Collision
一个让你查看你的文件哈希值,以确定它不是恶意文件,并且确实来自真实来源的图形界面程序。

有人给你发送了一个文件,你怎样来证实它是给你的原件?你怎样来确定它没有被篡改过?
同时,你怎么证实这个文件是来自一个原始的真实来源。
这就是加密哈希的重要作用所在。如果用来验证一个文件,诸如 SHA-1 之类的哈希功能就是一个校验值。这能够帮助你确认文件是否已经被修改。
如果你感到好奇,你可以参考我们的 在 Linux 中验证校验值的指南。
对每个信息 / 文件来说,它们有一个唯一的哈希值(或者叫校验和)。所以,即使文件有一点点的改动,整个哈希值就会发生变化。
它主要用于加密中,每个文件 / 信息以哈希值安全的存储。假设一个攻击者掌握了存储哈希值(而不是真实信息)的数据库,他们也不能够知道其意义。加密可以使存储更加安全。
虽然讨论哈希超出了这篇文章的范围,但是了解它在验证文件完整性上是很有意义的。
Collision:迅速的验证文件并发现恶意文件
如果没有图形界面,你就得用终端去生成哈希值来比对 / 验证。
Collision 使它变的非常容易,不需要打开终端或者生成文件的校验值。如果你不了解的话,我们的 在 Linux 中验证校验值的指南 可以帮助到你。
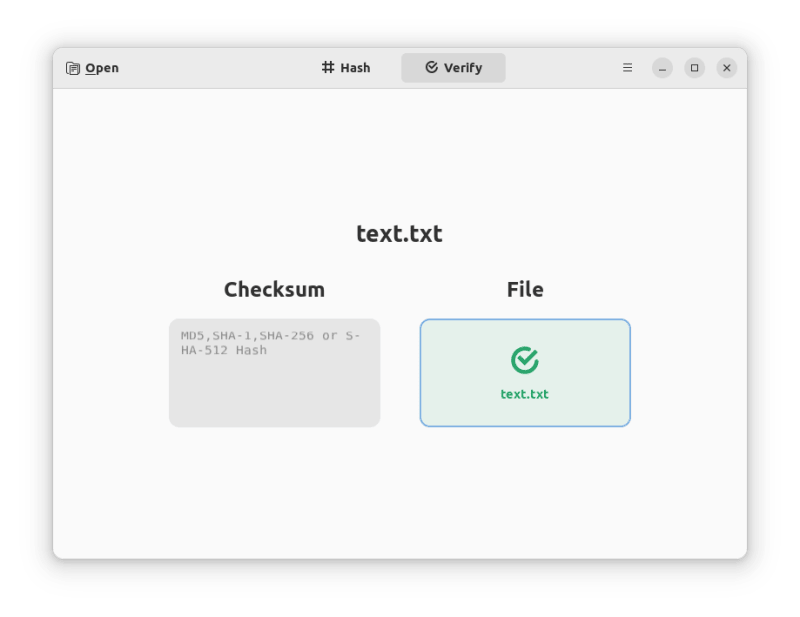
当使用 Collision 时, 你只需要添加你要生成哈希值或者验证所需的文件即可。你只需点击几下便能够保护自己免受恶意或篡改文件的攻击。
我在截图中显示了个文本文件,你的文件在发送给其他人之前,你可以验证各种类型文件或为你的文件生成一个哈希值。你可以通过发给收件人分享你生成的哈希值,让他们验证你的文件。
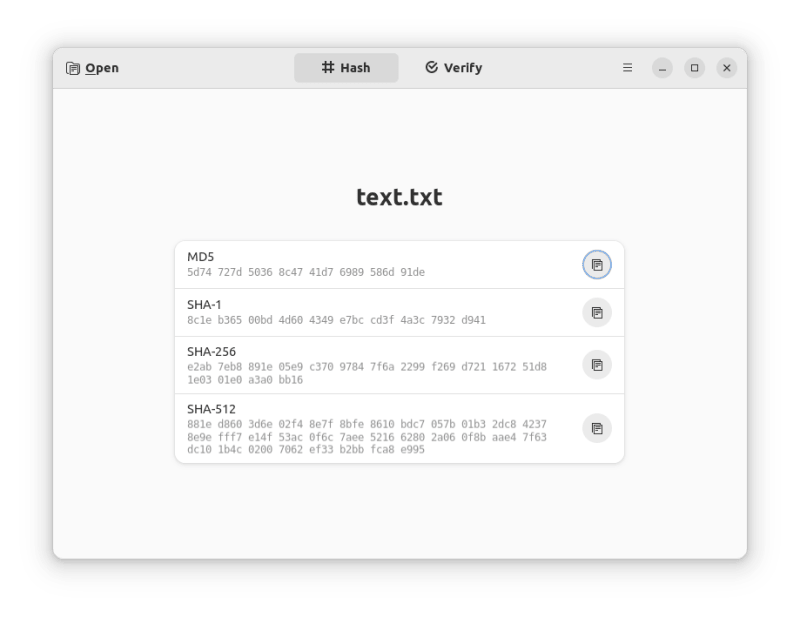
这是一款简单的开源应用,它只帮你做两件事情:
- 生成哈希值(SHA-1、MD5、SHA-256、SHA-516)
- 通过直接使用文件或者校验值验证一个项目
Collision 是怎么工作的
给你举个例子,我修改原来的文本文件,为其添加一个字母,然后尝试验证它。
下面是它的过程:
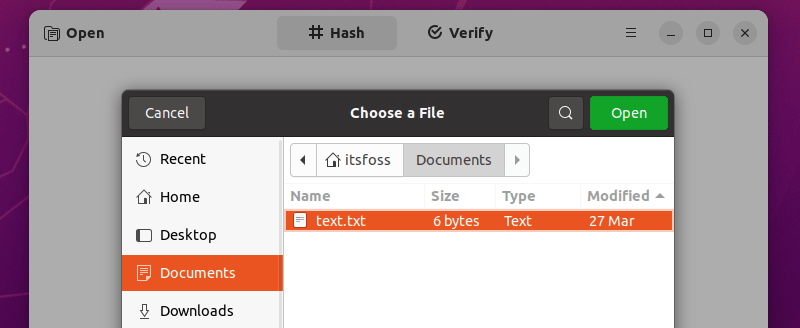
首先,你需要打开你要比对的原文件或者有校验值的原文件。
打开原文件生成哈希值,然后去验证区查看修改后的文件。
你会注意到,它们俩个不是相同的:

如果你在按校验值检查文件,首先,你要打开你要验证的文件(这儿是我们已经修改后的文件)。
然后,输入文件的原始真实校验值。当然我们已经知道我们测试的是修改后的文件,结果是我们所期望的,即,验证文件完整性失败。

在 Linux 安装 Collision
Collisions 主要是一个为 GNOME 定制的程序,但是它也适用于其他发行版上。
你可以使用 Flatpak 可用软件包 来安装它,或者浏览 GitHub 网页,从源码中编译它。如果你是 Linux 新手,你可以参考我们的 Flatpak 指南 来得到帮助。
如果你喜欢使用终端来安装,键入以下命令来安装:
flatpak install flathub dev.geopjr.Collision
你也可以访问它的官方网站。
Collision
via: https://itsfoss.com/collision/
作者:Ankush Das 选题:lujun9972 译者:hwlife 校对:wxy