pass:一款简单的基于 Linux 命令行的密码管理工具

现如今要记住类似 email、银行、社交媒体、在线支付、ftp 等等这么多的密码相信对每一个人来说都是一个巨大的挑战。
由于需求和使用,密码管理器现如今变得非常的流行。在 Linux 中我们可以有很多选择,包括基于 GUI 和基于 CLI 两种。今天我们要讲的是一款基于 CLI 的密码管理器叫做 pass 。
pass 是 Linux 上的一个简单的命令行密码管理器,它将密码存储在一个 gpg 加密后的文件里。这些加密后的文件很好地组织按目录结构存放。
所有密码都存在于 ~/.password-store 中,它提供了添加、编辑、生成和检索密码等简单命令。
它是一个非常简短和简单的 shell 脚本。 它能够临时将密码放在剪贴板上,并使用 git 跟踪密码的修改。
这是一个很小的 shell 脚本,它还使用了少量的默认工具比如 gnupg、tree 和 git,同时还有活跃的社区为它提供 GUI 和扩展。
如何在 Linux 中安装 Pass
Pass 可从大多数 Linux 的主要发行版的仓库中获得。 所以,你可以使用你的分布式包管理器来安装它。
对于基于 Debian 的系统,你可以使用 apt-get 或 apt 包管理器命令来安装 pass。
$ sudo apt-get install pass
对于基于 RHEL/CentOS 的操作系统, 使用 yum 包管理器命令来安装它。
$ sudo yum install pass
Fedora 系统可用 dnf 包管理器命令来安装。
$ sudo dnf install pass
openSUSE 系统可以用 zypper 包管理器命令来安装。
$ sudo zypper in password-store
对于基于 Arch Linux 的操作系统用 pacman 包管理器来安装它。
$ pacman -S pass
如何生成 GPG 密钥对
确保你拥有你个人的 GPG 密钥对。如果没有的话,你可以通过在终端中输入以下的命令并安装指导来创建你的 GPG 密钥对。
$ gpg --gen-key
运行以上的命令以生成 GPG 密钥对时会有一系列的问题询问,谨慎输入问题的答案,其中有一些只要使用默认值即可。
初始化密码存储
如果你已经有了 GPG 密钥对,请通过运行以下命令初始化本地密码存储,你可以使用 email-id 或 gpg-id 初始化。
$ pass init [email protected]
mkdir: created directory '/home/magi/.password-store/'
Password store initialized for [email protected]
上述命令将在 ~/.password-store 目录下创建一个密码存储区。
pass 命令提供了简单的语法来管理密码。 我们一个个来看,如何添加、编辑、生成和检索密码。
通过下面的命令检查目录结构树。
$ pass
or
$ pass ls
or
$ pass show
Password Store
我没有看到任何树型结构,所以我们将根据我们的需求来创建一个。
插入一个新的密码信息
我们将通过运行以下命令来保存 gmail 的 id 及其密码。
$ pass insert eMail/[email protected]
mkdir: created directory '/home/magi/.password-store/eMail'
Enter password for eMail/[email protected]:
Retype password for eMail/[email protected]:
执行重复操作,直到所有的密码插入完成。 比如保存 Facebook 密码。
$ pass insert Social/Facebook_2daygeek
mkdir: created directory '/home/magi/.password-store/Social'
Enter password for Social/Facebook_2daygeek:
Retype password for Social/Facebook_2daygeek:
我们可以列出存储中的所有现有的密码。
$ pass show
Password Store
├── 2g
├── Bank
├── eMail
│ ├── [email protected]
│ └── [email protected]
├── eMail
├── Social
│ ├── Facebook_2daygeek
│ └── Gplus_2daygeek
├── Social
└── Sudha
└── [email protected]
显示已有密码
运行以下命令从密码存储中检索密码信息,它会询问你输入密码以解锁。
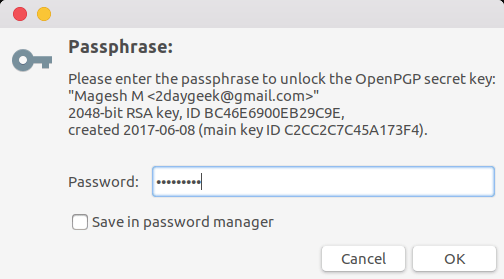
$ pass eMail/[email protected]
*******
在剪贴板中复制密码
要直接将密码直接复制到剪贴板上,而不是在终端上输入,请使用以下更安全的命令,它会在 45 秒后自动清除密码。
$ pass -c eMail/[email protected]
Copied eMail/[email protected] to clipboard. Will clear in 45 seconds.
生成一个新密码
如果你想生成一些比较难以猜测的密码用于代替原有的奇怪密码,可以通过其内部的 pwgen 功能来实现。
$ pass generate eMail/[email protected] 15
An entry already exists for eMail/[email protected]. Overwrite it? [y/N] y
The generated password for eMail/[email protected] is:
y!NZ<%T)5Iwym_S
生成没有符号的密码。
$ pass generate eMail/[email protected] 15 -n
An entry already exists for eMail/[email protected]. Overwrite it? [y/N] y
The generated password for eMail/[email protected] is:
TP9ACLyzUZUwBwO
编辑现有的密码
使用编辑器插入新密码或编辑现有密码。 当你运行下面的命令时,将会在包含密码的文本编辑器中打开文件 /dev/shm/pass.wUyGth1Hv0rnh/[email protected]。 只需在其中添加新密码,然后保存并退出即可。
$ pass edit eMail/[email protected]
File: /dev/shm/pass.wUyGth1Hv0rnh/[email protected]
TP9ACLyzUZUwBwO
移除密码
删除现有密码。 它将从 ~/.password-store 中删除包含 .gpg 的条目。
$ pass rm eMail/[email protected]
Are you sure you would like to delete eMail/[email protected]? [y/N] y
removed '/home/magi/.password-store/eMail/[email protected]'
多选项功能
要保存详细信息,如 URL、用户名、密码、引脚等信息,可以使用以下格式。 首先确保你要将第一项设置为密码,因为它用于在使用剪贴板选项时将第一行复制为密码,以及后续行中的附加信息。
$ pass insert eMail/[email protected] -m
Enter contents of eMail/[email protected] and press Ctrl+D when finished:
H3$%hbhYT
URL : http://www.2daygeek.com
Info : Linux Tips & Tricks
Ftp User : 2g
(题图:Pixabay, CC0)
via: http://www.2daygeek.com/pass-command-line-password-manager-linux/
作者:2DAYGEEK 译者:chenxinlong 校对:wxy










