详解使用 fastboot 为 Android 刷入原厂镜像
如果你的手机有一个解锁的 bootloader 的话,你可以用 fastboot 命令来刷入原厂镜像。听起来这好像是外行弄不懂的东西,但是当你需要升级被 root 过的设备,修理坏掉的手机,恢复到原生系统,或者是比别人更早的享受 Android 更新时,它可是最好的办法。
和 ADB 类似,fastboot 是一个强大的 Android 命令行工具。这听起来可能会很恐怖 —— 别担心,一旦你了解了它,你就会知道 Android 的内部工作原理,以及如何解决最常见的问题。
关于三星设备的注释
下面的指南对于 Nexus、Pixel、HTC 以及 Motorola 的大多数设备,以及其他众多厂商的手机和平板电脑都适用。但是,三星的设备有自己的刷机软件,所以你的 Galaxy 设备并不支持 Fastboot。对于三星的设备,最好使用 Odin 来进行刷机工作,我们在下文的链接中提供了相关指南。
第一步 在你的电脑上安装 ADB 和 Fastboot
首先,你需要在你的电脑上安装 ADB 和 Fastboot,只有有了它们你才能使用 Fastboot 命令刷入镜像。网上有不少“一键安装版”或者“绿色版”的 ADB 和 Fastboot,但是我不建议安装这样的版本,它们没有官方版本更新那么快,所以可能不会完全兼容新版设备。
你最好从 Google 上安装 Android SDK Tools。这才是“真正的” ADB 和 Fastboot。安装 SDK Tools 可能需要一点时间,不过这等待是值得的。在下面的 方法 1 中,我会说明在 Windows, Mac,以及 Linux 中安装这个软件的方法,所以可以跳转到那里开始。
第二步 OEM 解锁
为了能够使用 Fastboot 刷入镜像,你需要解锁你设备的 bootloader。如果你已经解锁,你可以跳过这步到第三步。
如果你的设备的 Android 版本在 6.0 及以上的话,在你解锁 bootloader 之前,你还需要开启一项设置。首先你需要开启 开发者选项 。开启之后,进入“开发者选项菜单”,然后开启 “OEM 解锁” 选项。之后就可以进行下一步了。
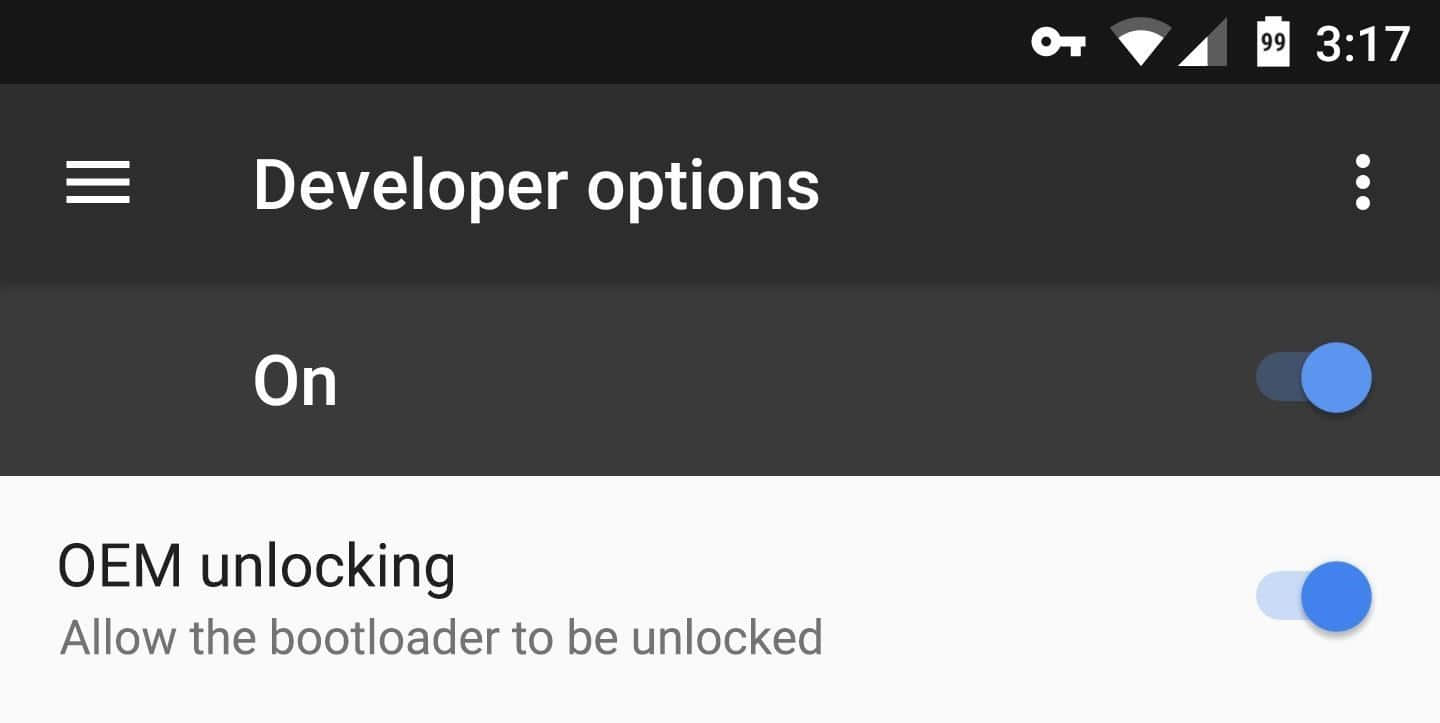
如果你的设备没有这个选项,那么你的设备的 Android 版本可能不是 6.0 或以上。如果这个选项存在但是是灰色的,这就意味着你的 bootloader 不能解锁,也就是说你不能使用 Fastboot 给你的手机刷入镜像。
第三步 进入 Bootloader 模式
在使用 Fastboot 软件之前,你还需要让你的设备进入 bootloader 模式。具体进入方式与你的设备有关。
对于大多数手机,你需要先完全关闭你的手机。在屏幕黑掉以后,同时按住开机键和音量向下键大约 10 秒。
如果这不起效的话,关掉手机,按住音量降低键。然后把手机用 USB 数据线连到电脑上,等上几秒钟。
如果还不起效的话,改按音量升高键,再试试第二种方法。
很快你就会看见像这样的 bootloader 界面:

看到这个界面之后,确保你的设备已经连接到电脑上。之后的工作就都是在电脑上完成了,把手机放在那里就成。
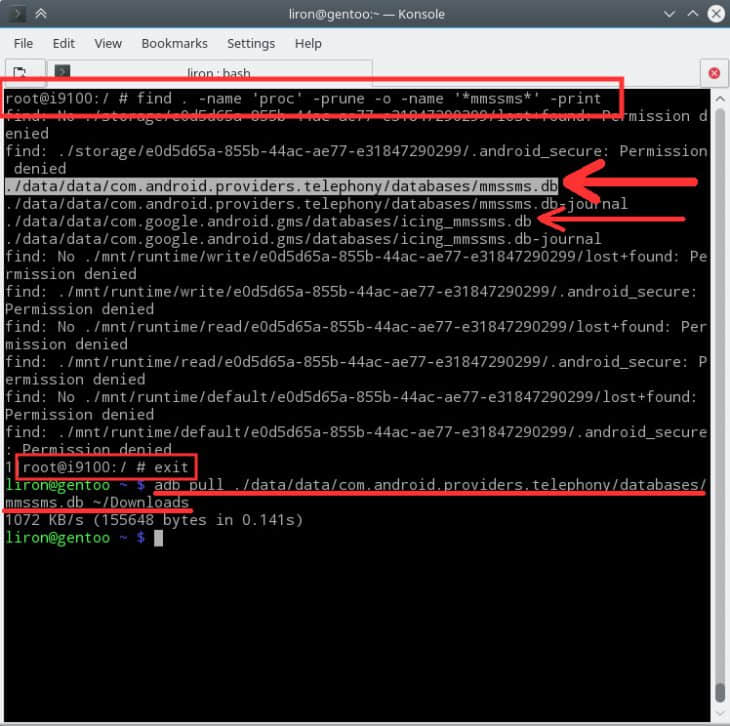
第四步 在你的电脑上为 ADB 打开一个命令行窗口
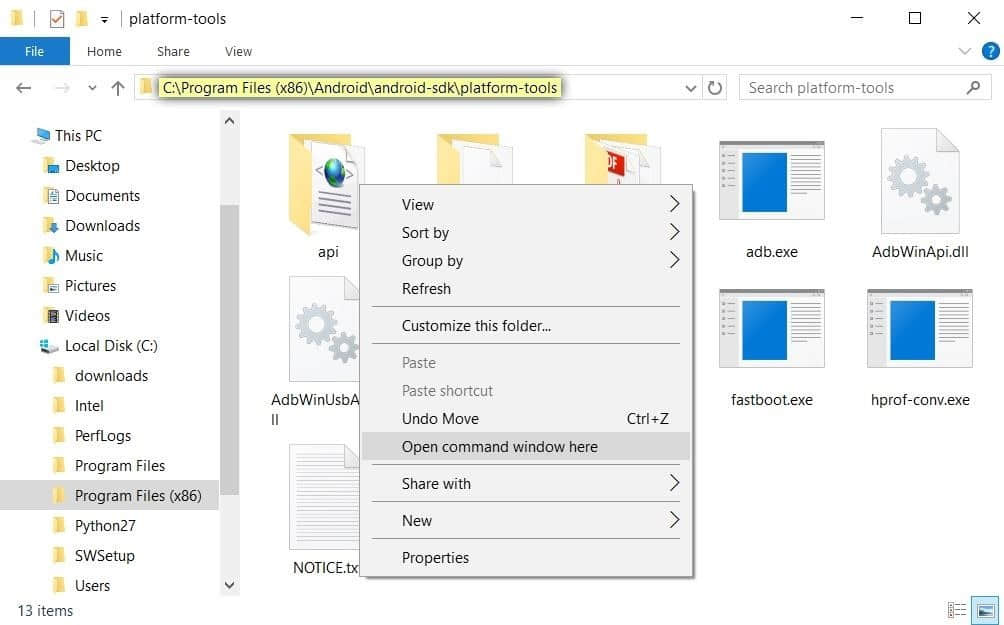
转到 ADB 和 Fastboot 的安装目录。对于 Windows 用户来说,这目录通常是 C:\Program Files (x86)\Android\android-sdk\platform-tools。 对于 Mac 和 Linux 用户,则取决于你安装此工具时将 ADB 解压的位置,所以如果你忘了位置的话,就在硬盘里搜索 platform-tools。
在安装目录下,如果你使用 Windows PC 的话,按住键盘上的 Shift 键,在文件管理器的空白处单击右键,然后选择“在此处开启命令行窗口”。如果你用的是 Mac 或者 Linux,那么你仅仅需要打开一个终端,然后转到 platform-tools 下。
第五步 解锁 bootloader
这一步你仅仅需要做一次,所以如果你的 bootloader 已经解锁,你可以直接跳过这步。否则你还需要运行一条命令 —— 注意,这条命令会清空你设备上的所有数据。
在输入命令之前,我需要说明下,下面的命令仅仅对 Windows 适用,Mac 用户需要在每条命令前加上一个句号和一个斜线(./),Linux 用户则需要加上一个斜线(/)。
所以,在 ADB Shell 里输入如下命令,然后按下回车键。
fastboot devices
如果程序输出了以 fastboot 结尾的一串字符,那就说明你的设备连接正常,可以继续操作。如果没有的话,回到第一步,检查你的 ADB 以及 Fastooot,是否正确安装,之后再确定设备是否如第三步所示进入了 bootloader 模式。
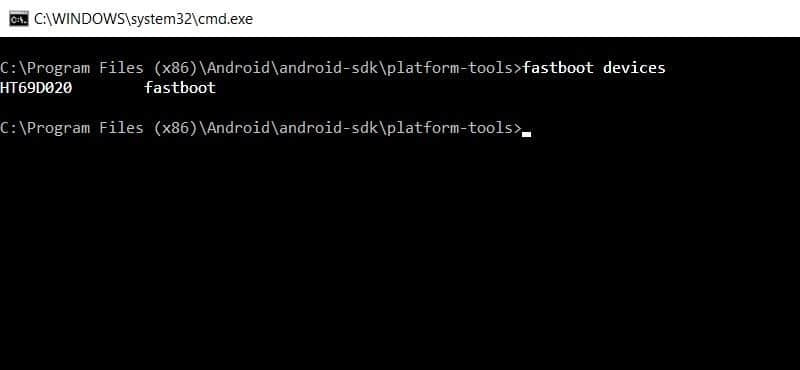
之后,解锁你的 bootloader。因为 Android 版本的差别,我们有两种方法来解决这个问题。
如果你的设备的 Android 版本是 5.0 或者更低版本 ,输入如下命令:
fastboot oem unlock
如果你的 Android 版本是 6.0 或更高的话,输入如下命令,然后按下回车:
fastboot flashing unlock
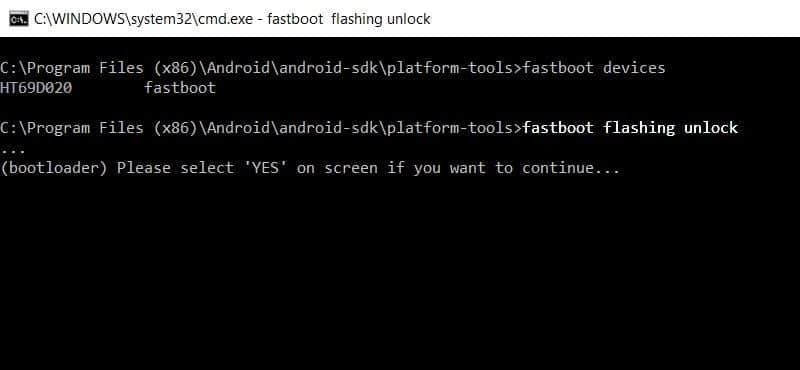
将解锁命令发送到 6.0 或者更高版本的 Android 手机上
这时,你的 Android 手机会问你是否确定要解锁 bootloader。确定你选中了 “Yes” 的选项,如果没有,使用音量键选中 “Yes”。然后按下电源键,你的设备将会开始解锁,之后会重启到 Fastboot 模式。
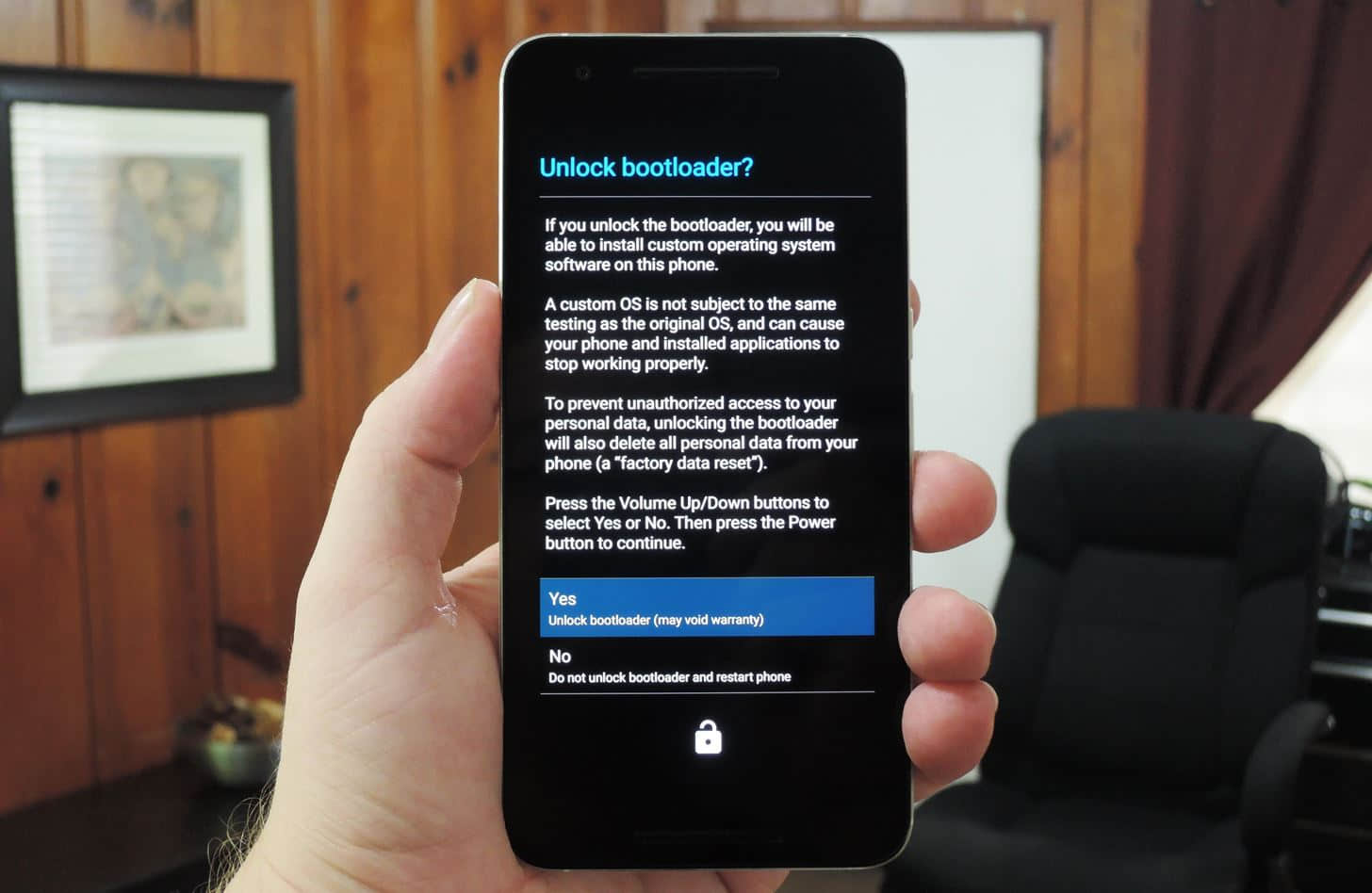
Nexus 6P 上的解锁菜单。图像来自 Dallas Thomas/Gadget Hacks
第六步 下载出厂镜像
现在你的 bootloader 已经解锁,准备好刷入出厂镜像了 -- 不过,你需要先下载镜像。下面是常规设备下载出厂镜像的链接。
使用上面的链接,在列表中定位你的设备型号,然后下载最新固件到计算机上。如果你的厂商不在列表中,可以试着用 “factory images for ” 进行 google 搜索。
第七步 刷入出厂镜像
现在该刷入镜像了。首先将从厂商网站下载的出厂镜像文件解压。我推荐 7-Zip ,它是免费的,支持大多数格式。
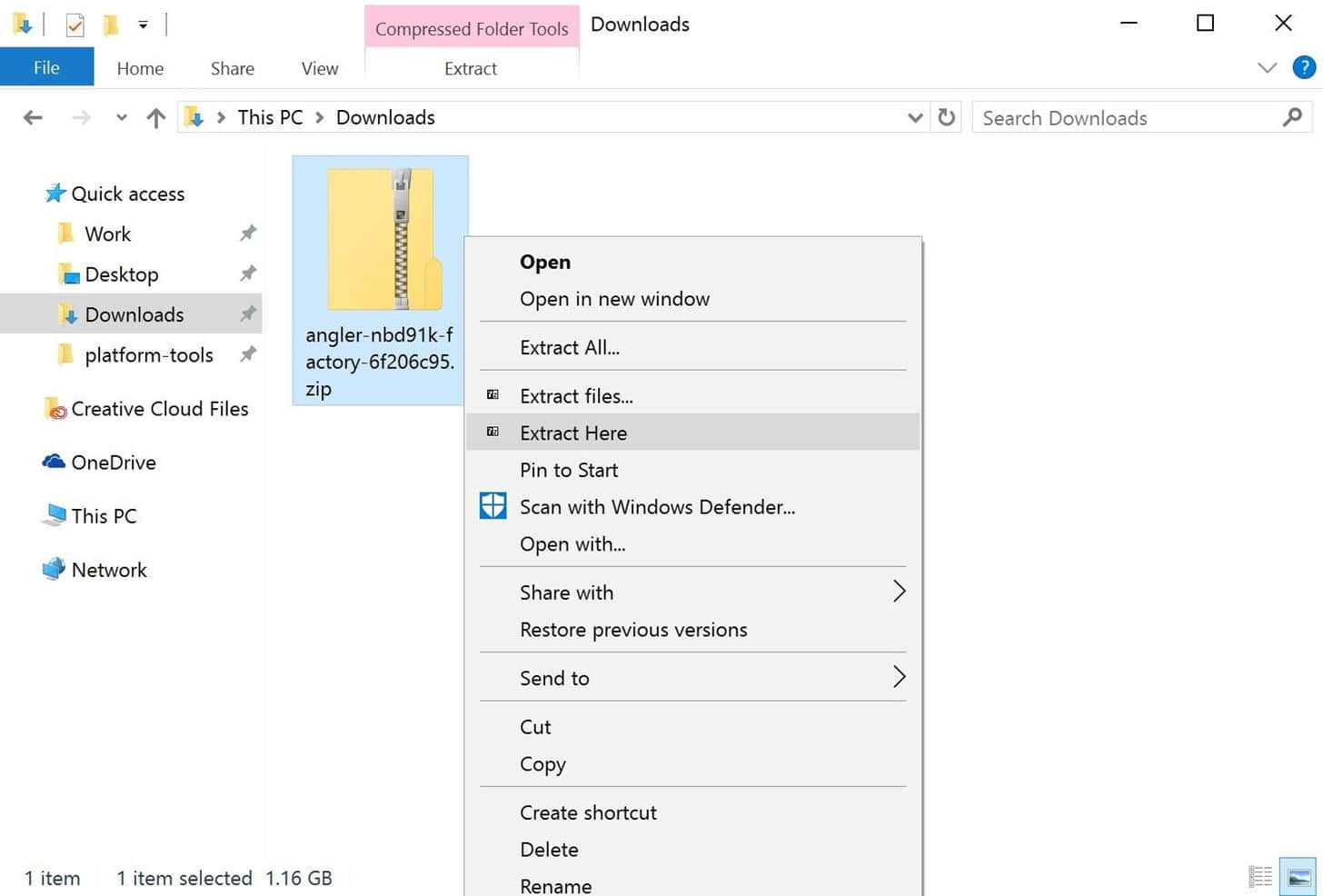
解压出厂镜像
下一步,把压缩包中内容移动到你的 ADB 安装文件夹。之后在这里打开一个命令行窗口。要得到更多信息,请回看第四步。
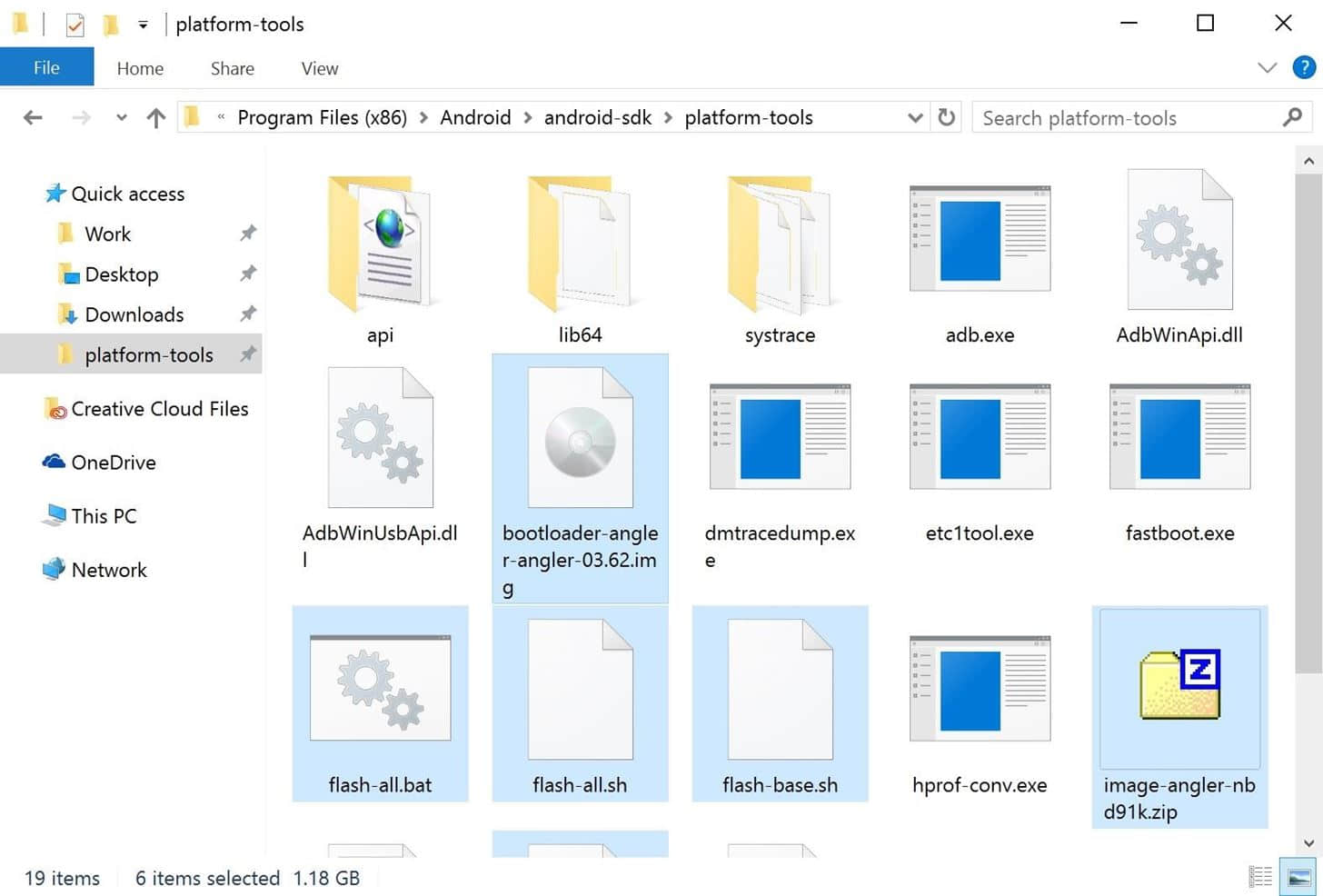
出厂镜像移动到 platform-tools 的文件
除了上面这些,你有两种刷入镜像的方法。我会在下文分开叙述。
方法一:使用 flash-all 脚本
大多数出厂镜像都会包含一个flash-all 脚本,可以让你一条命令就完成刷机过程。如果你试图让你的黑砖恢复正常的话,这是最简单的方法。但是这会让你的手机回到未 root 的状态,并会擦除所有数据,如果你不想这样的话,请选择方法二。
如果要运行 flash-all 脚本,输入如下命令,之后敲下回车:
flash-all

运行 "flash-all" 命令
这需要一点时间,当这步完成之后,你的手机应当自动重启,你可以享受 100% 原生固件。
方法二 手动解压刷入镜像
你可以手动刷入系统镜像。这么做需要额外的工作,但是它可以在不清除数据的情况下反 root,升级设备,或者救回你的砖机。
首先解压出厂镜像包中的所有压缩文件。通常压缩包里会包含三或四个层叠的文件夹,确认你已经解压了所有的压缩文件。之后把这些文件移动到 platform-tools —— 或者说,别把他们放到任何子文件夹下。
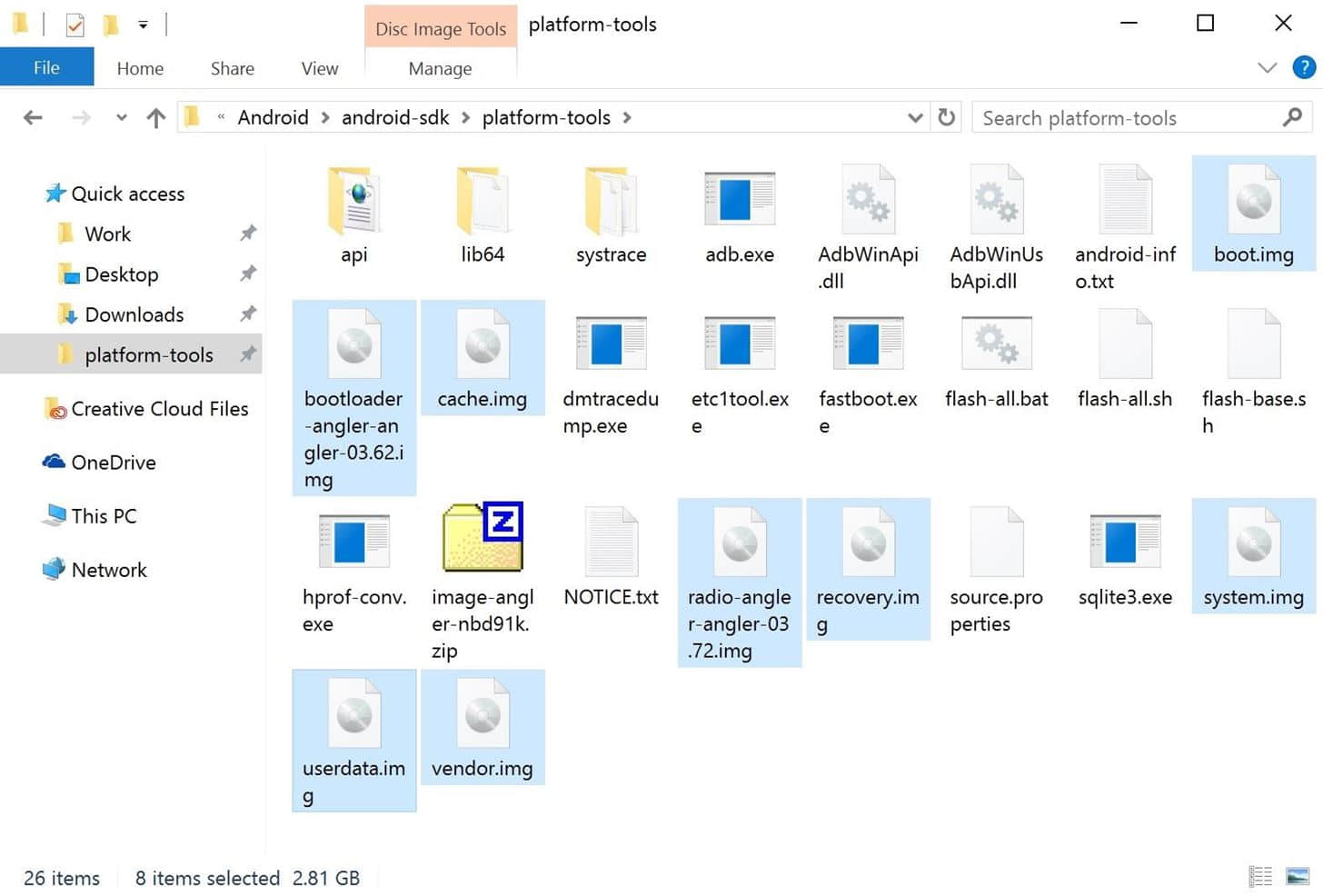
从出厂镜像包解压后的所有文件移至 platform-tools 目录
在这些文件里,有两个镜像是可以直接删除的:cache.img 和 userdata.img。就是这两个文件清除了你的设备数据,如果你不刷入这两个镜像,你的数据就不会消失。
在剩下的文件中,有六个镜像构成了 Android 的核心部分: boot、bootloader、 radio、 recovery、 system 和 vendor。
boot 镜像包含了内核,如果你想要换掉一个不太好用的自制内核的话,你仅仅需要刷入这个文件。通过键入如下命令完成工作:
fastboot flash boot <boot image file name>.img
下一个就是 bootloader 镜像—— 也就是你用来刷入镜像的界面。如果你要升级 bootloader 的话,输入如下命令:
fastboot flash bootloader <bootloader image file name>.img
做完这步之后,你就可以用新版的 bootloader 刷入镜像。要想如此,输入:
fastboot reboot-bootloader
之后就是 radio 镜像。这个镜像控制你设备的网络连接,如果你手机的 Wi-Fi 或者移动数据出现了毛病,或者你仅仅想升级你的 radio,输入:
fastboot flash radio <radio image file name>.img
然后就是 recovery。根据你之前的修改,你可能选择刷或不刷这个镜像。例如,如果你已经刷入 TWRP 的话,刷入这个镜像覆盖你的修改,并替代为 stock recovery。如果你仅仅要升级你的已经被修改过的设备,你就可以跳过这步。如果你想要新版的 stock recovery ,键入:
fastboot flash recovery <recovery file name>.img
下一个可是个大家伙:system 镜像,它包含了 Android 系统所需的全部文件。它是升级过程中最重要的部分。
如果你不想升级系统,仅仅是要换回原生固件或者是救砖的话,你只需要刷入这个镜像,它包含了 Android 的所有文件。换言之,如果你仅仅刷入了这个文件,那你之前对这个设备做的修改都会被取消。
作为一个救砖的通用方法,以及升级 Android 的方法,键入:
fastboot flash system <system file name>.img
最后,就是 vendor 镜像。只有新版的设备才包含这个包。没有的话也不必担心,不过如果有这个文件的话,那它就包含了一些重要的文件,键入如下命令使其更新:
fastboot flash vendor <vendor file name>.img
在这之后,你就可以重新启动设备:
fastboot reboot
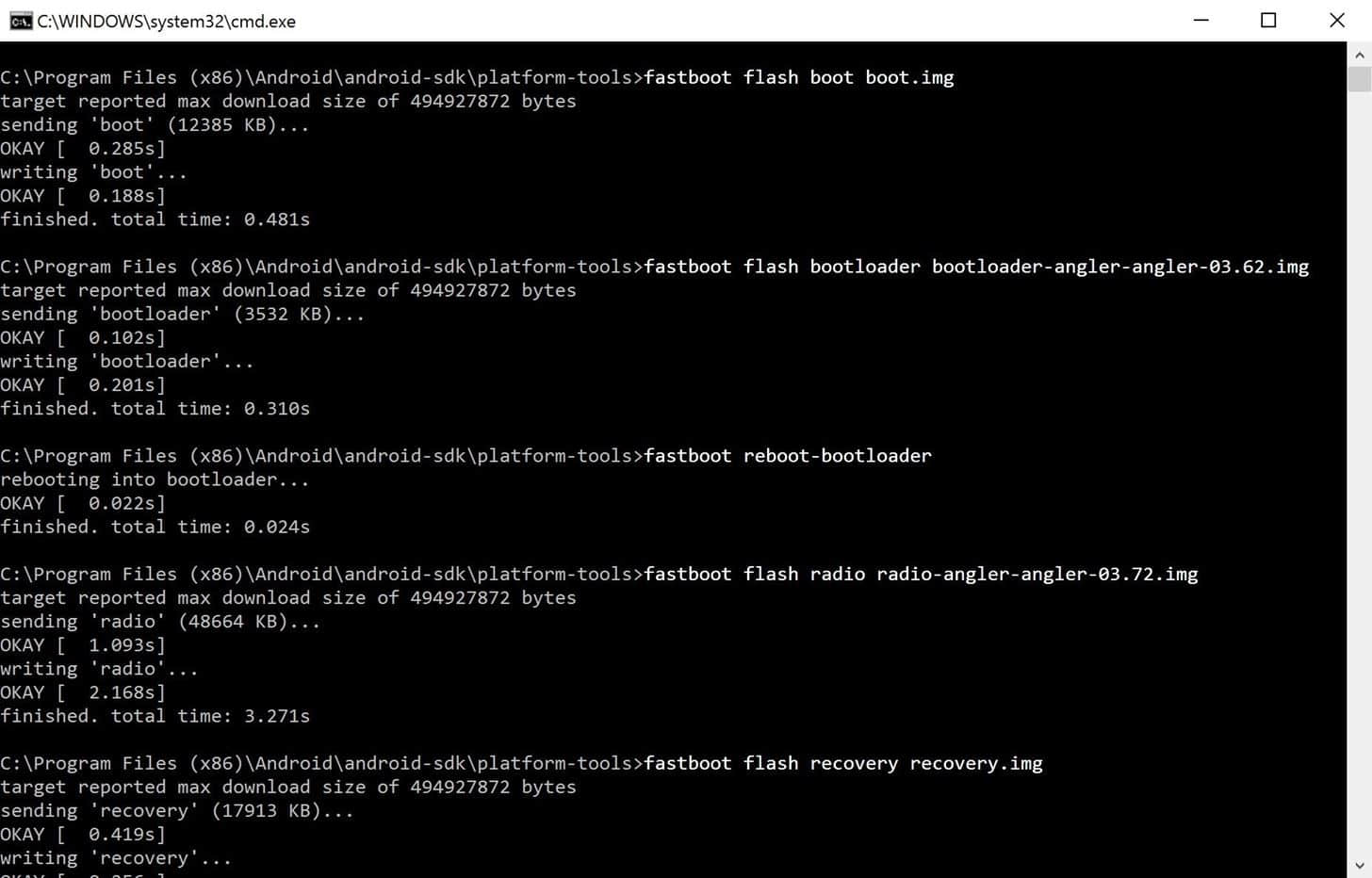
手动逐个刷入出厂镜像
至此,你的设备已经完全更新,如果你是救砖的话,你的手机应该已经完好的运行。如果你知道每个系统镜像怎么是干什么的话,你就会更好的理解 Android 是怎么运行的。
手动刷入镜像比做任何修改已经帮助我更多地理解了 Android。你会发现,Android 就是写进存储设备里的一堆镜像,现在你可以自己处理他们,你也能更好的处理有关 root 的问题。
- 在Facebook、Twitter、Google+ 以及 YouTube 关注 Gadget Hacks
- 在 Facebook、Twitter 和 Pinterest 上关注 Android Hacks
- 在 Facebook、Twitter、 Pinterest 还有 Google+ 上关注 WonderHowTo
via: http://android.wonderhowto.com/how-to/complete-guide-flashing-factory-images-using-fastboot-0175277/
作者:Dallas Thomas 译者:name1e5s 校对:jasminepeng