使用 Redis 和 Python 构建一个共享单车的应用程序
学习如何使用 Redis 和 Python 构建一个位置感知的应用程序。

我经常出差。但不是一个汽车狂热分子,所以当我有空闲时,我更喜欢在城市中散步或者骑单车。我参观过的许多城市都有共享单车系统,你可以租个单车用几个小时。大多数系统都有一个应用程序来帮助用户定位和租用他们的单车,但对于像我这样的用户来说,在一个地方可以获得可租赁的城市中所有单车的信息会更有帮助。
为了解决这个问题并且展示开源的强大还有为 Web 应用程序添加位置感知的功能,我组合了可用的公开的共享单车数据、Python 编程语言以及开源的 Redis 内存数据结构服务,用来索引和查询地理空间数据。
由此诞生的共享单车应用程序包含来自很多不同的共享系统的数据,包括纽约市的 Citi Bike 共享单车系统(LCTT 译注:Citi Bike 是纽约市的一个私营公共单车系统。在 2013 年 5 月 27 日正式营运,是美国最大的公共单车系统。Citi Bike 的名称有两层意思。Citi 是计划赞助商花旗银行(CitiBank)的名字。同时,Citi 和英文中“城市(city)”一词的读音相同)。它利用了花旗单车系统提供的 通用共享单车数据流 ,并利用其数据演示了一些使用 Redis 地理空间数据索引的功能。 花旗单车数据可按照 花旗单车数据许可协议 提供。
通用共享单车数据流规范
通用共享单车数据流规范 (GBFS)是由 北美共享单车协会 开发的 开放数据规范,旨在使地图程序和运输程序更容易的将共享单车系统添加到对应平台中。 目前世界上有 60 多个不同的共享系统使用该规范。
Feed 流由几个简单的 JSON 数据文件组成,其中包含系统状态的信息。 Feed 流以一个顶级 JSON 文件开头,其引用了子数据流的 URL:
{
"data": {
"en": {
"feeds": [
{
"name": "system_information",
"url": "https://gbfs.citibikenyc.com/gbfs/en/system_information.json"
},
{
"name": "station_information",
"url": "https://gbfs.citibikenyc.com/gbfs/en/station_information.json"
},
. . .
]
}
},
"last_updated": 1506370010,
"ttl": 10
}第一步是使用 system_information 和 station_information 的数据将共享单车站的信息加载到 Redis 中。
system_information 提供系统 ID,系统 ID 是一个简短编码,可用于为 Redis 键名创建命名空间。 GBFS 规范没有指定系统 ID 的格式,但确保它是全局唯一的。许多共享单车数据流使用诸如“coastbikeshare”,“boisegreenbike” 或者 “topekametro\_bikes” 这样的短名称作为系统 ID。其他的使用常见的有地理缩写,例如 NYC 或者 BA,并且使用通用唯一标识符(UUID)。 这个共享单车应用程序使用该标识符作为前缀来为指定系统构造唯一键。
station_information 数据流提供组成整个系统的共享单车站的静态信息。车站由具有多个字段的 JSON 对象表示。车站对象中有几个必填字段,用于提供物理单车站的 ID、名称和位置。还有几个可选字段提供有用的信息,例如最近的十字路口、可接受的付款方式。这是共享单车应用程序这一部分的主要信息来源。
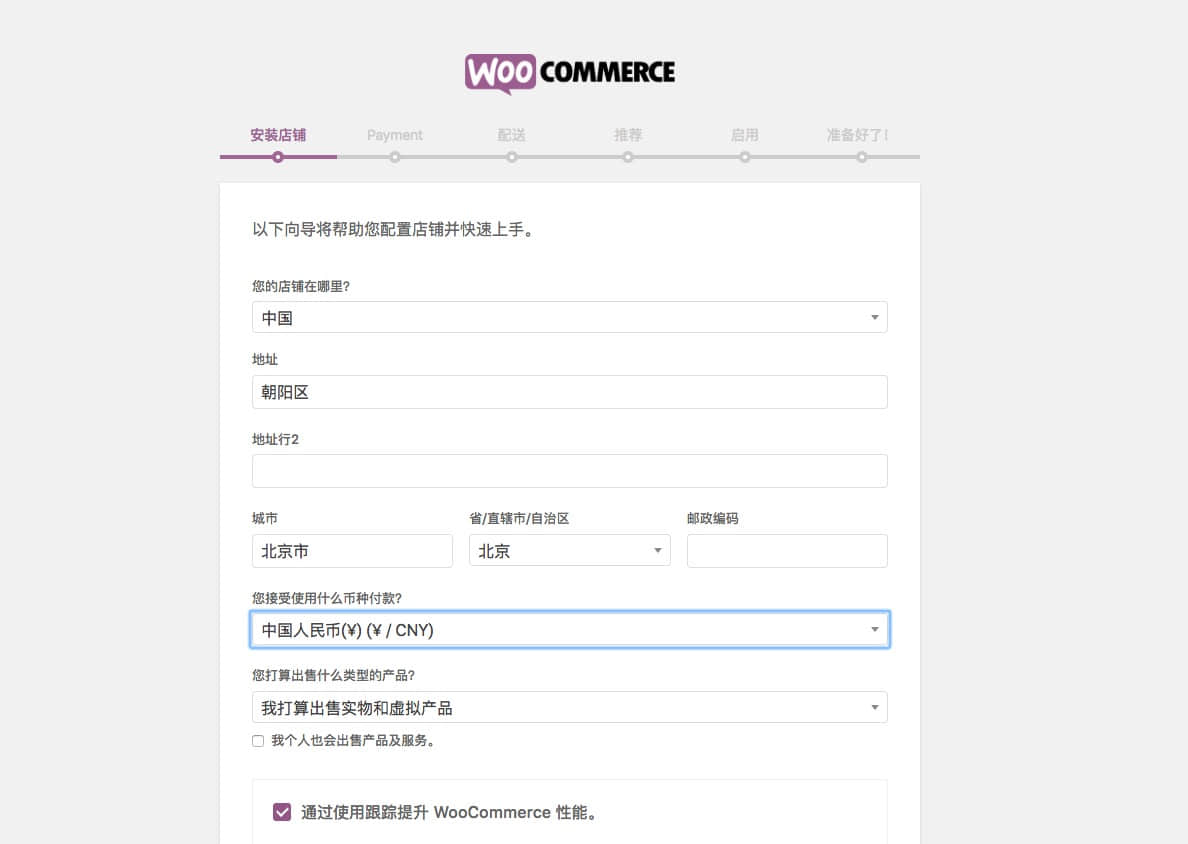
建立数据库
我编写了一个示例应用程序 loadstationdata.py,它模仿后端进程中从外部源加载数据时会发生什么。
查找共享单车站
从 GitHub 上 GBFS 仓库中的 systems.csv 文件开始加载共享单车数据。
仓库中的 systems.csv 文件提供已注册的共享单车系统及可用的 GBFS 数据流的 发现 URL 。 这个发现 URL 是处理共享单车信息的起点。
load_station_data 程序获取系统文件中找到的每个发现 URL,并使用它来查找两个子数据流的 URL:系统信息和车站信息。 系统信息提供提供了一条关键信息:系统的唯一 ID。 (注意:系统 ID 也在 systems.csv 文件中提供,但文件中的某些标识符与数据流中的标识符不匹配,因此我总是从数据流中获取标识符。)系统上的详细信息,比如共享单车 URL、电话号码和电子邮件, 可以在程序的后续版本中添加,因此使用 ${system_id}:system_info 这个键名将数据存储在 Redis 中。
载入车站数据
车站信息提供系统中每个车站的数据,包括该系统的位置。load_station_data 程序遍历车站数据流中的每个车站,并使用 ${system_id}:station:${station_id} 形式的键名将每个车站的数据存储到 Redis 中。 使用 GEOADD 命令将每个车站的位置添加到共享单车的地理空间索引中。
更新数据
在后续运行中,我不希望代码从 Redis 中删除所有 Feed 数据并将其重新加载到空的 Redis 数据库中,因此我仔细考虑了如何处理数据的原地更新。
代码首先加载所有需要系统在内存中处理的共享单车站的信息数据集。 当加载了一个车站的信息时,该站就会按照 Redis 键名从内存中的车站集合中删除。 加载完所有车站数据后,我们就剩下一个包含该系统所有必须删除的车站数据的集合。
程序迭代处理该数据集,并创建一个事务删除车站的信息,从地理空间索引中删除该车站的键名,并从系统的车站列表中删除该车站。
代码重点
在示例代码中有一些值得注意的地方。 首先,使用 GEOADD 命令将所有数据项添加到地理空间索引中,而使用 ZREM 命令将其删除。 由于地理空间类型的底层实现使用了有序集合,因此需要使用 ZREM 删除数据项。 需要注意的是:为简单起见,示例代码演示了如何在单个 Redis 节点工作; 为了在集群环境中运行,需要重新构建事务块。
如果你使用的是 Redis 4.0(或更高版本),则可以在代码中使用 DELETE 和 HMSET 命令。 Redis 4.0 提供 UNLINK 命令作为 DELETE 命令的异步版本的替代。 UNLINK 命令将从键空间中删除键,但它会在另外的线程中回收内存。 在 Redis 4.0 中 HMSET 命令已经被弃用了而且 HSET 命令现在接收可变参数(即,它接受的参数个数不定)。
通知客户端
处理结束时,会向依赖我们数据的客户端发送通知。 使用 Redis 发布/订阅机制,通知将通过 geobike:station_changed 通道和系统 ID 一起发出。
数据模型
在 Redis 中构建数据时,最重要的考虑因素是如何查询信息。 共享单车程序需要支持的两个主要查询是:
- 找到我们附近的车站
- 显示车站相关的信息
Redis 提供了两种主要数据类型用于存储数据:哈希和有序集。 哈希类型很好地映射到表示车站的 JSON 对象;由于 Redis 哈希不使用固定的数据结构,因此它们可用于存储可变的车站信息。
当然,在地理位置上寻找站点需要地理空间索引来搜索相对于某些坐标的站点。 Redis 提供了几个使用有序集数据结构构建地理空间索引的命令。
我们使用 ${system_id}:station:${station_id} 这种格式的键名存储车站相关的信息,使用 ${system_id}:stations:location 这种格式的键名查找车站的地理空间索引。
获取用户位置
构建应用程序的下一步是确定用户的当前位置。 大多数应用程序通过操作系统提供的内置服务来实现此目的。 操作系统可以基于设备内置的 GPS 硬件为应用程序提供定位,或者从设备的可用 WiFi 网络提供近似的定位。
查找车站
找到用户的位置后,下一步是找到附近的共享单车站。 Redis 的地理空间功能可以返回用户当前坐标在给定距离内的所有车站信息。 以下是使用 Redis 命令行界面的示例。
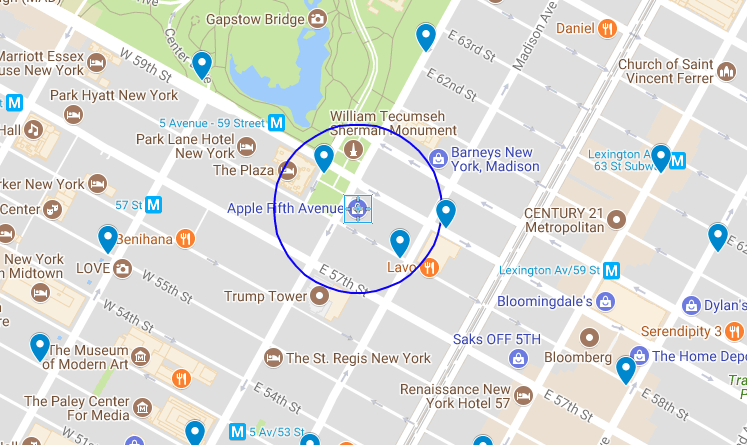
想象一下,我正在纽约市第五大道的苹果零售店,我想要向市中心方向前往位于西 37 街的 MOOD 布料店,与我的好友 Swatch 相遇。 我可以坐出租车或地铁,但我更喜欢骑单车。 附近有没有我可以使用的单车共享站呢?
苹果零售店位于 40.76384,-73.97297。 根据地图显示,在零售店 500 英尺半径范围内(地图上方的蓝色)有两个单车站,分别是陆军广场中央公园南单车站和东 58 街麦迪逊单车站。
我可以使用 Redis 的 GEORADIUS 命令查询 500 英尺半径范围内的车站的 NYC 系统索引:
127.0.0.1:6379> GEORADIUS NYC:stations:location -73.97297 40.76384 500 ft
1) "NYC:station:3457"
2) "NYC:station:281"Redis 使用地理空间索引中的元素作为特定车站的元数据的键名,返回在该半径内找到的两个共享单车站。 下一步是查找两个站的名称:
127.0.0.1:6379> hget NYC:station:281 name
"Grand Army Plaza & Central Park S"
127.0.0.1:6379> hget NYC:station:3457 name
"E 58 St & Madison Ave"这些键名对应于上面地图上标识的车站。 如果需要,可以在 GEORADIUS 命令中添加更多标志来获取元素列表,每个元素的坐标以及它们与当前点的距离:
127.0.0.1:6379> GEORADIUS NYC:stations:location -73.97297 40.76384 500 ft WITHDIST WITHCOORD ASC
1) 1) "NYC:station:281"
2) "289.1995"
3) 1) "-73.97371262311935425"
2) "40.76439830559216659"
2) 1) "NYC:station:3457"
2) "383.1782"
3) 1) "-73.97209256887435913"
2) "40.76302702144496237"查找与这些键名关联的名称会生成一个我可以从中选择的车站的有序列表。 Redis 不提供方向和路线的功能,因此我使用设备操作系统的路线功能绘制从当前位置到所选单车站的路线。
GEORADIUS 函数可以很轻松的在你喜欢的开发框架的 API 里实现,这样就可以向应用程序添加位置功能了。
其他的查询命令
除了 GEORADIUS 命令外,Redis 还提供了另外三个用于查询索引数据的命令:GEOPOS、GEODIST 和 GEORADIUSBYMEMBER。
GEOPOS 命令可以为 地理哈希 中的给定元素提供坐标(LCTT 译注:geohash 是一种将二维的经纬度编码为一位的字符串的一种算法,常用于基于距离的查找算法和推荐算法)。 例如,如果我知道西 38 街 8 号有一个共享单车站,ID 是 523,那么该站的元素名称是 NYC:station:523。 使用 Redis,我可以找到该站的经度和纬度:
127.0.0.1:6379> geopos NYC:stations:location NYC:station:523
1) 1) "-73.99138301610946655"
2) "40.75466497634030105"GEODIST 命令提供两个索引元素之间的距离。 如果我想找到陆军广场中央公园南单车站与东 58 街麦迪逊单车站之间的距离,我会使用以下命令:
127.0.0.1:6379> GEODIST NYC:stations:location NYC:station:281 NYC:station:3457 ft
"671.4900"最后,GEORADIUSBYMEMBER 命令与 GEORADIUS 命令类似,但该命令不是采用一组坐标,而是采用索引的另一个成员的名称,并返回以该成员为中心的给定半径内的所有成员。 要查找陆军广场中央公园南单车站 1000 英尺范围内的所有车站,请输入以下内容:
127.0.0.1:6379> GEORADIUSBYMEMBER NYC:stations:location NYC:station:281 1000 ft WITHDIST
1) 1) "NYC:station:281"
2) "0.0000"
2) 1) "NYC:station:3132"
2) "793.4223"
3) 1) "NYC:station:2006"
2) "911.9752"
4) 1) "NYC:station:3136"
2) "940.3399"
5) 1) "NYC:station:3457"
2) "671.4900"虽然此示例侧重于使用 Python 和 Redis 来解析数据并构建共享单车系统位置的索引,但可以很容易地衍生为定位餐馆、公共交通或者是开发人员希望帮助用户找到的任何其他类型的场所。
本文基于今年我在北卡罗来纳州罗利市的开源 101 会议上的演讲。
via: https://opensource.com/article/18/2/building-bikesharing-application-open-source-tools
作者:Tague Griffith 译者:Flowsnow 校对:wxy