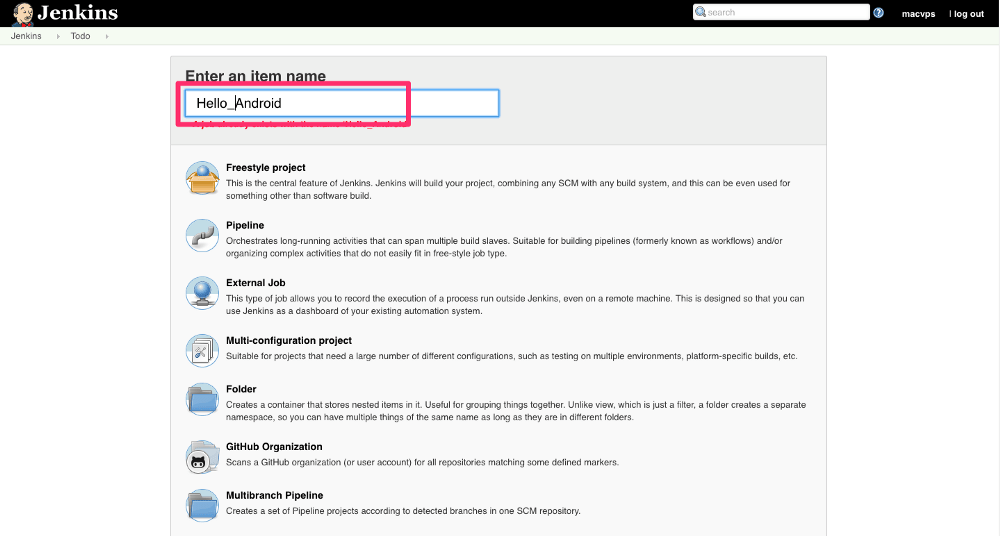
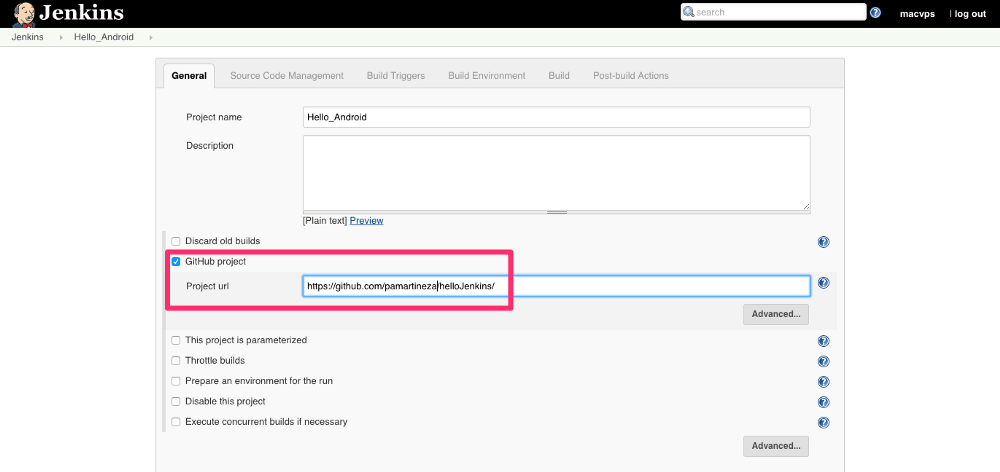
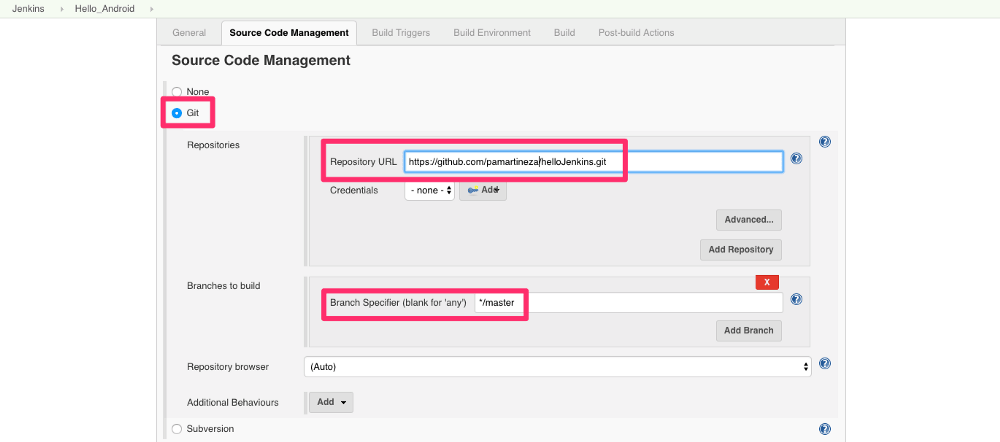
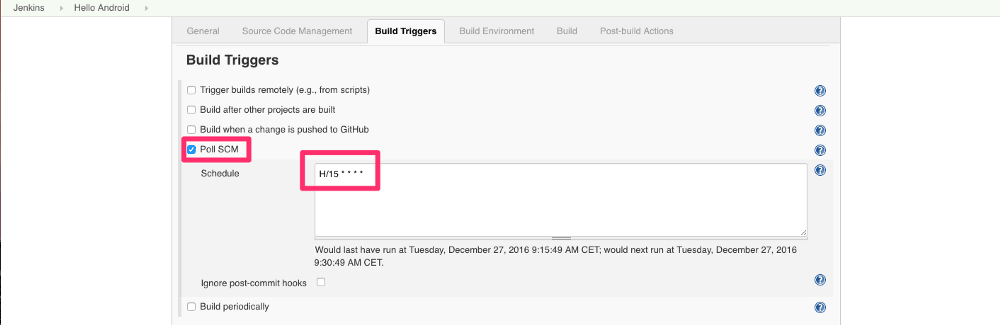
使用 Apex 和 Compose MongoDB 开发 serverless

Apex 是一个将开发和部署 AWS Lambda 函数的过程打包了的工具。它提供了一个本地命令行工具来创建安全上下文、部署函数,甚至追踪云端日志。由于 AWS Lambda 服务将函数看成独立的单元,Apex 提供了一个框架层将一系列函数作为一个项目。另外,它将服务拓展到不仅仅是 Java,Javascript 和 Ptyhon 语言,甚至包括 Go 语言。
两年前 Express (基本上是 NodeJS 事实标准上的网络框架层)的作者,离开了 Node 社区,而将其注意力转向 Go (谷歌创造的后端服务语言),以及 Lambda(由 AWS 提供的函数即服务)。尽管一个开发者的行为无法引领一股潮流,但是来看看他正在做的名叫 Apex 项目会很有趣,因为它可能预示着未来很大一部分网络开发的改变。
什么是 Lambda?
如今,人们如果不能使用自己的硬件,他们会选择付费使用一些云端的虚拟服务器。在云上,他们会部署一个完整的协议栈如 Node、Express,和一个自定义应用。或者如果他们更进一步使用了诸如 Heroku 或者 Bluemix 之类的新玩意,也可能在某些已经预配置好 Node 的容器中仅仅通过部署应用代码来部署他们完整的应用。
在这个抽象的阶梯上的下一步是单独部署函数到云端而不是一个完整的应用。这些函数之后可以被一大堆外部事件触发。例如,AWS 的 API 网关服务可以将代理 HTTP 请求作为触发函数的事件,而函数即服务(FaaS)的供应方根据要求执行匹配的函数。
Apex 起步
Apex 是一个将 AWS 命令行接口封装起来的命令行工具。因此,开始使用 Apex 的第一步就是确保你已经安装和配置了从 AWS 获取的命令行工具(详情请查看 AWS CLI Getting Started 或者 Apex documentation)。
接下来,安装 Apex:
curl https://raw.githubusercontent.com/apex/apex/master/install.sh | sh
然后为你的新项目创建一个目录并运行:
apex init

这步会配置好一些必须的安全策略,并且将项目名字附在函数名后,因为 Lambda 使用扁平化的命名空间。同时它也会创建一些配置文件和默认的 “Hello World" 风格的 Javascript 函数的 functions 目录。

Apex/Lambda 一个非常友好的特性是创建函数非常直观。创建一个以你函数名为名的新目录,然后在其中创建项目。如果想要使用 Go 语言,你可以创建一个叫 simpleGo 的目录然后在其中创建一个小型的 main 函数:
// serverless/functions/simpleGo/main.go
package main
import (
"encoding/json"
"github.com/apex/go-apex"
"log"
)
type helloEvent struct {
Hello string `json:"hello"`
}
func main() {
apex.HandleFunc(func(event json.RawMessage, ctx *apex.Context) (interface{}, error) {
var h helloEvent
if err := json.Unmarshal(event, &h); err != nil {
return nil, err
}
log.Print("event.hello:", h.Hello)
return h, nil
})
}
Node 是 Lambda 所支持的运行环境,Apex 使用 NodeJS shim 来调用由上述程序产生的二进制文件。它将 event 传入二进制文件的 STDIN,将从二进制返回的 STDOUT 作为 value。通过 STDERR 来显示日志。apex.HandleFunc 用来为你管理所有的管道。事实上在 Unix 惯例里这是一个非常简单的解决方案。你甚至可以通过在本地命令行执行 go run main.go 来测试它。

通过 Apex 向云端部署稍显琐碎:

注意,这将会对你的函数指定命名空间,控制版本,甚至为其他多开发环境如 staging 和 production配置env。
通过 apex invoke 在云端执行也比较琐碎:

当然我们也可以追踪一些日志:

这些是从 AWS CloudWatch 返回的结果。它们都在 AWS 的 UI 中可见,但是当在另一个终端参照此结果来署它会更快。
窥探内部的秘密
来看看它内部到底部署了什么很具有指导性。Apex 将 shim 和所有需要用来运行函数的东西打包起来。另外,它会提前做好配置如入口与安全条例:

Lambda 服务实际上接受一个包含所有依赖的 zip 压缩包,它会被部署到服务器来执行指定的函数。我们可以使用 apex build <functionName> 在本地创建一个压缩包用来在以后解压以探索。

这里的 _apex_index.js handle 函数是原始的入口。它会配置好一些环境变量然后进入 index.js。
而 index.js 孕育一个 main Go 的二进制文件的子进程并且将所有关联联结在一起。
使用 mgo 继续深入
mgo 是 Go 语言的 MongoDB 驱动。使用 Apex 来创建一个函数来连接到 Compose 的 MongoDB 就如同我们已经学习过的 simpleGo 函数一样直观。这里我们会通过增加一个 mgoGo 目录和另一个 main.go 来创建一个新函数。
// serverless/functions/mgoGo/main.go
package main
import (
"crypto/tls"
"encoding/json"
"github.com/apex/go-apex"
"gopkg.in/mgo.v2"
"log"
"net"
)
type person struct {
Name string `json:"name"`
Email string `json:"email"`
}
func main() {
apex.HandleFunc(func(event json.RawMessage, ctx *apex.Context) (interface{}, error) {
tlsConfig := &tls.Config{}
tlsConfig.InsecureSkipVerify = true
//connect URL:
// "mongodb://<username>:<password>@<hostname>:<port>,<hostname>:<port>/<db-name>
dialInfo, err := mgo.ParseURL("mongodb://apex:[email protected]:15188, aws-us-west-2-portal.1.dblayer.com:15188/signups")
dialInfo.DialServer = func(addr *mgo.ServerAddr) (net.Conn, error) {
conn, err := tls.Dial("tcp", addr.String(), tlsConfig)
return conn, err
}
session, err := mgo.DialWithInfo(dialInfo)
if err != nil {
log.Fatal("uh oh. bad Dial.")
panic(err)
}
defer session.Close()
log.Print("Connected!")
var p person
if err := json.Unmarshal(event, &p); err != nil {
log.Fatal(err)
}
c := session.DB("signups").C("people")
err = c.Insert(&p)
if err != nil {
log.Fatal(err)
}
log.Print("Created: ", p.Name," - ", p.Email)
return p, nil
})
}
发布部署,我们可以通过使用正确类型的事件来模拟调用了一个 API:

最终结果是 insert 到在 Compose 之上 的 MongoDB 中。

还有更多……
尽管目前我们已经涉及了 Apex 的方方面面,但是仍然有很多值得我们去探索的东西。它还和 Terraform 进行了整合。如果你真的希望,你可以发布一个多语言项目包括 Javascript、Java、Python 以及 Go。你也可以为开发、演示以及产品环境配置多种环境。你可以调整运行资源如调整存储大小和运行时间来调整成本。而且你可以把函数勾连到 API 网关上来传输一个 HTTP API 或者使用一些类似 SNS (简单通知服务)来为云端的函数创建管道。
和大多数事物一样,Apex 和 Lambda 并不是在所有场景下都完美。 但是,在你的工具箱中增加一个完全不需要你来管理底层建设的工具完全没有坏处。
作者简介:
Hays Hutton 喜欢写代码并写一些与其相关的东西。喜欢这篇文章?请前往Hays Hutton’s author page 继续阅读其他文章。
via: https://www.compose.com/articles/go-serverless-with-apex-and-composes-mongodb/
作者:Hays Hutton 译者:xiaow6 校对:wxy