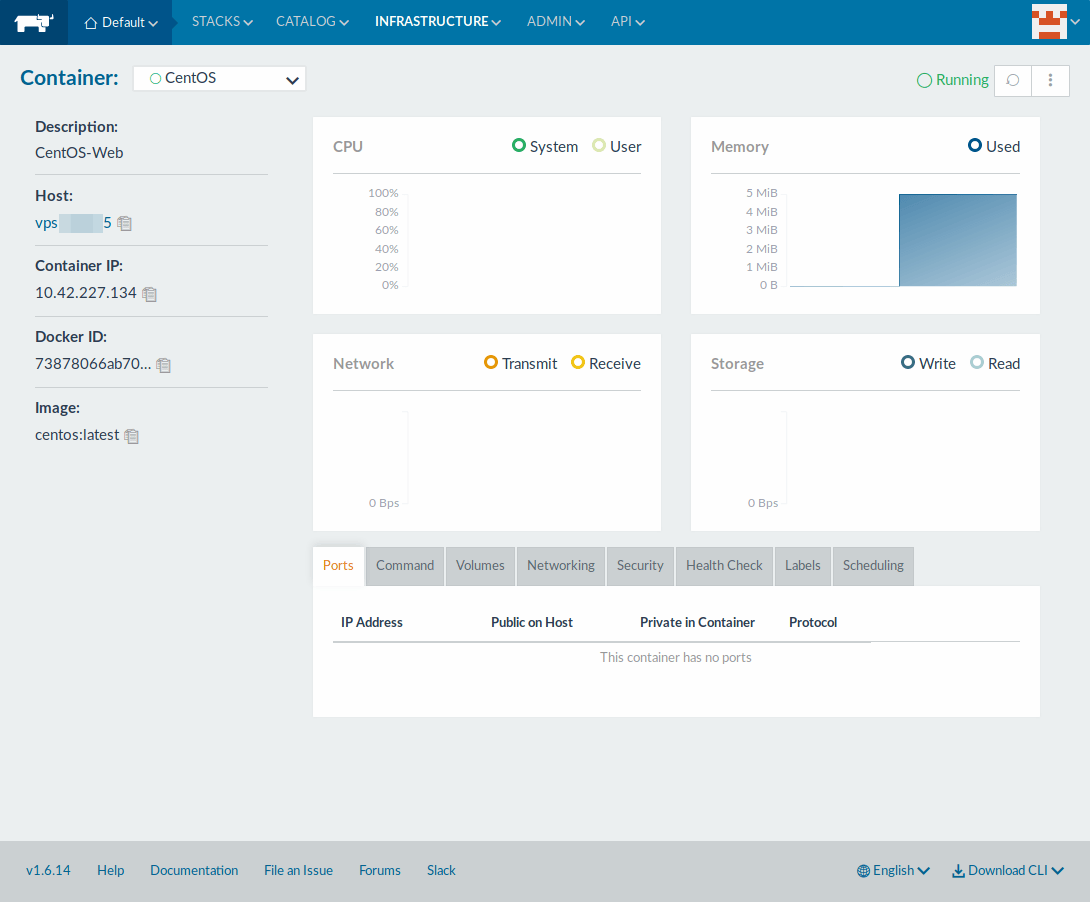
选择特定容器,然后点击最右边的“三点”按钮或者点击“Actions”按钮对容器进行管理,如停止、启动、克隆、重启等。

如果你想控制台访问容器,只需要点击 “Actions” 按钮中的 “Execute Shell” 选项即可。

怎样从应用目录部署容器
Rancher 提供了一个应用模版目录,让部署变的很容易,只需要单击一下就可以。 它维护了多数流行应用,这些应用由 Rancher 社区贡献。

点击 “Catalog >> All >> Choose the required application”,最后点击 “Launch” 去部署。

作者:Magesh Maruthamuthu 译者:arrowfeng 校对:wxy














