http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html
This is an HTML rendering of a working paper draft that led to a publication. The publication should always be cited in preference to this draft using the following reference:
This document is also available in PDF format.
The document's metadata is available in BibTeX format.
This material is presented to ensure timely dissemination of scholarly and technical work. Copyright and all rights therein are retained by authors or by other copyright holders. All persons copying this information are expected to adhere to the terms and constraints invoked by each author's copyright. In most cases, these works may not be reposted without the explicit permission of the copyright holder.
Diomidis Spinellis Publications
© 2015 IEEE. Personal use of this material is permitted. However, permission to reprint/republish this material for advertising or promotional purposes or for creating new collective works for resale or redistribution to servers or lists, or to reuse any copyrighted component of this work in other works must be obtained from the IEEE.

摘要
Unix 操作系统的进化历史,可以从一个版本控制仓库中窥见,时间跨度从 1972 年的 5000 行内核代码开始,到 2015 年成为一个含有 26,000,000 行代码的被广泛使用的系统。该仓库包含 659,000 条提交,和 2306 次合并。仓库部署了被普遍采用的 Git 系统用于储存其代码,并且在时下流行的 GitHub 上建立了存档。它由来自 贝尔实验室 , 伯克利大学 ,386BSD 团队所开发的系统软件的 24 个快照综合定制而成,这包括两个老式仓库和一个开源 FreeBSD 系统的仓库。总的来说,可以确认其中的 850 位个人贡献者,更早些时候的一批人主要做基础研究。这些数据可以用于一些经验性的研究,在软件工程,信息系统和软件考古学领域。
1、介绍
Unix 操作系统作为一个主要的工程上的突破而脱颖而出,得益于其模范的设计、大量的技术贡献、它的开发模型及广泛的使用。Unix 编程环境的设计已经被视为一个提供非常简洁、强大而优雅的设计 [1] 。在技术方面,许多对 Unix 有直接贡献的,或者因 Unix 而流行的特性就包括 [2] :用高级语言编写的可移植部署的内核;一个分层式设计的文件系统;兼容的文件,设备,网络和进程间 I/O;管道和过滤架构;虚拟文件系统;和作为普通进程的可由用户选择的不同 shell。很早的时候,就有一个庞大的社区为 Unix 贡献软件 [3] ,[4,pp. 65-72] 。随时间流逝,这个社区不断壮大,并且以现在称为开源软件开发的方式在工作着 [5,pp. 440-442] 。Unix 和其睿智的晚辈们也将 C 和 C++ 编程语言、分析程序和词法分析生成器(yacc,lex)、文档编制工具(troff,eqn,tbl)、脚本语言(awk,sed,Perl)、TCP/IP 网络、和 配置管理系统 (SCSS,RCS,Subversion,Git)发扬广大了,同时也形成了现代互联网基础设施和网络的最大的部分。
幸运的是,一些重要的具有历史意义的 Unix 材料已经保存下来了,现在保持对外开放。尽管 Unix 最初是由相对严格的协议发行,但在早期的开发中,很多重要的部分是通过 Unix 的版权拥有者之一(Caldera International) (LCTT 译注:2002年改名为 SCO Group)以一个自由的协议发行。通过将这些部分再结合上由 加州大学伯克利分校 和 FreeBSD 项目组开发或发布的开源软件,贯穿了从 1972 年六月二十日开始到现在的整个系统的开发。
通过规划和处理这些可用的快照以及或旧或新的配置管理仓库,将这些可用数据的大部分重建到一个新合成的 Git 仓库之中。这个仓库以数字的形式记录了过去44年来最重要的数字时代产物的详细的进化。下列章节描述了该仓库的结构和内容(第2节)、创建方法(第3节)和该如何使用(第4节)。
2、数据概览
这 1GB 的 Unix 历史仓库可以从 GitHub 上克隆 1 。如今 2 ,这个仓库包含来自 850 个贡献者的 659,000 个提交和 2,306 个合并。贡献者有来自 贝尔实验室 的 23 个员工, 伯克利大学 的 计算机系统研究组 (CSRG)的 158 个人,和 FreeBSD 项目的 660 个成员。
这个仓库的生命始于一个 Epoch 的标签,这里面只包含了证书信息和现在的 README 文件。其后各种各样的标签和分支记录了很多重要的时刻。
- Research-VX 标签对应来自 贝尔实验室 六个研究版本。从 Research-V1 (4768 行 PDP-11 汇编代码)开始,到以 Research-V7 (大约 324,000 行代码,1820 个 C 文件)结束。
- Bell-32V 是第七个版本 Unix 在 DEC/VAX 架构上的移植。
- BSD-X 标签对应 伯克利大学 释出的 15 个快照。
- 386BSD-X 标签对应该系统的两个开源版本,主要是 Lynne 和 William Jolitz 写的适用于 Intel 386 架构的内核代码。
- FreeBSD-release/X 标签和分支标记了来自 FreeBSD 项目的 116 个发行版。
另外,以 -Snapshot-Development 为后缀的分支,表示该提交由来自一个以时间排序的快照文件序列而合成;而以一个 -VCS-Development 为后缀的标签,标记了有特定发行版出现的历史分支的时刻。
仓库的历史包含从系统开发早期的一些提交,比如下面这些。
commit c9f643f59434f14f774d61ee3856972b8c3905b1
Author: Dennis Ritchie <research!dmr>
Date: Mon Dec 2 18:18:02 1974 -0500
Research V5 development
Work on file usr/sys/dmr/kl.c
两个发布之间的合并代表着系统发生了进化,比如 BSD 3 的开发来自 BSD2 和 Unix 32/V,它在 Git 仓库里正是被表示为带两个父节点的图形节点。
更为重要的是,以这种方式构造的仓库允许 git blame,就是可以给源代码行加上注释,如版本、日期和它们第一次出现相关联的作者,这样可以知道任何代码的起源。比如说,检出 BSD-4 这个标签,并在内核的 pipe.c 文件上运行一下 git blame,就会显示出由 Ken Thompson 写于 1974,1975 和 1979年的代码行,和 Bill Joy 写于 1980 年的。这就可以自动(尽管计算上比较费事)检测出任何时刻出现的代码。

图1:各个重大 Unix 发行版的代码来源
如上图所示,现代版本的 Unix(FreeBSD 9)依然有相当部分的来自 BSD 4.3,BSD 4.3 Net/2 和 BSD 2.0 的代码块。有趣的是,这图片显示有部分代码好像没有保留下来,当时激进地要创造一个脱离于伯克利(386BSD 和 FreeBSD 1.0)所释出代码的开源操作系统。FreeBSD 9 中最古老的代码是一个 18 行的队列,在 C 库里面的 timezone.c 文件里,该文件也可以在第七版的 Unix 文件里找到,同样的名字,时间戳是 1979 年一月十日 - 36 年前。
3、数据收集和处理
这个项目的目的是以某种方式巩固从数据方面说明 Unix 的进化,通过将其并入一个现代的版本仓库,帮助人们对系统进化的研究。项目工作包括收录数据,分类并综合到一个单独的 Git 仓库里。
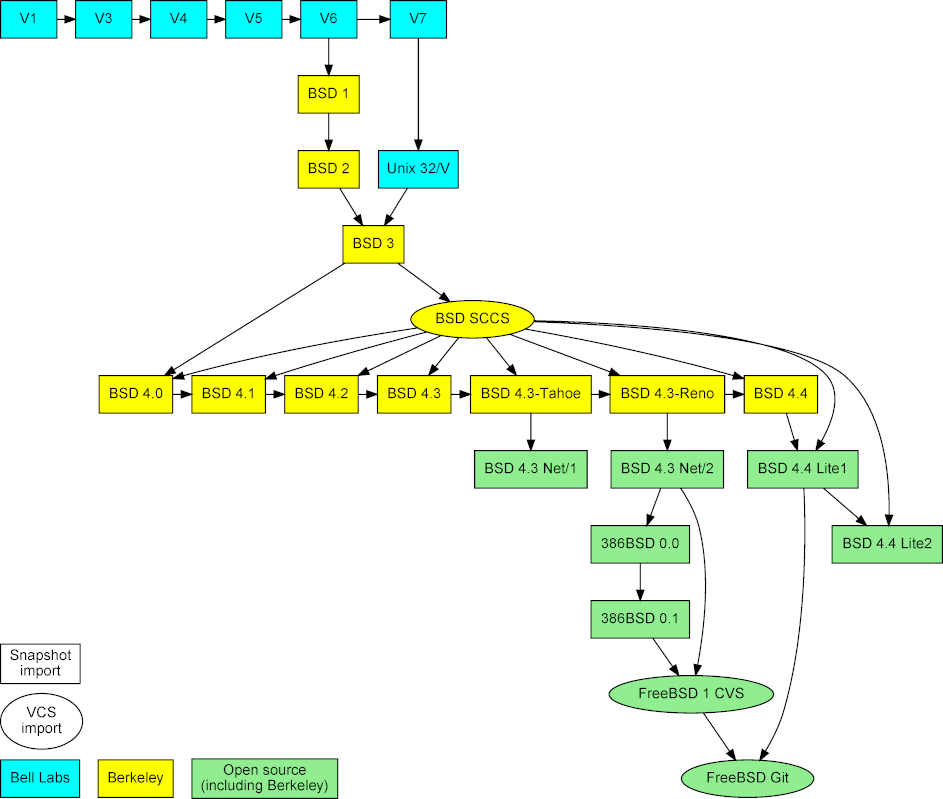
图2:导入 Unix 快照、仓库及其合并
项目以三种数据类型为基础(见图2)。首先,早期发布版本的快照,获取自 Unix 遗产社会归档 3 、包括了 CSRG 全部的源代码归档的 CD-ROM 镜像 4 , Oldlinux 网站 5 和 FreeBSD 归档 6 。 其次,以前的和现在的仓库,即 CSRG SCCS [6] 仓库,FreeBSD 1 CVS 仓库,和现代 FreeBSD 开发的 Git 镜像 7 。前两个都是从和快照相同的来源获得的。
最后,也是最费力的数据源是 初步研究 。释出的快照并没有提供关于它们的源头和每个文件贡献者的信息。因此,这些信息片段需要通过 初步研究 验证。至于作者信息主要通过作者的自传,研究论文,内部备忘录和旧文档扫描件;通过阅读并且自动处理源代码和帮助页面补充;通过与那个年代的人用电子邮件交流;在 StackExchange 网站上贴出疑问;查看文件的位置(在早期的内核版本的源代码,分为 usr/sys/dmr 和 /usr/sys/ken 两个位置);从研究论文和帮助手册披露的作者找到源代码,从一个又一个的发行版中获取。(有趣的是,第一和第二的 研究版 帮助页面都有一个 “owner” 部分,列出了作者(比如,Ken)及对应的系统命令、文件、系统调用或库函数。在第四版中这个部分就没了,而在 BSD 发行版中又浮现了 “Author” 部分。)关于作者信息更为详细地写在了项目的文件中,这些文件被用于匹配源代码文件和它们的作者和对应的提交信息。最后,关于源代码库之间的合并信息是获取自 NetBSD 项目所维护的 BSD 家族树 8 。
作为本项目的一部分而开发的软件和数据文件,现在可以在线获取 9 ,并且,如果有合适的网络环境,CPU 和磁盘资源,可以用来从头构建这样一个仓库。关于主要发行版的作者信息,都存储在本项目的 author-path 目录下的文件里。它们的内容中带有正则表达式的文件路径后面指出了相符的作者。可以指定多个作者。正则表达式是按线性处理的,所以一个文件末尾的匹配一切的表达式可以指定一个发行版的默认作者。为避免重复,一个以 .au 后缀的独立文件专门用于映射作者的 识别号 和他们的名字及 email。这样一个文件为每个与该系统进化相关的社区都建立了一个: 贝尔实验室 , 伯克利大学 ,386BSD 和 FreeBSD。为了真实性的需要,早期 贝尔实验室 发行版的 emails 都以 UUCP 注释 方式列出(例如, research!ken)。FreeBSD 作者的识别映射,需要导入早期的 CVS 仓库,通过从如今项目的 Git 仓库里拆解对应的数据构建。总的来说,由 1107 行构成了注释作者信息的文件(828 个规则),并且另有 640 行用于映射作者的识别号到名字。
现在项目的数据源被编码成了一个 168 行的 Makefile。它包括下面的步骤。
Fetching 从远程站点复制和克隆大约 11GB 的镜像、归档和仓库。
Tooling 从 2.9 BSD 中为旧的 PDP-11 归档获取一个归档器,并调整它以在现代的 Unix 版本下编译;编译 4.3 BSD 的 compress 程序来解压 386BSD 发行版,这个程序不再是现代 Unix 系统的组成部分了。
Organizing 用 tar 和 cpio 解压缩包;合并第六个研究版的三个目录;用旧的 PDP-11 归档器解压全部一个 BSD 归档;挂载 CD-ROM 镜像,这样可以作为文件系统处理;合并第 8 和 62 的 386BSD 磁盘镜像为两个独立的文件。
Cleaning 恢复第一个研究版的内核源代码文件,这个可以通过 OCR 从打印件上得到近似其原始状态的的格式;给第七个研究版的源代码文件打补丁;移除发行后被添加进来的元数据和其他文件,为避免得到错误的时间戳信息;修复毁坏的 SCCS 文件;用一个定制的 Perl 脚本移除指定到多个版本的 CVS 符号、删除与现在冲突的 CVS Attr 文件、用 cvs2svn 将 CVS 仓库转换为 Git 仓库,以处理早期的 FreeBSD CVS 仓库。
在仓库 再现 中有一个很有意思的部分就是,如何导入那些快照,并以一种方式联系起来,使得 git blame 可以发挥它的魔力。快照导入到仓库是基于每个文件的时间戳作为一系列的提交实现的。当所有文件导入后,就被用对应发行版的名字给标记了。然后,可以删除那些文件,并开始导入下一个快照。注意 git blame 命令是通过回溯一个仓库的历史来工作的,并使用 启发法 来检测文件之间或文件内的代码移动和复制。因此,删除掉的快照间会产生中断,以防止它们之间的代码被追踪。
相反,在下一个快照导入之前,之前快照的所有文件都被移动到了一个隐藏的后备目录里,叫做 .ref(引用)。它们保存在那,直到下个快照的所有文件都被导入了,这时候它们就会被删掉。因为 .ref 目录下的每个文件都精确对应一个原始文件,git blame 可以知道多少源代码通过 .ref 文件从一个版本移到了下一个,而不用显示出 .ref 文件。为了更进一步帮助检测代码起源,同时增加 再现 的真实性,每个发行版都被 再现 为一个有增量文件的分支(-Development)与之前发行版之间的合并。
上世纪 80 年代时期,只有 伯克利大学 开发的文件的一个子集是用 SCCS 版本控制的。在那个期间,我们的统一仓库里包含了来自 SCCS 的提交和快照的增量文件的导入数据。对于每个发行版,可用最近的时间戳找到该 SCCS 提交,并被标记为一个与发行版增量导入分支的合并。这些合并可以在图2 的中间看到。
将各种数据资源综合到一个仓库的工作,主要是用两个脚本来完成的。一个 780 行的 Perl 脚本(import-dir.pl)可以从一个单独的数据源(快照目录、SCCS 仓库,或者 Git 仓库)中,以 Git fast export 格式导出(真实的或者综合的)提交历史。输出是一个简单的文本格式,Git 工具用这个来导入和导出提交。其他方面,这个脚本以一些东西为参数,如文件到贡献者的映射、贡献者登录名和他们的全名间的映射、哪个导入的提交会被合并、哪些文件要处理和忽略、以及“引用”文件的处理。一个 450 行的 Shell 脚本创建 Git 仓库,并调用带适当参数的 Perl 脚本,来导入 27 个可用的历史数据资源。Shell 脚本也会运行 30 个测试,比较特定标签的仓库和对应的数据源,核对查看的目录中出现的和没出现的,并回溯查看分支树和合并的数量,git blame 和 git log 的输出。最后,调用 git 作垃圾收集和仓库压缩,从最初的 6GB 降到分发的 1GB 大小。
4、数据使用
该数据可以用于软件工程、信息系统和 软件考古学 领域的经验性研究。鉴于它从不间断而独一无二的存在了超过了 40 年,可以供软件进化和跨代更迭参考。从那时以来,处理速度已经成千倍地增长、存储容量扩大了百万倍,该数据同样可以用于软件和硬件技术 交叉进化 的研究。软件开发从研究中心到大学,到开源社区的转移,可以用来研究组织文化对于软件开发的影响。该仓库也可以用于学习著名人物的实际编程,比如 Turing 奖获得者(Dennis Ritchie 和 Ken Thompson)和 IT 产业的大佬(Bill Joy 和 Eric Schmidt)。另一个值得学习的现象是代码的长寿,无论是单行的水平,或是作为那个时代随 Unix 发布的完整的系统(Ingres、 Lisp、 Pascal、 Ratfor、 Snobol、 TMP),和导致代码存活或消亡的因素。最后,因为该数据让 Git 感到了压力,底层的软件仓库存储技术达到了其极限,这会推动版本管理系统领域的工程进度。

图3:Unix 发行版的代码风格进化
图3 根据 36 个主要 Unix 发行版描述了一些有趣的代码统计的趋势线(用 R 语言的局部多项式回归拟合函数生成),验证了代码风格和编程语言的使用在很长的时间尺度上的进化。这种进化是软硬件技术的需求和支持、软件构筑理论,甚至社会力量所驱动的。图片中的日期计算了出现在一个给定发行版中的所有文件的平均日期。正如可以从中看到,在过去的 40 年中,标示符和文件名字的长度已经稳步从 4 到 6 个字符增长到 7 到 11 个字符。我们也可以看到注释数量的少量稳步增加,以及 goto 语句的使用量减少,同时 register 这个类型修饰符的消失。
5、未来的工作
可以做很多事情去提高仓库的正确性和有效性。创建过程以开源代码共享了,通过 GitHub 的 拉取请求 ,可以很容易地贡献更多代码和修复。最有用的社区贡献将使得导入的快照文件的覆盖面增长,以便归属于某个具体的作者。现在,大约 90,000 个文件(在 160,000 总量之外)通过默认规则指定了作者。类似地,大约有 250 个作者(最初 FreeBSD 那些)仅知道其识别号。两个都列在了 build 仓库的 unmatched 目录里,欢迎贡献数据。进一步,BSD SCCS 和 FreeBSD CVS 的提交共享相同的作者和时间戳,这些可以结合成一个单独的 Git 提交。导入 SCCS 文件提交的支持会被添加进来,以便引入仓库对应的元数据。最后,也是最重要的,开源系统的更多分支会添加进来,比如 NetBSD、 OpenBSD、DragonFlyBSD 和 illumos。理想情况下,其他历史上重要的 Unix 发行版,如 System III、System V、 NeXTSTEP 和 SunOS 等的当前版权拥有者,也会在一个允许他们的合作伙伴使用仓库用于研究的协议下释出他们的系统。
鸣谢
本文作者感谢很多付出努力的人们。 Brian W. Kernighan, Doug McIlroy 和 Arnold D. Robbins 在贝尔实验室(Bell Labs)的登录识别号方面提供了帮助。 Clem Cole, Era Erikson, Mary Ann Horton, Kirk McKusick, Jeremy C. Reed, Ingo Schwarze 和 Anatole Shaw 在 BSD 的登录识别号方面提供了帮助。BSD SCCS 的导入代码是基于 H. Merijn Brand 和 Jonathan Gray 的工作。
这次研究由欧盟 ( 欧洲社会基金 ) 和 希腊国家基金 通过 国家战略参考框架 的 Operational Program " Education and Lifelong Learning" - Research Funding Program: Thalis - Athens University of Economics and Business - Software Engineering Research Platform ,共同出资赞助。
引用
1 M. D. McIlroy, E. N. Pinson, and B. A. Tague, "UNIX time-sharing system: Foreword," The Bell System Technical Journal, vol. 57, no. 6, pp. 1899-1904, July-August 1978.
2 D. M. Ritchie and K. Thompson, "The UNIX time-sharing system," Bell System Technical Journal, vol. 57, no. 6, pp. 1905-1929, July-August 1978.
3 D. M. Ritchie, "The evolution of the UNIX time-sharing system," AT&T Bell Laboratories Technical Journal, vol. 63, no. 8, pp. 1577-1593, Oct. 1984.
4 P. H. Salus, A Quarter Century of UNIX. Boston, MA: Addison-Wesley, 1994.
5 E. S. Raymond, The Art of Unix Programming. Addison-Wesley, 2003.
6 M. J. Rochkind, "The source code control system," IEEE Transactions on Software Engineering, vol. SE-1, no. 4, pp. 255-265, 1975.
脚注
1 - https://github.com/dspinellis/unix-history-repo
2 - Updates may add or modify material. To ensure replicability the repository's users are encouraged to fork it or archive it.
3 - http://www.tuhs.org/archive_sites.html
4 - https://www.mckusick.com/csrg/
5 - http://www.oldlinux.org/Linux.old/distributions/386BSD
6 - http://ftp-archive.freebsd.org/pub/FreeBSD-Archive/old-releases/
7 - https://github.com/freebsd/freebsd
8 - http://ftp.netbsd.org/pub/NetBSD/NetBSD-current/src/share/misc/bsd-family-tree
9 - https://github.com/dspinellis/unix-history-make
via: http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html
作者:Diomidis Spinellis译者:wi-cuckoo 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出












")
")
