为何选择文字用户界面(TUI)?
许多人每日都在使用终端,因此, 文字用户界面 (TUI)逐渐显示出其价值。它能减少用户输入命令时的误差,让终端操作更高效,提高生产力。
以我的个人使用情况为例:我每日会通过家用电脑远程连接到我使用 Linux 系统的实体 PC。所有的远程网络连接都通过私有 VPN 加密保护。然而,当我需要频繁重复输入命令进行连接时,这种经历实在令人烦躁。
于是,我创建了下面这个 Bash 函数,从而有所改进:
export REMOTE_RDP_USER="myremoteuser"
function remote_machine() {
/usr/bin/xfreerdp /cert-ignore /sound:sys:alsa /f /u:$REMOTE_RDP_USER /v:$1 /p:$2
}
但后来,我发现自己还是频繁地执行下面这条命令(在一行中):
remote_pass=(/bin/cat/.mypassfile) remote_machine $remote_machine $remote_pass
这太烦了。更糟糕的是,我的密码被明文存储在我的电脑上(我虽然使用了加密驱动器,但这点依然令人不安)。
因此,我决定投入一些时间,编写一个实用的脚本,从而更好地满足我的基本需求。
我需要哪些信息才能连接到远程桌面?
实际上,要连接到远程桌面,你只需提供少量信息。这些信息需要进行结构化处理,所以一个简单的 JSON 文件就能够满足要求:
{"machines": [
{
"name": "machine1.domain.com",
"description": "Personal-PC"
},
{
"name": "machine2.domain.com",
"description": "Virtual-Machine"
}
],
"remote_user": "MYUSER@DOMAIN",
"title" : "MY COMPANY RDP connection"
}
尽管在各种配置文件格式中,JSON 并非最佳选择(例如,它不支持注解),但是 Linux 提供了许多工具通过命令行方式解析 JSON 内容。其中,特别值得一提的工具就是 jq。下面我要向你展示如何利用它来提取机器列表:
/usr/bin/jq --compact-output --raw-output '.machines[]| .name' \
$HOME/.config/scripts/kodegeek_rdp.json) \
"machine1.domain.com" "machine2.domain.com"
jq 的文档可以在 这里 找到。另外,你也可以直接将你的 JSON 文件复制粘贴到 jq play,试用你的表达式,然后在你的脚本中使用这些表达式。
既然已经准备好了连接远程计算机所需的所有信息,那现在就让我们来创建一个美观实用的 TUI 吧。
Dialog 的帮助
Dialog 是那些你可能希望早些认识的、被低评估的 Linux 工具之一。你可以利用它构建出一个井然有序、简介易懂,并且完美适用于你终端的用户界面。
比如,我可以创建一个包含我喜欢的编程语言的简单的复选框列表,且默认选择 Python:
dialog --clear --checklist "Favorite programming languages:" 10 30 7\
1 Python on 2 Java off 3 Bash off 4 Perl off 5 Ruby off
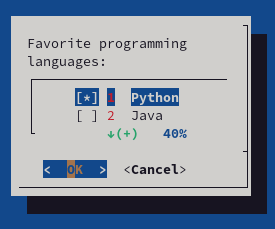
我们通过这条命令向 dialog 下达了几个指令:
- 清除屏幕(所有选项都以
-- 开头) - 创建一个带有标题的复选框(第一个位置参数)
- 决定窗口尺寸(高度、宽度和列表高度,共 3 个参数)
- 列表中的每条选项都由一个标签和一个值组成。
惊人的是,仅仅一行代码,就带来了简洁直观和视觉友好的选择列表。
关于 dialog 的详细文档,你可以在 这里 阅读。
整合所有元素:使用 Dialog 和 JQ 编写 TUI
我编写了一个 TUI,它使用 jq 从我的 JSON 文件中提取配置详细信息,并且使用 dialog 来组织流程。每次运行,我都会要求输入密码,并将其保存在一个临时文件中,脚本使用后便会删除这个临时文件。
这个脚本非常基础,但它更安全,也使我能够专注于更重要的任务 ?
那么 脚本 看起来是怎样的呢?下面是代码:
#!/bin/bash
# Author Jose Vicente Nunez
# Do not use this script on a public computer. It is not secure...
# https://invisible-island.net/dialog/
# Below some constants to make it easier to handle Dialog
# return codes
: ${DIALOG_OK=0}
: ${DIALOG_CANCEL=1}
: ${DIALOG_HELP=2}
: ${DIALOG_EXTRA=3}
: ${DIALOG_ITEM_HELP=4}
: ${DIALOG_ESC=255}
# Temporary file to store sensitive data. Use a 'trap' to remove
# at the end of the script or if it gets interrupted
declare tmp_file=$(/usr/bin/mktemp 2>/dev/null) || declare tmp_file=/tmp/test$$
trap "/bin/rm -f $tmp_file" QUIT EXIT INT
/bin/chmod go-wrx ${tmp_file} > /dev/null 2>&1
:<<DOC
Extract details like title, remote user and machines using jq from the JSON file
Use a subshell for the machine list
DOC
declare TITLE=$(/usr/bin/jq --compact-output --raw-output '.title' $HOME/.config/scripts/kodegeek_rdp.json)|| exit 100
declare REMOTE_USER=$(/usr/bin/jq --compact-output --raw-output '.remote_user' $HOME/.config/scripts/kodegeek_rdp.json)|| exit 100
declare MACHINES=$(
declare tmp_file2=$(/usr/bin/mktemp 2>/dev/null) || declare tmp_file2=/tmp/test$$
# trap "/bin/rm -f $tmp_file2" 0 1 2 5 15 EXIT INT
declare -a MACHINE_INFO=$(/usr/bin/jq --compact-output --raw-output '.machines[]| join(",")' $HOME/.config/scripts/kodegeek_rdp.json > $tmp_file2)
declare -i i=0
while read line; do
declare machine=$(echo $line| /usr/bin/cut -d',' -f1)
declare desc=$(echo $line| /usr/bin/cut -d',' -f2)
declare toggle=off
if [ $i -eq 0 ]; then
toggle=on
((i=i+1))
fi
echo $machine $desc $toggle
done < $tmp_file2
/bin/cp /dev/null $tmp_file2
) || exit 100
# Create a dialog with a radio list and let the user select the
# remote machine
/usr/bin/dialog \
--clear \
--title "$TITLE" \
--radiolist "Which machine do you want to use?" 20 61 2 \
$MACHINES 2> ${tmp_file}
return_value=$?
# Handle the return codes from the machine selection in the
# previous step
export remote_machine=""
case $return_value in
$DIALOG_OK)
export remote_machine=$(/bin/cat ${tmp_file})
;;
$DIALOG_CANCEL)
echo "Cancel pressed.";;
$DIALOG_HELP)
echo "Help pressed.";;
$DIALOG_EXTRA)
echo "Extra button pressed.";;
$DIALOG_ITEM_HELP)
echo "Item-help button pressed.";;
$DIALOG_ESC)
if test -s $tmp_file ; then
/bin/rm -f $tmp_file
else
echo "ESC pressed."
fi
;;
esac
# No machine selected? No service ...
if [ -z "${remote_machine}" ]; then
/usr/bin/dialog \
--clear \
--title "Error, no machine selected?" --clear "$@" \
--msgbox "No machine was selected!. Will exit now..." 15 30
exit 100
fi
# Send 4 packets to the remote machine. I assume your network
# administration allows ICMP packets
# If there is an error show message box
/bin/ping -c 4 ${remote_machine} >/dev/null 2>&1
if [ $? -ne 0 ]; then
/usr/bin/dialog \
--clear \
--title "VPN issues or machine is off?" --clear "$@" \
--msgbox "Could not ping ${remote_machine}. Time to troubleshoot..." 15 50
exit 100
fi
# Remote machine is visible, ask for credentials and handle user
# choices (like password with a password box)
/bin/rm -f ${tmp_file}
/usr/bin/dialog \
--title "$TITLE" \
--clear \
--insecure \
--passwordbox "Please enter your Windows password for ${remote_machine}\n" 16 51 2> $tmp_file
return_value=$?
case $return_value in
$DIALOG_OK)
# We have all the information, try to connect using RDP protocol
/usr/bin/mkdir -p -v $HOME/logs
/usr/bin/xfreerdp /cert-ignore /sound:sys:alsa /f /u:$REMOTE_USER /v:${remote_machine} /p:$(/bin/cat ${tmp_file})| \
/usr/bin/tee $HOME/logs/$(/usr/bin/basename $0)-$remote_machine.log
;;
$DIALOG_CANCEL)
echo "Cancel pressed.";;
$DIALOG_HELP)
echo "Help pressed.";;
$DIALOG_EXTRA)
echo "Extra button pressed.";;
$DIALOG_ITEM_HELP)
echo "Item-help button pressed.";;
$DIALOG_ESC)
if test -s $tmp_file ; then
/bin/rm -f $tmp_file
else
echo "ESC pressed."
fi
;;
esac
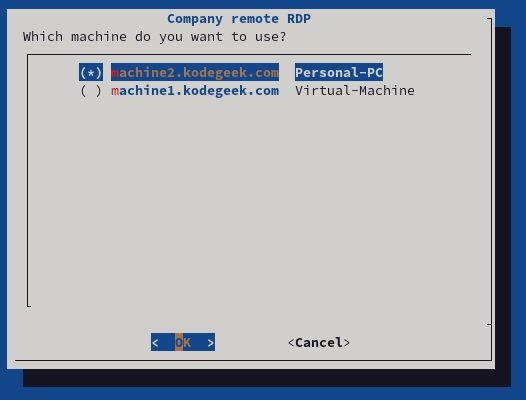
你从代码中可以看出,dialog 预期的是位置参数,并且允许你在变量中捕获用户的回应。这实际上使其成为编写文本用户界面的 Bash 扩展。
上述的小例子只涵盖了一些部件的使用,其实还有更多的文档在 官方 dialog 网站上。
Dialog 和 JQ 是最好的选择吗?
实现这个功能可以有很多方法(如 Textual,Gnome 的 Zenity,Python 的 TKinker等)。我只是想向你展示一种高效的方式——仅用 100 行代码就完成了这项任务。
确实,它并不完美。更具体地讲,它与 Bash 的深度集成使得代码有些冗长,但仍然保持了易于调试和维护的特性。相比于反复复制粘贴长长的命令,这无疑是一个更好的选择。
最后,如果你喜欢在 Bash 中使用 jq 处理 JSON,那么你会对这个 jq 配方的精彩集合 感兴趣的。
(题图:MJ/a9b7f60a-02ec-4d3f-88ae-2321f49ac0e1)
via: https://fedoramagazine.org/writing-useful-terminal-tui-on-linux-with-dialog-and-jq/
作者:Jose Nunez 选题:lujun9972 译者:ChatGPT 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出