Webpack 2 一旦文档完成,就将结束 Beta 测试期。不过这并不意味着你现在不能开始使用第 2 版,前提是你知道怎么配置它。(LCTT 译注:Webpack 2.1 已经发布。)
Webpack 是什么
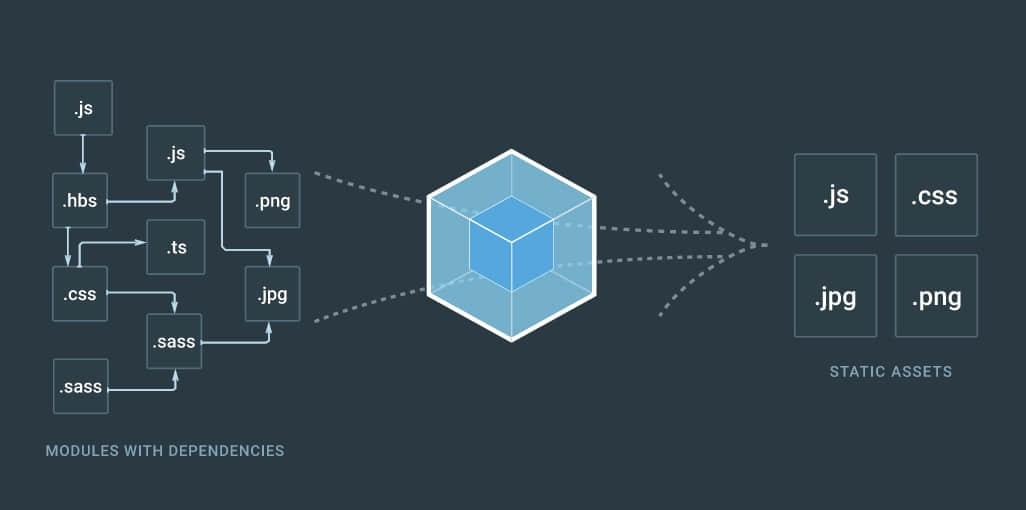
简单来说,Webpack 是一个 JavaScript 模块打包器。然而,自从它发布以来,它发展成为了你所有的前端代码的管理工具(或许是有意的,或许是社区的意愿)。
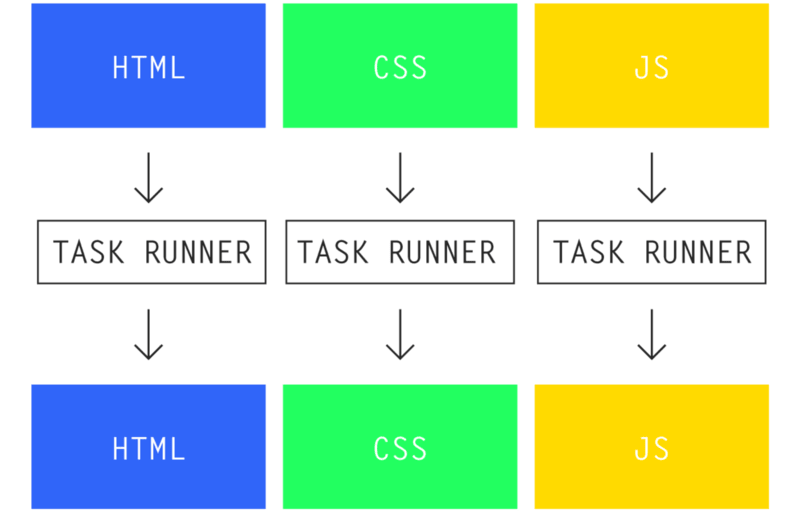
老式的任务运行器的方式:你的标记、样式和 JavaScript 是分离的。你必须分别管理它们每一个,并且你需要确保每一样都达到产品级
任务运行器 ,例如 Gulp,可以处理许多不同的 预处理器 和 转换器 ,但是在所有的情景下,它都需要一个输入源并将其压缩到一个编译好的输出文件中。然而,它是在每个部分的基础上这样做的,而没有考虑到整个系统。这就造成了开发者的负担:找到任务运行器所不能处理的地方,并找到适当的方式将所有这些模块在生产环境中联合在一起。
Webpack 试图通过提出一个大胆的想法来减轻开发者的负担:如果有一部分开发过程可以自动处理依赖关系会怎样?如果我们可以简单地写代码,让构建过程最终只根据需求管理自己会怎样?
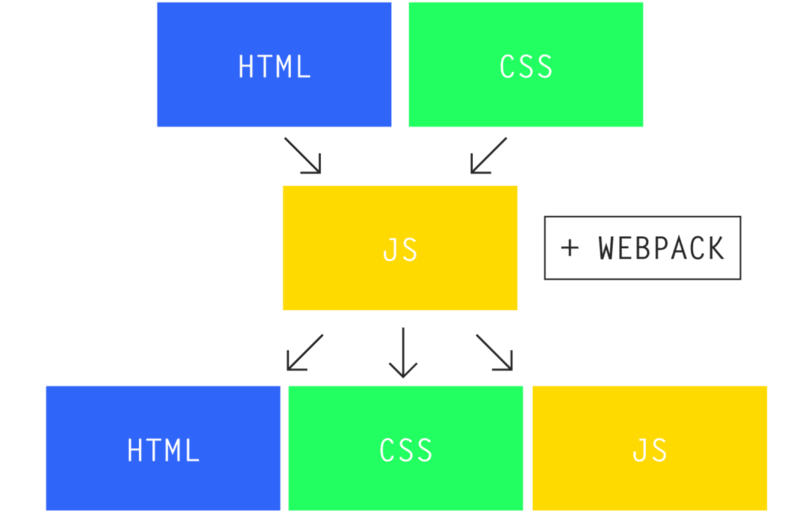
Webpack 的方式:如果 Webpack 了解依赖关系,它会仅捆绑我们在生产环境中实际需要的部分
如果你过去几年一直参与 web 社区,你已经知道解决问题的首选方法:使用 JavaScript 来构建。而且 Webpack 尝试通过 JavaScript 传递依赖关系使得构建过程更加容易。不过这个设计真正的亮点不是简化代码管理部分,而是管理层由 100% 有效的 JavaScript 实现(具有 Nodejs 特性)。Webpack 能够让你编写有效的 JavaScript,更好更全面地了解系统。
换句话来说:你不需要为 Webpack 写代码。你只需要写项目代码。而且 Webpack 就会持续工作(当然需要一些配置)。
简而言之,如果你曾经遇到过以下任何一种情况:
- 载入有问题的依赖项
- 意外引入一些你不需要在生产中用上的 CSS 样式表和 JS 库,使项目膨胀
- 意外的两次载入(或三次)库
- 遇到作用域的问题 —— CSS 和 JavaScript 都会有
- 寻找一个让你在 JavaScript 中使用 Node/Bower 模块的构建系统,要么就得依靠一个令人发狂的后端配置才能正确地使用这些模块
- 需要优化 资产 交付,但你担心会弄坏一些东西
等等……
那么你可以从 Webpack 中收益了。它通过让 JavaScript 轻松处理你的依赖关系和加载顺序,而不是通过开发者的大脑。最好的部分是,Webpack 甚至可以纯粹在服务器端运行,这意味着你还可以使用 Webpack 构建渐进增强式网站。
第一步
我们将在本教程中使用 Yarn(运行命令 brew install yarn) 代替 npm,不过这完全取决于你的喜好,它们做同样的事情。在我们的项目文件夹中,我们将在终端窗口中运行以下代码,将 Webpack 2 添加到我们的全局软件包以及本地项目中:
yarn global add [email protected] [email protected]
yarn add --dev [email protected] [email protected]
我们接着会通过项目根目录的一个 webpack.config.js 文件来声明 webpack 的配置:
'use strict';
const webpack = require('webpack');
module.exports = {
context: __dirname + '/src',
entry: {
app: './app.js',
},
output: {
path: __dirname + '/dist',
filename: '[name].bundle.js',
},
};
注意:此处 __dirname 是指你的项目根目录
记住,Webpack “知道”你的项目发生了什么。它通过阅读你的代码来实现(别担心,它签署了保密协议 :D )。Webpack 基本上执行以下操作:
- 从
context 文件夹开始…… - ……它查找
entry 下的文件名…… - ……并读取其内容。每一个
import(ES6)或 require()(Nodejs)的依赖会在它解析代码的时候找到,它会在最终构建的时候打包这些依赖项。然后,它会搜索那些依赖项以及那些依赖项所依赖的依赖项,直到它到达“树”的最底端 —— 只打包它所需要的,没有其它东西。 - Webpack 从
context 文件夹打包所有东西到 output.path 文件夹,使用 output.filename 命名模板来为其命名(其中 [name] 被替换成来自 entry 的对象的键)。
所以如果我们的 src/app.js 文件看起来像这样(假设我们事先运行了 yarn add --dev moment):
'use strict';
import moment from 'moment';
var rightNow = moment().format('MMMM Do YYYY, h:mm:ss a');
console.log( rightNow );
// "October 23rd 2016, 9:30:24 pm"
我们应该运行:
webpack -p
注意:p 标志表示“生产”模式,这会压缩输出文件。
它会输出一个 dist/app.bundle.js,并将当前日期和时间打印到控制台。要注意 Webpack 会自动识别 上面的 'moment' 指代的是什么(比如说,虽然如果你有一个 moment.js 文件在你的目录,默认情况下 Webpack 会优先考虑你的 moment Node 模块)。
使用多个文件
你可以通过仅仅修改 entry 对象来指定任意数量的 入口 / 输出点 。
打包多个文件
'use strict';
const webpack = require("webpack");
module.exports = {
context: __dirname + "/src",
entry: {
app: ["./home.js", "./events.js", "./vendor.js"],
},
output: {
path: __dirname + "/dist",
filename: "[name].bundle.js",
},
};
所有文件都会按照数组的顺序一起被打包成一个 dist/app.bundle.js 文件。
输出多个文件
const webpack = require("webpack");
module.exports = {
context: __dirname + "/src",
entry: {
home: "./home.js",
events: "./events.js",
contact: "./contact.js",
},
output: {
path: __dirname + "/dist",
filename: "[name].bundle.js",
},
};
或者,你可以选择打包成多个 JS 文件以便于分割应用的某些模块。这将被打包成 3 个文件:dist/home.bundle.js,dist/events.bundle.js 和 dist/contact.bundle.js。
高级打包自动化
如果你将你的应用分割成多个 output 输出项(如果你的应用的一部分有大量你不需要预加载的 JS,这会很有用),你可能会重用这些文件的代码,因为它将分别解析每个依赖关系。幸运的是,Webpack 有一个内置的 CommonsChunk 插件来处理这个:
module.exports = {
// …
plugins: [
new webpack.optimize.CommonsChunkPlugin({
name: "commons",
filename: "commons.bundle.js",
minChunks: 2,
}),
],
// …
};
现在,在你的 output 文件中,如果你有任何模块被加载 2 次以上(通过 minChunks 设置),它会把那个模块打包到 common.js 文件中,然后你可以将其缓存在客户端。这将生成一个额外的请求头,但是你防止了客户端多次下载同一个库。因此,在很多情景下,这会大大提升速度。
开发
Webpack 实际上有自己的开发服务器,所以无论你是开发一个静态网站还是只是你的网站前端原型,它都是无可挑剔的。要运行那个服务器,只需要添加一个 devServer 对象到 webpack.config.js:
module.exports = {
context: __dirname + "/src",
entry: {
app: "./app.js",
},
output: {
filename: "[name].bundle.js",
path: __dirname + "/dist/assets",
publicPath: "/assets", // New
},
devServer: {
contentBase: __dirname + "/src", // New
},
};
现在创建一个包含以下代码的 src/index.html 文件:
<script src="/assets/app.bundle.js"></script>
……在你的终端中运行:
webpack-dev-server
你的服务器现在运行在 localhost:8080。注意 script 标签里面的 /assets 是怎么匹配到 output.publicPath 的 —— 你可以随意更改它的名称(如果你需要一个 CDN 的时候这会很有用)。
Webpack 会热加载所有 JavaScript 更改,而不需要刷新你的浏览器。但是,所有 webpack.config.js 文件里面的更改都需要重新启动服务器才能生效。
全局访问方法
需要在全局空间使用你的函数?在 webpack.config.js 里面简单地设置 output.library:
module.exports = {
output: {
library: 'myClassName',
}
};
……这会将你打包好的文件附加到一个 window.myClassName 实例。因此,使用该命名空间,你可以调用入口文件的可用方法(可以在该文档中阅读有关此设置的更多信息)。
加载器
到目前为止,我们所做的一切只涉及 JavaScript。从一开始就使用 JavaScript 是重要的,因为它是 Webpack 唯一支持的语言。事实上我们可以处理几乎所有文件类型,只要我们将其转换成 JavaScript。我们用 加载器 来实现这个功能。
加载器可以是 Sass 这样的预处理器,或者是 Babel 这样的转译器。在 NPM 上,它们通常被命名为 *-loader,例如 sass-loader 和 babel-loader。
Babel 和 ES6
如果我们想在项目中通过 Babel 来使用 ES6,我们首先需要在本地安装合适的加载器:
yarn add --dev babel-loader babel-core babel-preset-es2015
然后将它添加到 webpack.config.js,让 Webpack 知道在哪里使用它。
module.exports = {
// …
module: {
rules: [
{
test: /\.js$/,
use: [{
loader: "babel-loader",
options: { presets: ["es2015"] }
}],
},
// Loaders for other file types can go here
],
},
// …
};
Webpack 1 的用户注意:加载器的核心概念没有任何改变,但是语法改进了。直到官方文档完成之前,这可能不是确切的首选语法。
/\.js$/ 这个正则表达式查找所有以 .js 结尾的待通过 Babel 加载的文件。Webpack 依靠正则检查给予你完全的控制权 —— 它不限制你的文件扩展名或者假定你的代码必须以某种方式组织。例如:也许你的 /my_legacy_code/ 文件夹下的内容不是用 ES6 写的,所以你可以修改上述的 test 为 /^((?!my_legacy_folder).)\.js$/,这将会排除那个特定的文件夹,不过会用 Babel 处理其余的文件。
CSS 和 Style 加载器
如果我们只想为我们的应用所需加载 CSS,我们也可以这样做。假设我们有一个 index.js 文件,我们将从那里引入:
import styles from './assets/stylesheets/application.css';
我们会得到以下错误:你可能需要一个合适的加载器来处理这种类型的文件。记住,Webpack 只能识别 JavaScript,所以我们必须安装合适的加载器:
yarn add --dev css-loader style-loader
然后添加一条规则到 webpack.config.js:
module.exports = {
// …
module: {
rules: [
{
test: /\.css$/,
use: ["style-loader", "css-loader"],
},
// …
],
},
};
加载器以数组的逆序处理。这意味着 css-loader 会比 style-loader 先执行。
你可能会注意到,即使在生产版本中,这实际上是将你的 CSS 和 JavaScript 打包在一起,style-loader 手动将你的样式写到 <head>。乍一看,它可能看起来有点怪异,但你仔细想想就会发现这就慢慢开始变得更加有意义了。你已经节省了一个头部请求 —— 节省了一些连接上的时间。如果你用 JavaScript 来加载你的 DOM,无论如何,这从本质上消除了 FOUC。
你还会注意到一个开箱即用的特性 —— Webpack 已经通过将这些文件打包在一起以自动解决你所有的 @import 查询(而不是依靠 CSS 默认的 import 方式,这会导致无谓的头部请求以及资源加载缓慢)。
从你的 JS 加载 CSS 是非常惊人的,因为你现在可以用一种新的强大的方式将你的 CSS 模块化。比如说你要只通过 button.js 来加载 button.css,这将意味着如果 button.js 从来没有真正使用过的话,它的 CSS 就不会膨胀我们的生产版本。如果你坚持面向组件的 CSS 实践,如 SMACSS 或 BEM,你会看到更紧密地结合你的 CSS 和你的标记和 JavaScript 的价值。
CSS 和 Node 模块
我们可以使用 Webpack 来利用 Node.js 使用 ~ 前缀导入 Node 模块的优势。如果我们运行 yarn add normalize.css,我们可以使用:
@import "~normalize.css";
……并且充分利用 NPM 来管理我们的第三方样式 —— 版本控制、没有任何副本和粘贴的部分。此外,让 Webpack 为我们打包 CSS 比起使用 CSS 的默认导入方式有明显的优势 —— 节省无谓的头部请求和加载时间。
更新:这一节和下面一节已经更新为准确的用法,不再使用 CSS 模块简单地导入 Node 的模块。感谢 Albert Fernández 的帮助!
CSS 模块
你可能听说过 CSS 模块,它把 CSS 变成了 SS,消除了 CSS 的 层叠性 。通常它的最适用场景是只有当你使用 JavaScript 构建 DOM 的时候,但实质上,它神奇地将你的 CSS 类放置到加载它的 JavaScript 文件里(在这里了解更多)。如果你打算使用它,CSS 模块已经与 css-loader 封装在一起(yarn add --dev css-loader):
module.exports = {
// …
module: {
rules: [
{
test: /\.css$/,
use: [
"style-loader",
{ loader: "css-loader", options: { modules: true } }
],
},
// …
],
},
};
注意:对于 css-loader,我们现在使用 扩展对象语法 来给它传递一个选项。你可以使用一个更为精简的字符串来取代默认选项,正如我们仍然使用了 style-loader。
值得注意的是,当允许导入 CSS 模块的时候(例如:@import 'normalize.css';),你完全可以删除掉 ~。但是,当你 @import 你自己的 CSS 的时候,你可能会遇到构建错误。如果你遇到“无法找到 \_\_\_\_”的错误,尝试添加一个 resolve 对象到 webpack.config.js,让 Webpack 更好地理解你的模块加载顺序。
const path = require("path");
module.exports = {
//…
resolve: {
modules: [path.resolve(__dirname, "src"), "node_modules"]
},
};
我们首先指定源目录,然后指定 node_modules。这样,Webpack 会更好地处理解析,按照既定的顺序(分别用你的源目录和 Node 模块的目录替换 "src" 和 "node_modules"),首先查找我们的源目录,然后再查找已安装的 Node 模块。
Sass
需要使用 Sass?没问题。安装:
yarn add --dev sass-loader node-sass
并添加新的规则:
module.exports = {
// …
module: {
rules: [
{
test: /\.(sass|scss)$/,
use: [
"style-loader",
"css-loader",
"sass-loader",
]
}
// …
],
},
};
然后当你的 Javascript 对一个 .scss 或 .sass 文件调用 import 方法的时候,Webpack 会处理的。
CSS 独立打包
或许你在处理渐进增强的问题;或许你因为其它原因需要一个单独的 CSS 文件。我们可以通过在我们的配置中用 extract-text-webpack-plugin 替换 style-loader 而轻易地做到这一点,这不需要更改任何代码。以我们的 app.js 文件为例:
import styles from './assets/stylesheets/application.css';
让我们安装这个插件到本地(我们需要 2016 年 10 月的测试版本):
yarn add --dev [email protected]
并且添加到 webpack.config.js:
const ExtractTextPlugin = require("extract-text-webpack-plugin");
module.exports = {
// …
module: {
rules: [
{
test: /\.css$/,
use: [
ExtractTextPlugin.extract("css"),
{ loader: "css-loader", options: { modules: true } },
],
},
// …
]
},
plugins: [
new ExtractTextPlugin({
filename: "[name].bundle.css",
allChunks: true,
}),
],
};
现在当运行 webpack -p 的时候,你的 output 目录还会有一个 app.bundle.css 文件。只需要像往常一样简单地在你的 HTML 中向该文件添加一个 <link> 标签即可。
HTML
正如你可能已经猜到,Webpack 还有一个 [html-loader][6] 插件。但是,当我们用 JavaScript 加载 HTML 时,我们针对不同的场景分成了不同的方法,我无法想出一个单一的例子来为你计划下一步做什么。通常,你需要加载 HTML 以便于在更大的系统(如 React、Angular、Vue 或 Ember)中使用 JavaScript 风格的标记,如 JSX、Mustache 或 Handlebars。或者你可以使用类似 Pug (以前叫 Jade)或 Haml 这样的 HTML 预处理器,抑或你可以直接把同样的 HTML 从你的源代码目录推送到你的构建目录。你怎么做都行。
教程到此为止了:你可以用 Webpack 加载标记,但是进展到这一步的时候,关于你的架构,你将做出自己的决定,我和 Webpack 都无法左右你。不过参考以上的例子以及搜索 NPM 上适用的加载器应该足够你发展下去了。
从模块的角度思考
为了充分使用 Webpack,你必须从模块的角度来思考:细粒度的、可复用的、用于高效处理每一件事的独立的处理程序。这意味着采取这样的方式:
└── js/
└── application.js // 300KB of spaghetti code
将其转变成这样:
└── js/
├── components/
│ ├── button.js
│ ├── calendar.js
│ ├── comment.js
│ ├── modal.js
│ ├── tab.js
│ ├── timer.js
│ ├── video.js
│ └── wysiwyg.js
│
└── application.js // ~ 1KB of code; imports from ./components/
结果呈现了整洁的、可复用的代码。每一个独立的组件通过 import 来引入自身的依赖,并 export 它想要暴露给其它模块的部分。结合 Babel 和 ES6,你可以利用 JavaScript 类 来实现更强大的模块化,而不用考虑它的工作原理。
有关模块的更多信息,请参阅 Preethi Kasreddy 这篇优秀的文章。
延伸阅读
via: https://blog.madewithenvy.com/getting-started-with-webpack-2-ed2b86c68783#.oozfpppao
作者:Drew Powers 译者:OneNewLife 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出