用数据科学搭建一个实时推荐引擎
编者注:本文是 2016 年 4 月 Nicole Whilte 在欧洲 GraphConnect 时所作。这儿我们快速回顾一下她所涉及的内容:
- 图数据库推荐基础
- 社会化推荐
- 相似性推荐
- 集群推荐
今天我们将要讨论的内容是数据科学和 图推荐 :
我在 Neo4j 任职已经两年了,但实际上我已经使用 Neo4j 和 Cypher 工作三年了。当我首次发现这个特别的 图数据库 的时候,我还是一个研究生,那时候我在奥斯丁的德克萨斯大学攻读关于社交网络的统计学硕士学位。
实时推荐引擎是 Neo4j 中最广泛的用途之一,也是使它如此强大并且容易使用的原因之一。为了探索这个东西,我将通过使用示例数据集来阐述如何将统计学方法并入这些引擎中。
第一个很简单 - 将 Cypher 用于社交推荐。接下来,我们将看一看相似性推荐,这涉及到可被计算的相似性度量,最后探索的是集群推荐。
图数据库推荐基础
下面的数据集包含所有达拉斯 Fort Worth 国际机场的餐饮场所,达拉斯 Fort Worth 国际机场是美国主要的机场枢纽之一:
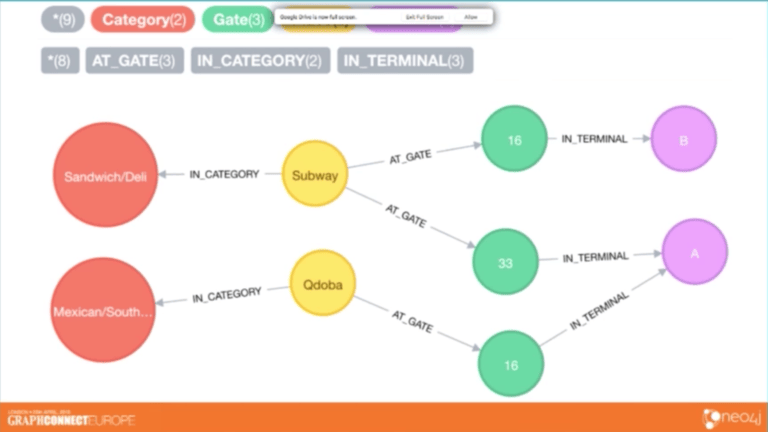
我们把节点标记成黄色并按照出入口和航站楼给它们的位置建模。同时我们也按照食物和饮料的主类别将地点分类,其中一些包括墨西哥食物、三明治、酒吧和烤肉。
让我们做一个简单的推荐。我们想要在机场的某一确定地点找到一种特定食物,大括号中的内容表示是的用户输入,它将进入我们的假想应用程序中。

这个英文句子表示成 Cypher 查询:

这将提取出该类别中用户所请求的所有地点、航站楼和出入口。然后我们可以计算出用户所在位置到出入口的准确距离,并以升序返回结果。再次说明,这个非常简单的 Cypher 推荐仅仅依据的是用户在机场中的位置。
社交推荐
让我们来看一下社交推荐。在我们的假想应用程序中,用户可以登录并且可以用和 Facebook 类似的方式标记自己“喜好”的地点,也可以在某地签到。
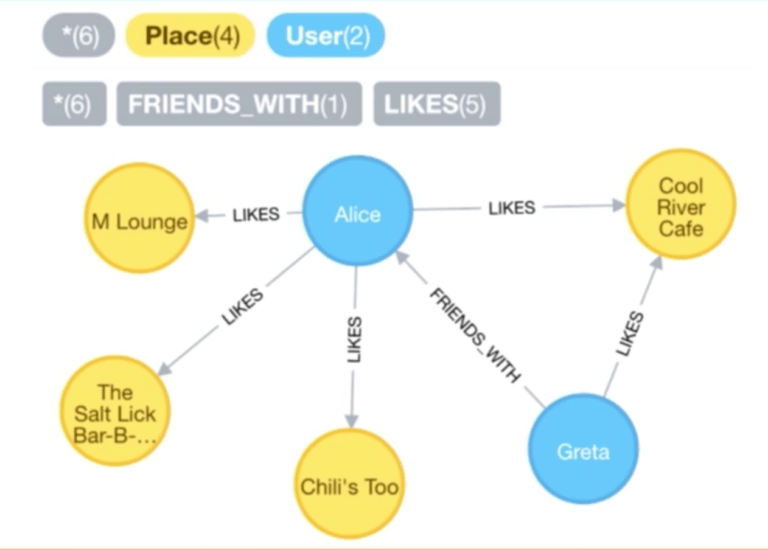
考虑位于我们所研究的第一个模型之上的数据模型,现在让我们在下面的分类中找到用户的朋友喜好的航站楼里面离出入口最近的餐饮场所:

MATCH 子句和我们第一次 Cypher 查询的 MATCH 子句相似,只是现在我们依据喜好和朋友来匹配:

前三行是完全一样的,但是现在要考虑的是那些登录的用户,我们想要通过 :FRIENDS_WITH 这一关系来找到他们的朋友。仅需通过在 Cypher 中增加一些行内容,我们现在已经把社交层面考虑到了我们的推荐引擎中。
再次说明,我们仅仅显示了用户明确请求的类别,并且这些类别中的地点与用户进入的地方是相同的航站楼。当然,我们希望按照登录并做出请求的用户来滤过这些目录,然后返回地点的名字、位置以及所在目录。我们也要显示出有多少朋友已经“喜好”那个地点以及那个地点到出入口的确切距离,然后在 RETURN 子句中同时返回所有这些内容。
相似性推荐
现在,让我们看一看相似性推荐引擎:
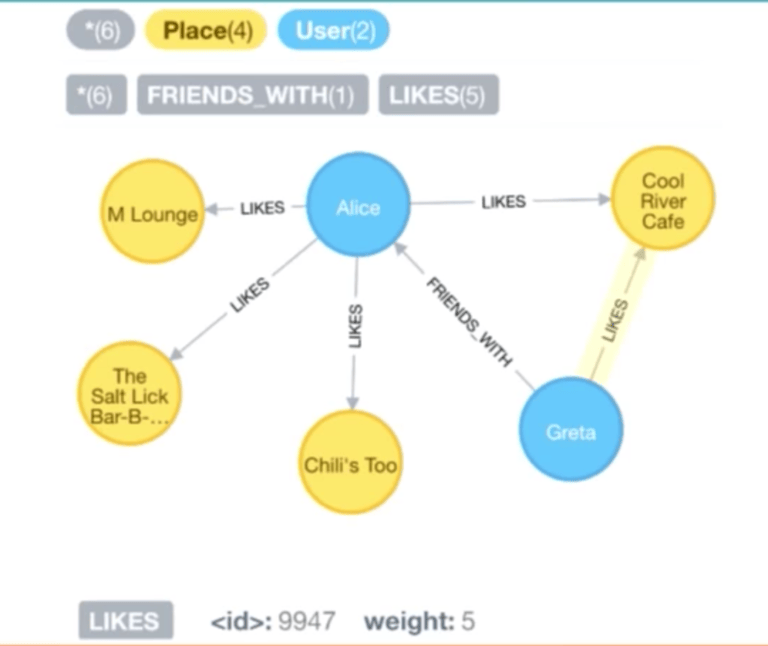
和前面的数据模型相似,用户可以标记“喜好”的地点,但是这一次他们可以用 1 到 10 的整数给地点评分。这是通过前期在 Neo4j 中增加一些属性到关系中建模实现的。
这将允许我们找到其他相似的用户,比如以上面的 Greta 和 Alice 为例,我们已经查询了他们共同喜好的地点,并且对于每一个地点,我们可以看到他们所设定的权重。大概地,我们可以通过他们的评分来确定他们之间的相似性大小。
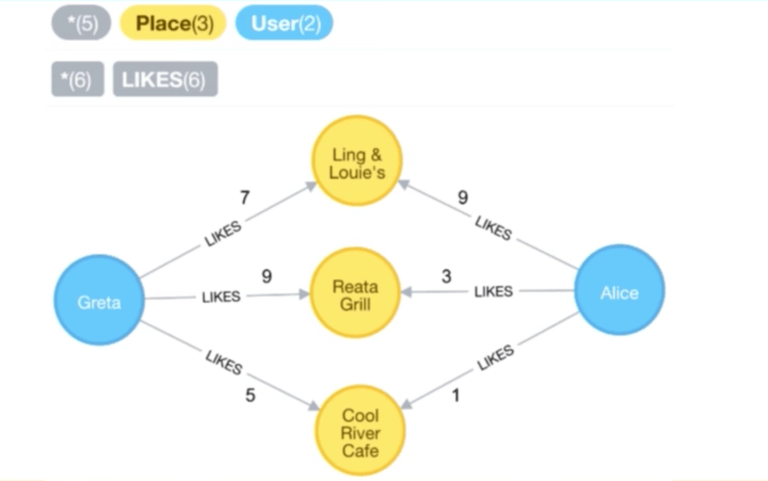
现在我们有两个向量:

现在让我们按照 欧几里得距离 的定义来计算这两个向量之间的距离:
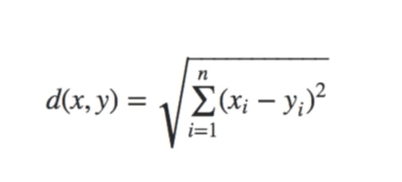
我们把所有的数字带入公式中计算,然后得到下面的相似度,这就是两个用户之间的“距离”:
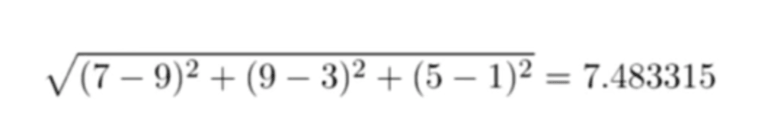
你可以很容易地在 Cypher 中计算两个特定用户的“距离”,特别是如果他们仅仅同时“喜好”一个很小的地点子集。再次说明,这儿我们依据两个用户 Alice 和 Greta 来进行匹配,并尝试去找到他们同时“喜好”的地点:

他们都有对最后找到的地点的 :LIKES 关系,然后我们可以在 Cypher 中很容易的计算出他们之间的欧几里得距离,计算方法为他们对各个地点评分差的平方求和再开平方根。
在两个特定用户的例子中上面这个方法或许能够工作。但是,在实时情况下,当你想要通过和实时数据库中的其他用户比较,从而由一架飞机上的一个用户推断相似用户时,这个方法就不一定能够工作。不用说,至少它不能够很好的工作。
为了找到解决这个问题的好方法,我们可以预先计算好距离并存入实际关系中:

当遇到一个很大的数据集时,我们需要成批处理这件事,在这个很小的示例数据集中,我们可以按照所有用户的 迪卡尔乘积 和他们共同“喜好”的地点来进行匹配。当我们使用 WHERE id(u1) < id(u2) 作为 Cypher 询问的一部分时,它只是来确定我们在左边和右边没有找到相同的对的一个技巧。
通过用户之间的欧几里得距离,我们创建了他们之间的一种关系,叫做 :DISTANCE,并且设置了一个叫做 euclidean 的欧几里得属性。理论上,我们可以也通过用户间的一些关系来存储其他相似度从而获取不同的相似度,因为在确定的环境下某些相似度可能比其他相似度更有用。
在 Neo4j 中,的确是对关系属性建模的能力使得完成像这样的事情无比简单。然而,实际上,你不会希望存储每一个可能存在的单一关系,因为你仅仅希望返回离他们“最近”的一些人。
因此你可以根据一些临界值来存入前几个,从而你不需要构建完整的连通图。这允许你完成一些像下面这样的实时的数据库查询,因为我们已经预先计算好了“距离”并存储在了关系中,在 Cypher 中,我们能够很快的攫取出数据。

在这个查询中,我们依据地点和类别来进行匹配:
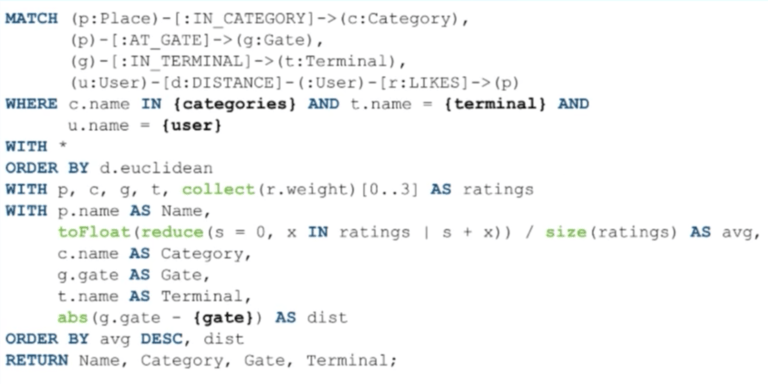
再次说明,前三行是相同的,除了登录用户以外,我们找出了和他们有 :DISTANCE 关系的用户。这是我们前面查看的关系产生的作用 - 实际上,你只需要存储处于前几位的相似用户 :DISTANCE 关系,因此你不需要在 MATCH 子句中攫取大量用户。相反,我们只攫取和那些用户“喜好”的地方有 :DISTANCE 关系的用户。
这允许我们用少许几行内容表达较为复杂的模型。我们也可以攫取 :LIKES 关系并把它放入到变量中,因为后面我们将使用这些权重来评分。
在这儿重要的是,我们可以依据“距离”大小将用户按照升序进行排序,因为这是一个距离测度。同时,我们想要找到用户间的最小距离因为距离越小表明他们的相似度最大。
通过其他按照欧几里得距离大小排序好的用户,我们得到用户评分最高的三个地点并按照用户的平均评分高低来推荐这些地点。换句话说,我们先找出一个活跃用户,然后依据其他用户“喜好”的地点找出和他最相似的其他用户,接下来按照这些相似用户的平均评分把那些地点排序在结果的集合中。
本质上,我们通过把所有评分相加然后除以收集的用户数目来计算出平均分,然后按照平均评分的升序进行排序。其次,我们按照出入口距离排序。假想地,我猜测应该会有交接点,因此你可以按照出入口距离排序然后再返回名字、类别、出入口和航站楼。
集群推荐
我们最后要讲的一个例子是集群推荐,在 Cypher 中,这可以被想像成一个作为临时解决方案的离线计算工作流。这可能完全基于在欧洲 GraphConnect 上宣布的新方法,但是有时你必须进行一些 Cypher 2.3 版本所没有的算法逼近。
在这儿你可以使用一些统计软件,把数据从 Neo4j 取出然后放入像 Apache Spark、R 或者 Python 这样的软件中。下面是一段把数据从 Neo4j 中取出的 R 代码,运行该程序,如果正确,写下程序返回结果的给 Neo4j,可以是一个属性、节点、关系或者一个新的标签。
通过持续把程序运行结果放入到图表中,你可以在一个和我们刚刚看到的查询相似的实时查询中使用它:

下面是用 R 来完成这件事的一些示例代码,但是你可以使用任何你最喜欢的软件来做这件事,比如 Python 或 Spark。你需要做的只是登录并连接到图表。
在下面的例子中,我基于用户的相似性把他们聚合起来。每个用户作为一个观察点,然后得到他们对每一个目录评分的平均值。

假定用户对酒吧类评分的方式和一般的评分方式相似。然后我攫取出喜欢相同类别中的地点的用户名、类别名、“喜好”关系的平均权重,比如平均权重这些信息,从而我可以得到下面这样一个表格:
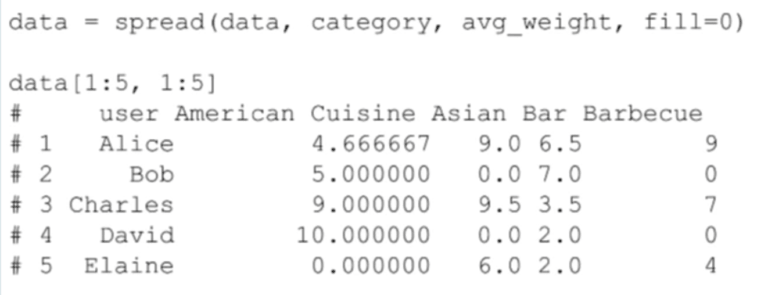
因为我们把每一个用户都作为一个观察点,所以我们必须巧妙的处理每一个类别中的数据,这些数据的每一个特性都是用户对该类中餐厅评分的平均权重。接下来,我们将使用这些数据来确定用户的相似性,然后我将使用 聚类 算法来确定在不同集群中的用户。
在 R 中这很直接:

在这个示例中我们使用 K-均值 聚类算法,这将使你很容易攫取集群分配。总之,我通过运行聚类算法然后分别得到每一个用户的集群分配。
Bob 和 David 在一个相同的集群中 - 他们在集群二中 - 现在我可以实时查看哪些用户被放在了相同的集群中。
接下来我把集群分配写入 CSV 文件中,然后存入图数据库:

我们只有用户和集群分配,因此 CSV 文件只有两列。 LOAD CSV 是 Cypher 中的内建语法,它允许你从一些其他文件路径或者 URL 调用 CSV ,并给它一个别名。接下来,我们将匹配图数据库中存在的用户,从 CSV 文件中攫取用户列然后合并到集群中。
我们在图表中创建了一个新的标签节点:Cluster ID, 这是由 K-平均聚类算法给出的。接下来我们创建用户和集群间的关系,通过创建这个关系,当我们想要找到在相同集群中的实际推荐用户时,就会很容易进行查询。
我们现在有了一个新的集群标签,在相同集群中的用户和那个集群存在关系。新的数据模型看起来像下面这样,它比我们前面探索的其他数据模型要更好:
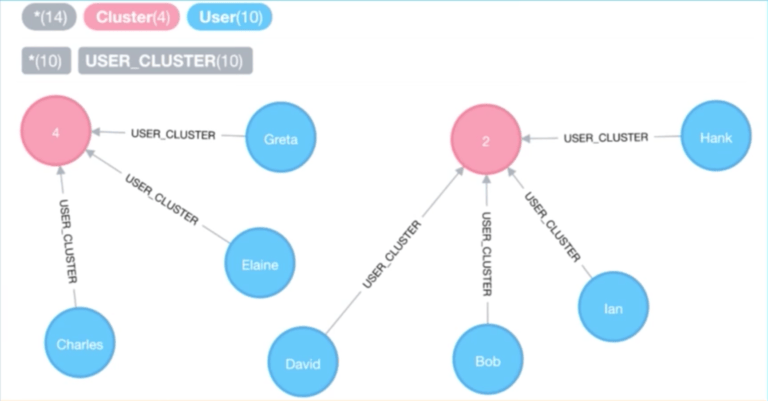
现在让我们考虑下面的查询:

通过这个 Cypher 查询,我们在更远处找到了在同一个集群中的相似用户。由于这个原因,我们删除了“距离”关系:

在这个查询中,我们取出已经登录的用户,根据用户-集群关系找到他们所在的集群,找到他们附近和他们在相同集群中的用户。
我们把这些用户分配到变量 c1 中,然后我们得到其他被我取别名为 neighbor 变量的用户,这些用户和那个相同集群存在着用户-集群关系,最后我们得到这些附近用户“喜好”的地点。再次说明,我把“喜好”放入了变量 r 中,因为我们需要从关系中攫取权重来对结果进行排序。
在这个查询中,我们所做的改变是,不使用相似性距离,而是攫取在相同集群中的用户,然后对类别、航站楼以及我们所攫取的登录用户进行声明。我们收集所有的权重:来自附近用户“喜好”地点的“喜好”关系,得到的类别,确定的距离值,然后把它们按升序进行排序并返回结果。
在这些例子中,我们可以进行一个相当复杂的处理并且将其放到图数据库中,然后我们就可以使用实时算法结果-聚类算法和集群分配的结果。
我们更喜欢的工作流程是更新这些集群分配,更新频率适合你自己就可以,比如每晚一次或每小时一次。当然,你可以根据直觉来决定多久更新一次这些集群分配是可接受的。
via: https://neo4j.com/blog/real-time-recommendation-engine-data-science/
作者:Nicole White 译者:ucasFL 校对:wxy