物联网(IoT)简介
物联网(IoT)是一个由智能设备连接起来的网络,并提供了丰富的数据,但是它也有可能是一场安全领域的噩梦。

物联网 (IoT)是一个统称,指的是越来越多不属于传统计算设备,但却连接到互联网接收或发送数据,或既接收也发送的电子设备组成的网络。
现在有数不胜数的东西可以归为这一类:可以联网的“智能”版传统设备,比如说电冰箱和灯泡;那些只能运行于有互联网环境的小设备,比如像 Alexa 之类的电子助手;与互联网连接的传感器,它们正在改变着工厂、医疗、运输、物流中心和农场。
什么是物联网?
物联网将互联网、数据处理和分析的能力带给了现实的实物世界。对于消费者来说,这就意味着不需要键盘和显示器这些东西,就能和这个全球信息网络进行互动;他们的日常用品当中,很多都可以通过该网络接受操作指令,而只需很少的人工干预。
互联网长期以来为知识工作提供了便利,在企业环境当中,物联网也能为制造和分销带来同样的效率。全球数以百万计甚至数十亿计的嵌入式具有互联网功能的传感器正在提供令人难以置信丰富的数据集,企业可以利用这些数据来保证他们运营的安全、跟踪资产和减少人工流程。研究人员也可以使用物联网来获取人们的喜好和行为数据,尽管这些行为可能会严重影响隐私和安全。
它有多大?
一句话:非常庞大。Priceonomics 对此进行了分析:在 2020 年的时候,有超过 50 亿的物联网设备,这些设备可以生成 4.4 泽字节 (LCTT 译注:1 zettabyte = 10 9 terabyte = 10 12 gigabyte)的数据。相比较,物联网设备在 2013 年仅仅产生了 1000 亿 千兆字节 的数据。在物联网市场上可能挣到的钱也同样让人瞠目;到 2025 年,这块市场的价值可以达到 1.6 万亿美元到 14.4 万亿美元不等。
物联网的历史
一个联网设备和传感器无处不在的世界,是科幻小说中最经典的景象之一。物联网传说中将 1970 年 卡耐基•梅隆大学的一台连接到 APRANET 的自动贩卖机 称之为世界上第一个物联网设备,而且许多技术都被吹捧为可以实现 “智能” 的物联网式特征,使其颇具有未来主义的光彩。但是“物联网”这个词是由英国的技术专家 Kevin Ashton 于 1999 年提出来的。
一开始,技术是滞后于当时对未来的憧憬的。每个与互联网相连的设备都需要一个处理器和一种能和其他东西通信的方式,无线的最好,这些因素都增加了物联网大规模实际应用的成本和性能要求,这种情况至少一直持续到 21 世纪头十年中期,直到摩尔定律赶上来。
一个重要的里程碑是 RFID 标签的大规模使用,这种价格低廉的极简转发器可以被贴在任何物品上,然后这些物品就可以连接到更大的互联网上了。对于设计者来说,无处不在的 Wi-Fi 和 4G 让任何地方的无线连接都变得非常简单。而且,IPv6 的出现再也不用让人们担心把数十亿小设备连接到互联网上会将 IP 地址耗尽。(相关报道:物联网网络可以促进 IPv6 的使用吗?)
物联网是如何工作的?
物联网的基本元素是收集数据的设备。广义地说,它们是和互联网相连的设备,所以每一个设备都有 IP 地址。它们的复杂程度不一,这些设备涵盖了从工厂运输货物的自动驾驶车辆到监控建筑温度的简单传感器。这其中也包括每天统计步数的个人手环。为了让这些数据变得有意义,就需要对其收集、处理、过滤和分析,每一种数据都可以通过多种方式进行处理。
采集数据的方式是将数据从设备上传输到采集点。可以通过各种无线或者有线网络进行数据的转移。数据可以通过互联网发送到具有存储空间或者计算能力的数据中心或者云端,或者这些数据也可以分段进行传输,由中间设备汇总数据后再沿路径发送。
处理数据可以在数据中心或者云端进行,但是有时候这不太可行。对于一些非常重要的设备,比如说工业领域的关停设备,从设备上将数据发送到远程数据中心的延迟太大了。发送、处理、分析数据和返回指令(在管道爆炸之前关闭阀门)这些操作,来回一趟的时间可能要花费非常多的时间。在这种情况下, 边缘计算 就可以大显身手了,智能边缘设备可以汇总数据、分析数据,在需要的时候进行回应,所有这些都在相对较近的物理距离内进行,从而减少延迟。边缘设备可以有上游连接,这样数据就可以进一步被处理和储存。

物联网是如何工作的。
物联网设备的一些例子
本质上,任何可以搜集来自于真实世界数据,并且可以发送回去的设备都可以参与到物联网生态系统中。典型的例子包括智能家居设备、射频识别标签(RFID)和工业传感器。这些传感器可以监控一系列的因素,包括工业系统中的温度和压力、机器中关键设备的状态、患者身上与生命体征相关的信号、水电的使用情况,以及其它许许多多可能的东西。
整个工厂的机器人可以被认为是物联网设备,在工业环境和仓库中移动产品的自主车辆也是如此。
其他的例子包括可穿戴设备和家庭安防系统。还有一些其它更基础的设备,比如说树莓派和Arduino,这些设备可以让你构建你自己的物联网终端节点。尽管你可能会认为你的智能手机是一台袖珍电脑,但它很可能也会以非常类似物联网的方式将你的位置和行为数据传送到后端服务。
设备管理
为了能让这些设备一起工作,所有这些设备都需要进行验证、分配、配置和监控,并且在必要时进行修复和更新。很多时候,这些操作都会在一个单一的设备供应商的专有系统中进行;要么就完全不会进行这些操作,而这样也是最有风险的。但是整个业界正在向标准化的设备管理模式过渡,这使得物联网设备之间可以相互操作,并保证设备不会被孤立。
物联网通信标准和协议
当物联网上的小设备和其他设备通信的时候,它们可以使用各种通信标准和协议,这其中许多都是为这些处理能力有限和电源功率不大的设备专门定制的。你一定听说过其中的一些,尽管有一些设备使用的是 Wi-Fi 或者蓝牙,但是更多的设备是使用了专门为物联网世界定制的标准。比如,ZigBee 就是一个低功耗、远距离传输的无线通信协议,而 MQTT( 消息队列遥测传输 )是为连接在不可靠或者易发生延迟的网络上的设备定制的一个发布/订阅信息协议。(参考 Network World 的词汇表:物联网标准和协议。)
物联网也会受益于 5G 为蜂窝网络带来的高速度和高带宽,尽管这种使用场景会滞后于普通的手机。
物联网、边缘计算和云
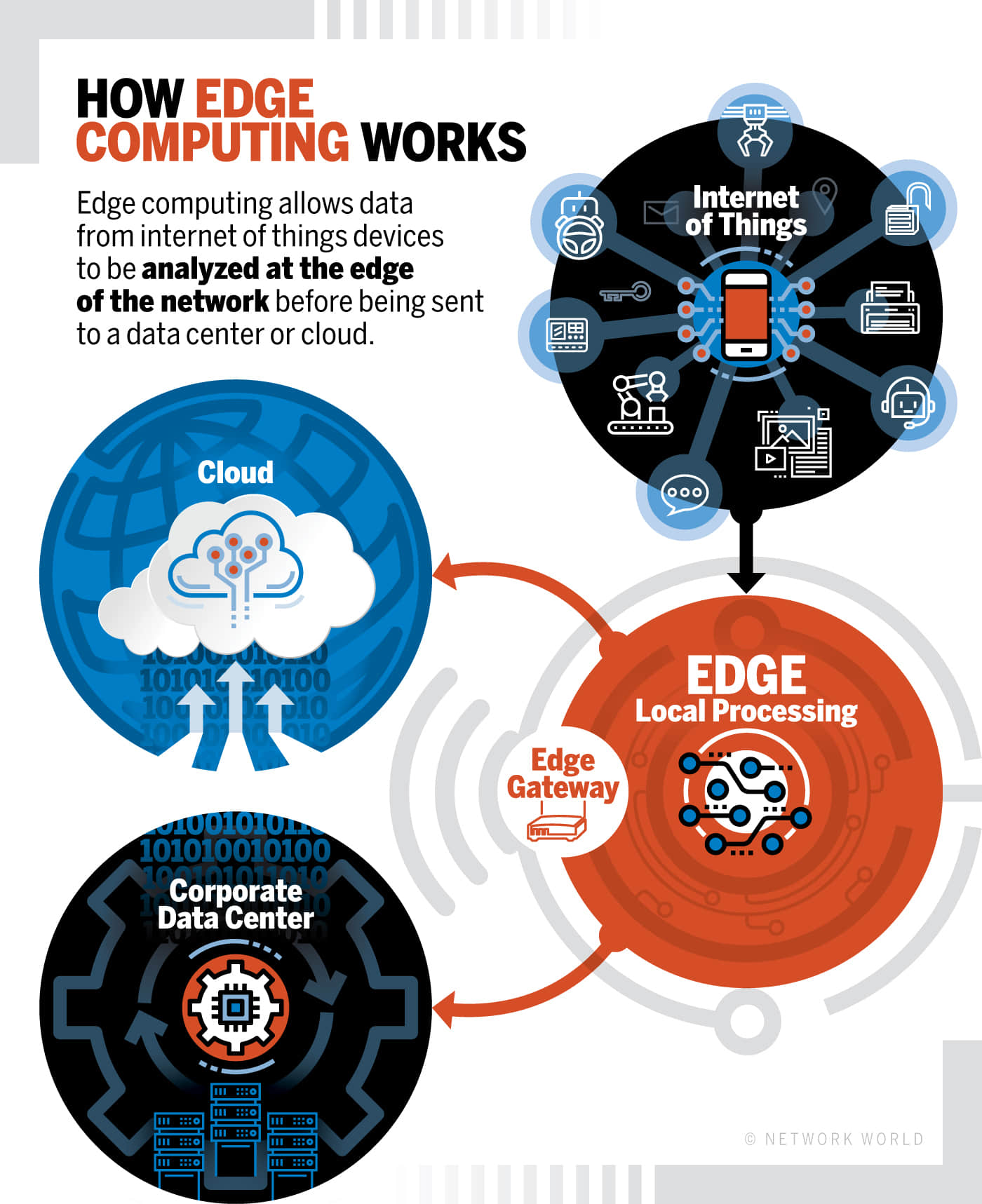
边缘计算如何使物联网成为可能。
对于许多物联网系统来说,大量的数据会以极快的速度涌来,这种情况催生了一个新的科技领域, 边缘计算 ,它由放置在物联网设备附近的设备组成,处理来自那些设备的数据。这些机器对这些数据进行处理,只将相关的素材数据发送到一个更集中的系统系统进行分析。比如,想象一个由几十个物联网安防摄像头组成的网络,边缘计算会直接分析传入的视频,而且只有当其中一个摄像头检测到有物体移动的时候才向安全操作中心(SoC)发出警报,而不会是一下子将所有的在线数据流全部发送到建筑物的 SoC。
一旦这些数据已经被处理过了,它们又去哪里了呢?好吧,它也许会被送到你的数据中心,但是更多情况下,它最终会进入云。
对于物联网这种间歇或者不同步的数据来往场景来说,具有弹性的云计算是再适合不过的了。许多云计算巨头,包括谷歌、微软和亚马逊,都有物联网产品。
物联网平台
云计算巨头们正在尝试出售的,不仅仅是存放传感器搜集的数据的地方。他们正在提供一个可以协调物联网系统中各种元素的完整平台,平台会将很多功能捆绑在一起。本质上,物联网平台作为中间件,将物联网设备和边缘网关与你用来处理物联网数据的应用程序连接起来。也就是说,每一个平台的厂商看上去都会对物联网平台应该是什么这个问题有一些稍微不同的解释,以更好地与其他竞争者拉开差距。
物联网和数据
正如前面所提到的,所有这些物联网设备收集了 ZB 级的数据,这些数据通过边缘网关被发送到平台上进行处理。在很多情况下,这些数据就是要部署物联网的首要原因。通过从现实世界中的传感器搜集来的数据,企业就可以实时的作出灵活的决定。
例如,Oracle 公司假想了一个这样的场景,当人们在主题公园的时候,会被鼓励下载一个可以提供公园信息的应用。同时,这个程序会将 GPS 信号发回到公园的管理部门来帮助他们预测排队时间。有了这些信息,公园就可以在短期内(比如通过增加员工数量来提升景点的一些容量)和长期内(通过了解哪些设施最受欢迎,那些最不受欢迎)采取行动。
这些决定可以在没有人工干预的情况作出。比如,从化工厂管道中的压力传感器收集的数据可以通过边缘设备的软件进行分析,从而发现管道破裂的威胁,这样的信息可以触发关闭阀门的信号,从而避免泄漏。
物联网和大数据分析
主题公园的例子可以让你很容易理解,但是和许多现实世界中物联网收集数据的操作相比,就显得小菜一碟了。许多大数据业务都会使用到来自物联网设备收集的信息,然后与其他数据关联,这样就可以分析预测到人类的行为。Software Advice 给出了一些例子,其中包括由 Birst 提供的一项服务,该服务将从联网的咖啡机中收集的咖啡冲泡的信息与社交媒体上发布的帖子进行匹配,看看顾客是否在网上谈论咖啡品牌。
另一个最近才发生的戏剧性的例子,X-Mode 发布了一张基于位置追踪数据的地图,地图上显示了在 2020 年 3 月春假的时候,正当新冠病毒在美国加速传播的时候,人们在 劳德代尔堡 聚会完最终都去了哪里。这张地图令人震撼,不仅仅是因为它显示出病毒可能的扩散方向,更是因为它说明了物联网设备是可以多么密切地追踪我们。(更多关于物联网和分析的信息,请点击此处。)
物联网数据和 AI
物联网设备能够收集的数据量远远大于任何人类能够以有效的方式处理的数据量,而且这肯定也不是能实时处理的。我们已经看到,仅仅为了理解从物联网终端传来的原始数据,就需要边缘计算设备。此外,还需要检测和处理可能就是完全错误的数据。
许多物联网供应商也同时提供机器学习和人工智能的功能,可以用来理解收集来的数据。比如,IBM 的 Jeopardy!-winning Watson 平台就可以在物联网数据集上进行训练,这样就可以在预测性维护领域产生有用的结果 —— 比如说,分析来自无人机的数据,可以区分桥梁上轻微的损坏和需要重视的裂缝。同时,ARM 也在研发低功耗芯片,它可以在物联网终端上提供 AI 的能力。
物联网和商业
物联网的商业用途包括跟踪客户、库存和重要部件的状态。IoT for All 列举了四个已经被物联网改变的行业:
- 石油和天然气:与人工干预相比,物联网传感器可以更好的检测孤立的钻井现场。
- 农业:通过物联网传感器获得的田间作物的数据,可以用来提高产量。
- 采暖通风:制造商可以监控全国各地的气候控制系统。
- 实体零售:当顾客在商店的某些地方停留的时候,可以通过手机进行微目标定位,提供优惠信息。
更普遍的情况是,企业正在寻找能够在四个领域上获得帮助的物联网解决方案:能源使用、资产跟踪、安全领域和客户体验。
via: https://www.networkworld.com/article/3207535/what-is-iot-the-internet-of-things-explained.html
作者:Josh Fruhlinger 选题:lujun9972 译者:Yufei-Yan 校对:wxy