通过 ncurses 在终端创建一个冒险游戏
怎样使用 curses 函数读取键盘并操作屏幕。
我之前的文章介绍了 ncurses 库,并提供了一个简单的程序展示了一些将文本放到屏幕上的 curses 函数。在接下来的文章中,我将介绍如何使用其它的 curses 函数。
探险
当我逐渐长大,家里有了一台苹果 II 电脑。我和我兄弟正是在这台电脑上自学了如何用 AppleSoft BASIC 写程序。我在写了一些数学智力游戏之后,继续创造游戏。作为 80 年代的人,我已经是龙与地下城桌游的粉丝,在游戏中角色扮演一个追求打败怪物并在陌生土地上抢掠的战士或者男巫,所以我创建一个基本的冒险游戏也在情理之中。
AppleSoft BASIC 支持一种简洁的特性:在标准分辨率图形模式(GR 模式)下,你可以检测屏幕上特定点的颜色。这为创建一个冒险游戏提供了捷径。比起创建并更新周期性传送到屏幕的内存地图,我现在可以依赖 GR 模式为我维护地图,我的程序还可以在玩家的角色(LCTT 译注:此处 character 双关一个代表玩家的角色,同时也是一个字符)在屏幕四处移动的时候查询屏幕。通过这种方式,我让电脑完成了大部分艰难的工作。因此,我的自顶向下的冒险游戏使用了块状的 GR 模式图形来展示我的游戏地图。
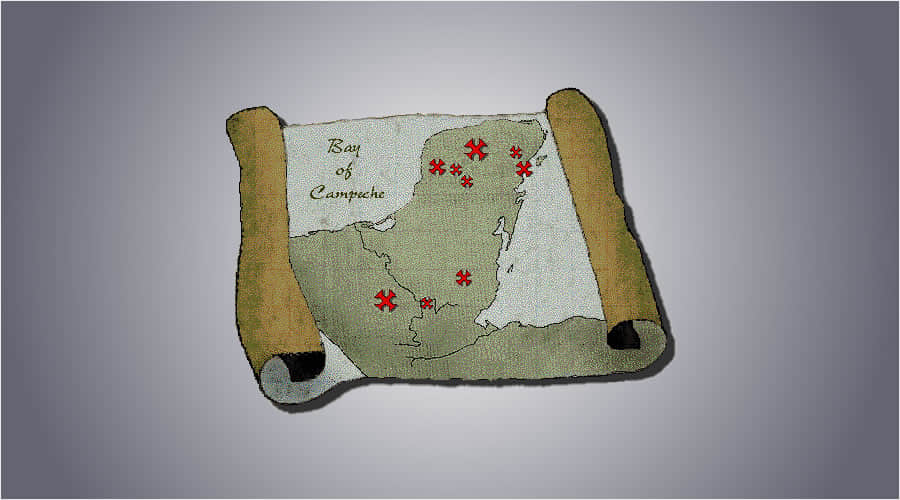
我的冒险游戏使用了一张简单的地图,上面有一大片绿地伴着山脉从中间蔓延向下和一个在左上方的大湖。我要粗略地为桌游战役绘制这个地图,其中包含一个允许玩家穿过到远处的狭窄通道。

图 1. 一个有湖和山的简单桌游地图
你可以用 curses 绘制这个地图,并用字符代表草地、山脉和水。接下来,我描述怎样使用 curses 那样做,以及如何在 Linux 终端创建和进行类似的一个冒险游戏。
构建程序
在我的上一篇文章,我提到了大多数 curses 程序以相同的一组指令获取终端类型和设置 curses 环境:
initscr();
cbreak();
noecho();
在这个程序,我添加了另外的语句:
keypad(stdscr, TRUE);
这里的 TRUE 标志允许 curses 从用户终端读取小键盘和功能键。如果你想要在你的程序中使用上下左右方向键,你需要使用这里的 keypad(stdscr, TRUE)。
这样做了之后,你现在可以开始在终端屏幕上绘图了。curses 函数包括了一系列在屏幕上绘制文本的方法。在我之前的文章中,我展示了 addch() 和 addstr() 函数以及在添加文本之前先移动到指定屏幕位置的对应函数 mvaddch() 和 mvaddstr()。为了在终端上创建这个冒险游戏的地图,你可以使用另外一组函数:vline() 和 hline(),以及它们对应的函数 mvvline() 和 mvhline()。这些 mv 函数接受屏幕坐标、一个要绘制的字符和要重复此字符的次数的参数。例如,mvhline(1, 2, '-', 20) 将会绘制一条开始于第一行第二列并由 20 个横线组成的线段。
为了以编程方式绘制地图到终端屏幕上,让我们先定义这个 draw_map() 函数:
#define GRASS ' '
#define EMPTY '.'
#define WATER '~'
#define MOUNTAIN '^'
#define PLAYER '*'
void draw_map(void)
{
int y, x;
/* 绘制探索地图 */
/* 背景 */
for (y = 0; y < LINES; y++) {
mvhline(y, 0, GRASS, COLS);
}
/* 山和山道 */
for (x = COLS / 2; x < COLS * 3 / 4; x++) {
mvvline(0, x, MOUNTAIN, LINES);
}
mvhline(LINES / 4, 0, GRASS, COLS);
/* 湖 */
for (y = 1; y < LINES / 2; y++) {
mvhline(y, 1, WATER, COLS / 3);
}
}
在绘制这副地图时,记住填充大块字符到屏幕所使用的 mvvline() 和 mvhline() 函数。我绘制从 0 列开始的字符水平线(mvhline)以创建草地区域,直到占满整个屏幕的高度和宽度。我绘制从 0 行开始的多条垂直线(mvvline)在此上添加了山脉,绘制单行水平线添加了一条山道(mvhline)。并且,我通过绘制一系列短水平线(mvhline)创建了湖。这种绘制重叠方块的方式看起来似乎并没有效率,但是记住在我们调用 refresh() 函数之前 curses 并不会真正更新屏幕。
绘制完地图,创建游戏就还剩下进入循环让程序等待用户按下上下左右方向键中的一个然后让玩家图标正确移动了。如果玩家想要移动的地方是空的,就应该允许玩家到那里。
你可以把 curses 当做捷径使用。比起在程序中实例化一个版本的地图并复制到屏幕这么复杂,你可以让屏幕为你跟踪所有东西。inch() 函数和相关联的 mvinch() 函数允许你探测屏幕的内容。这让你可以查询 curses 以了解玩家想要移动到的位置是否被水填满或者被山阻挡。这样做你需要一个之后会用到的一个帮助函数:
int is_move_okay(int y, int x)
{
int testch;
/* 如果要进入的位置可以进入,返回 true */
testch = mvinch(y, x);
return ((testch == GRASS) || (testch == EMPTY));
}
如你所见,这个函数探测行 x、列 y 并在空间未被占据的时候返回 true,否则返回 false。
这样我们写移动循环就很容易了:从键盘获取一个键值然后根据是上下左右键移动用户字符。这里是一个这种循环的简单版本:
do {
ch = getch();
/* 测试输入的值并获取方向 */
switch (ch) {
case KEY_UP:
if ((y > 0) && is_move_okay(y - 1, x)) {
y = y - 1;
}
break;
case KEY_DOWN:
if ((y < LINES - 1) && is_move_okay(y + 1, x)) {
y = y + 1;
}
break;
case KEY_LEFT:
if ((x > 0) && is_move_okay(y, x - 1)) {
x = x - 1;
}
break;
case KEY_RIGHT
if ((x < COLS - 1) && is_move_okay(y, x + 1)) {
x = x + 1;
}
break;
}
}
while (1);
为了在游戏中使用这个循环,你需要在循环里添加一些代码来启用其它的键(例如传统的移动键 WASD),以提供让用户退出游戏和在屏幕上四处移动的方法。这里是完整的程序:
/* quest.c */
#include
#include
#define GRASS ' '
#define EMPTY '.'
#define WATER '~'
#define MOUNTAIN '^'
#define PLAYER '*'
int is_move_okay(int y, int x);
void draw_map(void);
int main(void)
{
int y, x;
int ch;
/* 初始化curses */
initscr();
keypad(stdscr, TRUE);
cbreak();
noecho();
clear();
/* 初始化探索地图 */
draw_map();
/* 在左下角初始化玩家 */
y = LINES - 1;
x = 0;
do {
/* 默认获得一个闪烁的光标--表示玩家字符 */
mvaddch(y, x, PLAYER);
move(y, x);
refresh();
ch = getch();
/* 测试输入的键并获取方向 */
switch (ch) {
case KEY_UP:
case 'w':
case 'W':
if ((y > 0) && is_move_okay(y - 1, x)) {
mvaddch(y, x, EMPTY);
y = y - 1;
}
break;
case KEY_DOWN:
case 's':
case 'S':
if ((y < LINES - 1) && is_move_okay(y + 1, x)) {
mvaddch(y, x, EMPTY);
y = y + 1;
}
break;
case KEY_LEFT:
case 'a':
case 'A':
if ((x > 0) && is_move_okay(y, x - 1)) {
mvaddch(y, x, EMPTY);
x = x - 1;
}
break;
case KEY_RIGHT:
case 'd':
case 'D':
if ((x < COLS - 1) && is_move_okay(y, x + 1)) {
mvaddch(y, x, EMPTY);
x = x + 1;
}
break;
}
}
while ((ch != 'q') && (ch != 'Q'));
endwin();
exit(0);
}
int is_move_okay(int y, int x)
{
int testch;
/* 当空间可以进入时返回true */
testch = mvinch(y, x);
return ((testch == GRASS) || (testch == EMPTY));
}
void draw_map(void)
{
int y, x;
/* 绘制探索地图 */
/* 背景 */
for (y = 0; y < LINES; y++) {
mvhline(y, 0, GRASS, COLS);
}
/* 山脉和山道 */
for (x = COLS / 2; x < COLS * 3 / 4; x++) {
mvvline(0, x, MOUNTAIN, LINES);
}
mvhline(LINES / 4, 0, GRASS, COLS);
/* 湖 */
for (y = 1; y < LINES / 2; y++) {
mvhline(y, 1, WATER, COLS / 3);
}
}
在完整的程序清单中,你可以看见使用 curses 函数创建游戏的完整布置:
- 初始化 curses 环境。
- 绘制地图。
- 初始化玩家坐标(左下角)
循环:
- 绘制玩家的角色。
- 从键盘获取键值。
- 对应地上下左右调整玩家坐标。
- 重复。
- 完成时关闭curses环境并退出。
开始玩
当你运行游戏时,玩家的字符在左下角初始化。当玩家在游戏区域四处移动的时候,程序创建了“一串”点。这样可以展示玩家经过了的点,让玩家避免经过不必要的路径。
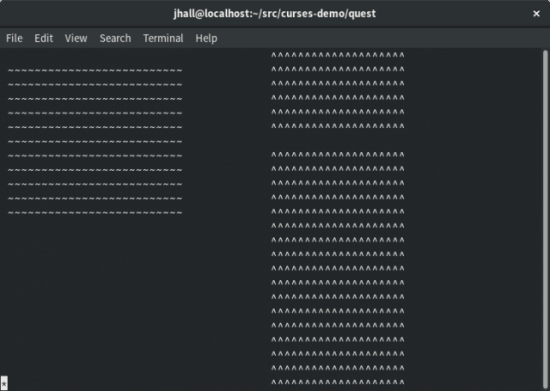
图 2. 初始化在左下角的玩家
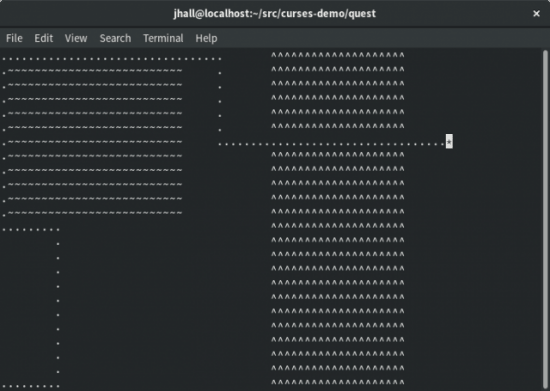
图 3. 玩家可以在游戏区域四处移动,例如湖周围和山的通道
为了创建上面这样的完整冒险游戏,你可能需要在他/她的角色在游戏区域四处移动的时候随机创建不同的怪物。你也可以创建玩家可以发现在打败敌人后可以掠夺的特殊道具,这些道具应能提高玩家的能力。
但是作为起点,这是一个展示如何使用 curses 函数读取键盘和操纵屏幕的好程序。
下一步
这是一个如何使用 curses 函数更新和读取屏幕和键盘的简单例子。按照你的程序需要做什么,curses 可以做得更多。在下一篇文章中,我计划展示如何更新这个简单程序以使用颜色。同时,如果你想要学习更多 curses,我鼓励你去读位于 Linux 文档计划的 Pradeep Padala 写的如何使用 NCURSES 编程。
via: http://www.linuxjournal.com/content/creating-adventure-game-terminal-ncurses