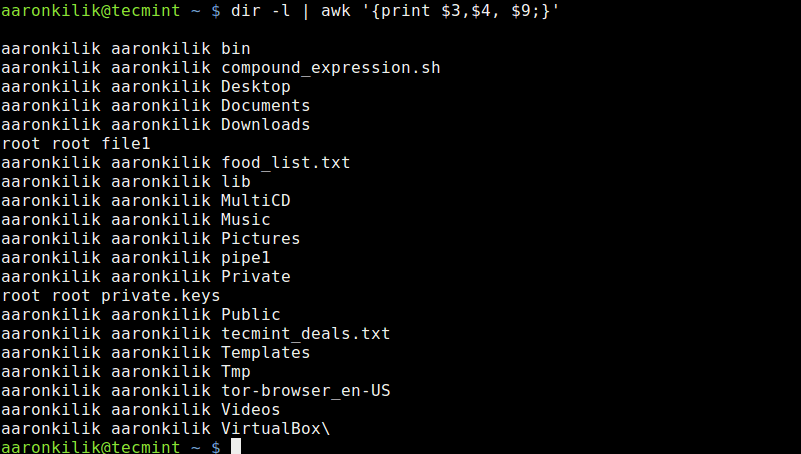
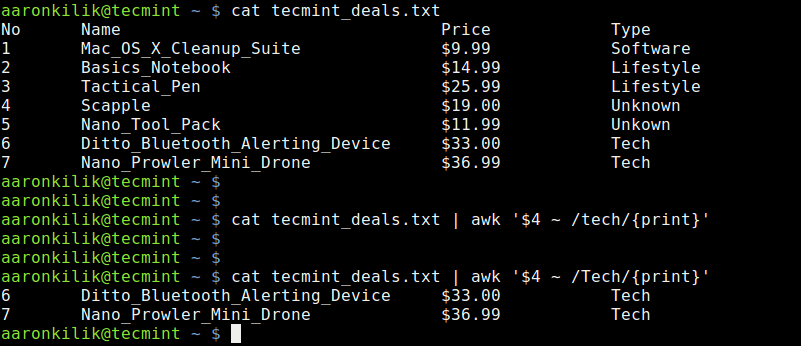
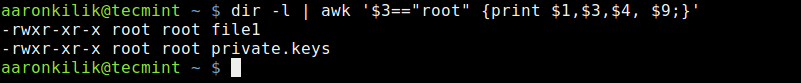Linux 上 10 个最好的 Markdown 编辑器
在这篇文章中,我们会点评一些可以在 Linux 上安装使用的最好的 Markdown 编辑器。 你可以在 Linux 平台上找到非常多的 的 Markdown 编辑器,但是在这里我们将尽可能地为您推荐那些最好的。
Best Linux Markdown Editors
对于不了解 Markdown 的人做个简单介绍,Markdown 是由著名的 Aaron Swartz 和 John Gruber 发明的标记语言,其最初的解析器是一个用 Perl 写的简单、轻量的同名工具。它可以将用户写的纯文本转为可用的 HTML(或 XHTML)。它实际上是一门易读,易写的纯文本语言,以及一个用于将文本转为 HTML 的转换工具。
希望你先对 Markdown 有一个稍微的了解,接下来让我们逐一列出这些编辑器。
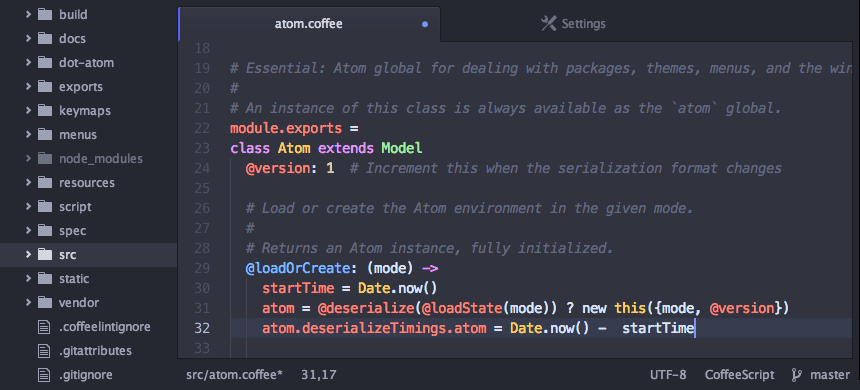
1. Atom
Atom 是一个现代的、跨平台、开源且强大的文本编辑器,它可以运行在 Linux、Windows 和 MAC OS X 等操作系统上。用户可以在它的基础上进行定制,删减修改任何配置文件。
它包含了一些非常杰出的特性:
- 内置软件包管理器
- 智能自动补全功能
- 提供多窗口操作
- 支持查找替换功能
- 包含一个文件系统浏览器
- 轻松自定义主题
- 开源、高度扩展性的软件包等
Atom Markdown Editor for Linux
访问主页: https://atom.io/
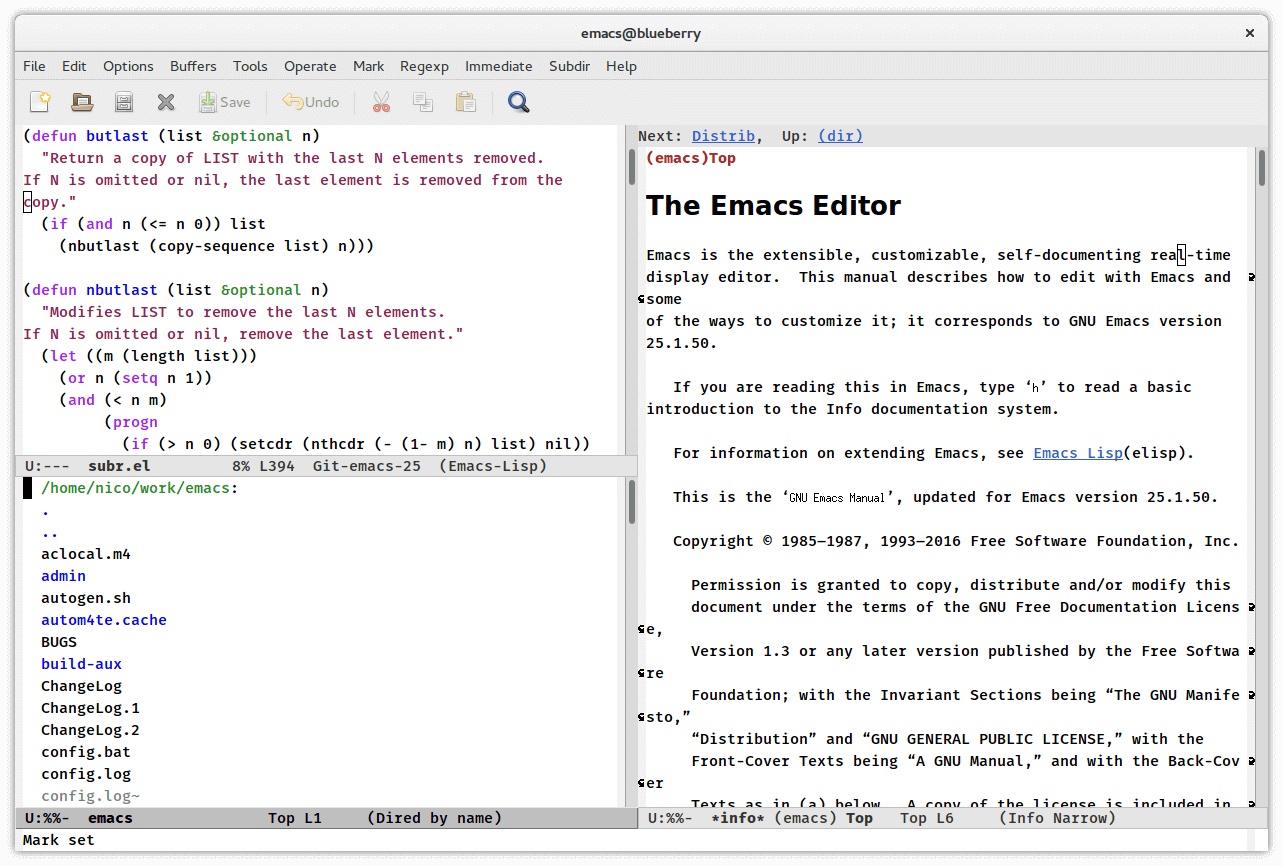
2. GNU Emacs
Emacs 是 Linux 平台上一款的流行文本编辑器。它是一个非常棒的、具备高扩展性和定制性的 Markdown 语言编辑器。
它综合了以下这些神奇的特性:
- 带有丰富的内置文档,包括适合初学者的教程
- 有完整的 Unicode 支持,可显示所有的人类符号
- 支持内容识别的文本编辑模式
- 包括多种文件类型的语法高亮
- 可用 Emacs Lisp 或 GUI 对其进行高度定制
- 提供了一个包系统可用来下载安装各种扩展等
Emacs Markdown Editor for Linux
访问主页: https://www.gnu.org/software/emacs/
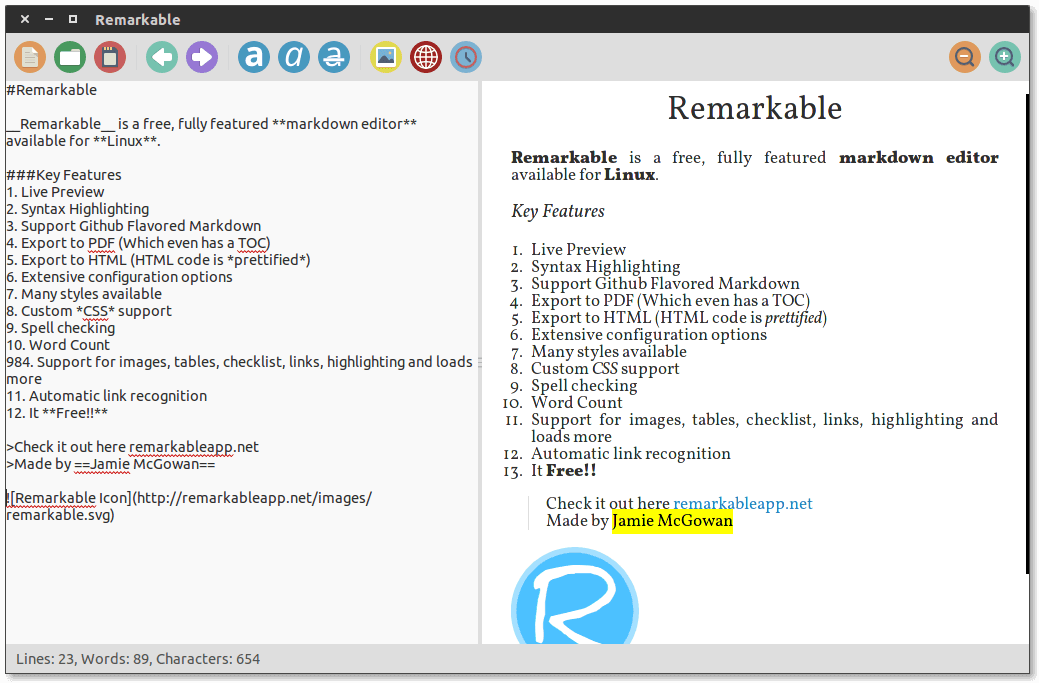
3. Remarkable
Remarkable 可能是 Linux 上最好的 Markdown 编辑器了,它也适用于 Windows 操作系统。它的确是是一个卓越且功能齐全的 Markdown 编辑器,为用户提供了一些令人激动的特性。
一些卓越的特性:
- 支持实时预览
- 支持导出 PDF 和 HTML
- 支持 Github Markdown 语法
- 支持定制 CSS
- 支持语法高亮
- 提供键盘快捷键
- 高可定制性和其他
Remarkable Markdown Editor for Linux
访问主页: https://remarkableapp.github.io
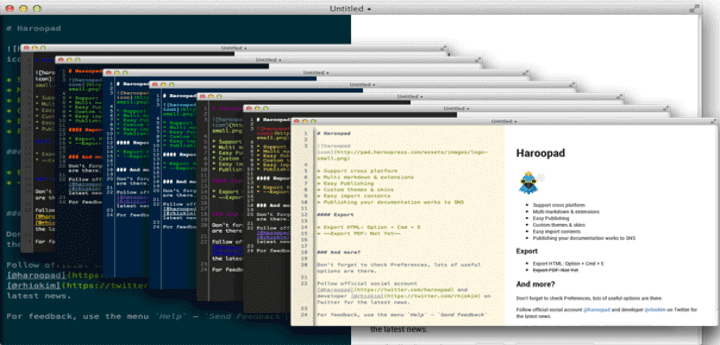
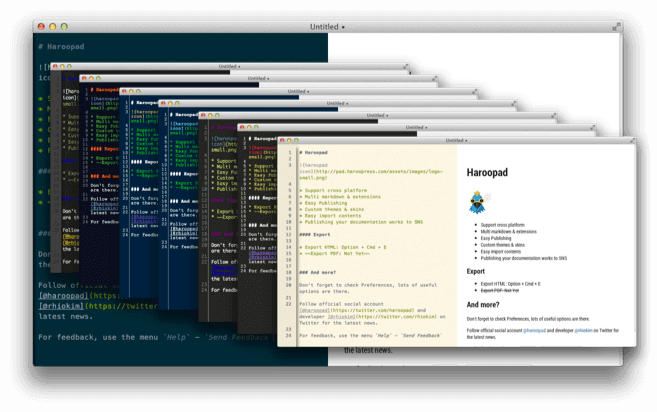
4. Haroopad
Haroopad 是为 Linux,Windows 和 Mac OS X 构建的跨平台 Markdown 文档处理程序。用户可以用它来书写许多专家级格式的文档,包括电子邮件、报告、博客、演示文稿和博客文章等等。
功能齐全且具备以下的亮点:
- 轻松导入内容
- 支持导出多种格式
- 广泛支持博客和邮件
- 支持许多数学表达式
- 支持 Github Markdown 扩展
- 为用户提供了一些令人兴奋的主题、皮肤和 UI 组件等等
Haroopad Markdown Editor for Linux
访问主页: http://pad.haroopress.com/
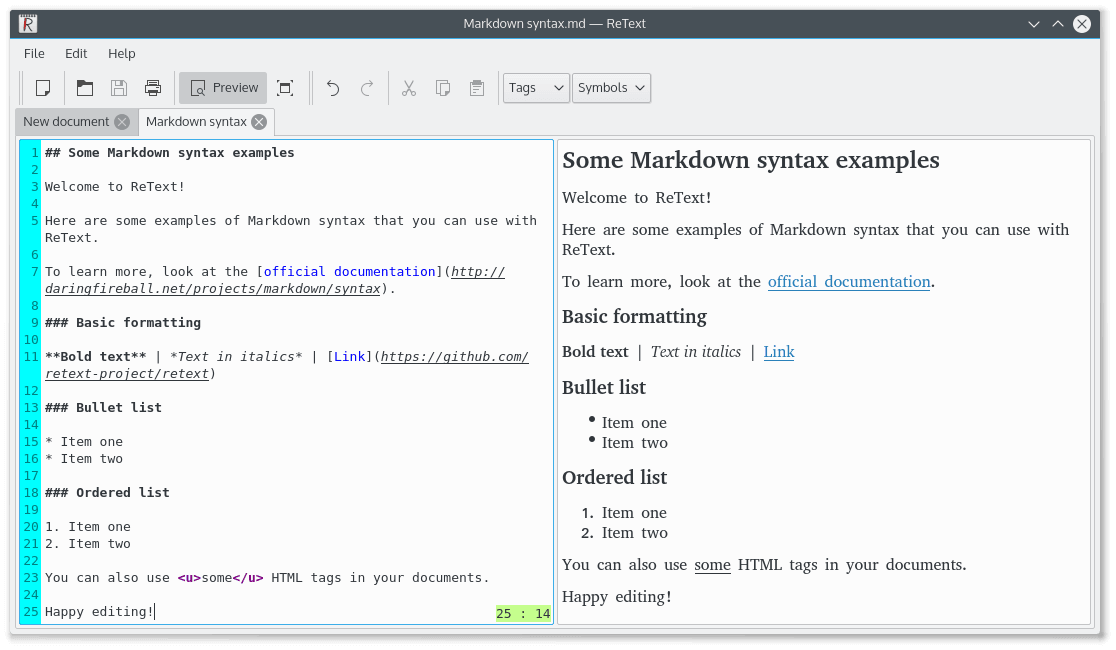
5. ReText
ReText 是为 Linux 和其它几个 POSIX 兼容操作系统提供的简单、轻量、强大的 Markdown 编辑器。它还可以作为一个 reStructuredText 编辑器,并且具有以下的特性:
- 简单直观的 GUI
- 具备高定制性,用户可以自定义语法文件和配置选项
- 支持多种配色方案
- 支持使用多种数学公式
- 启用导出扩展等等
ReText Markdown Editor for Linux
访问主页: https://github.com/retext-project/retext
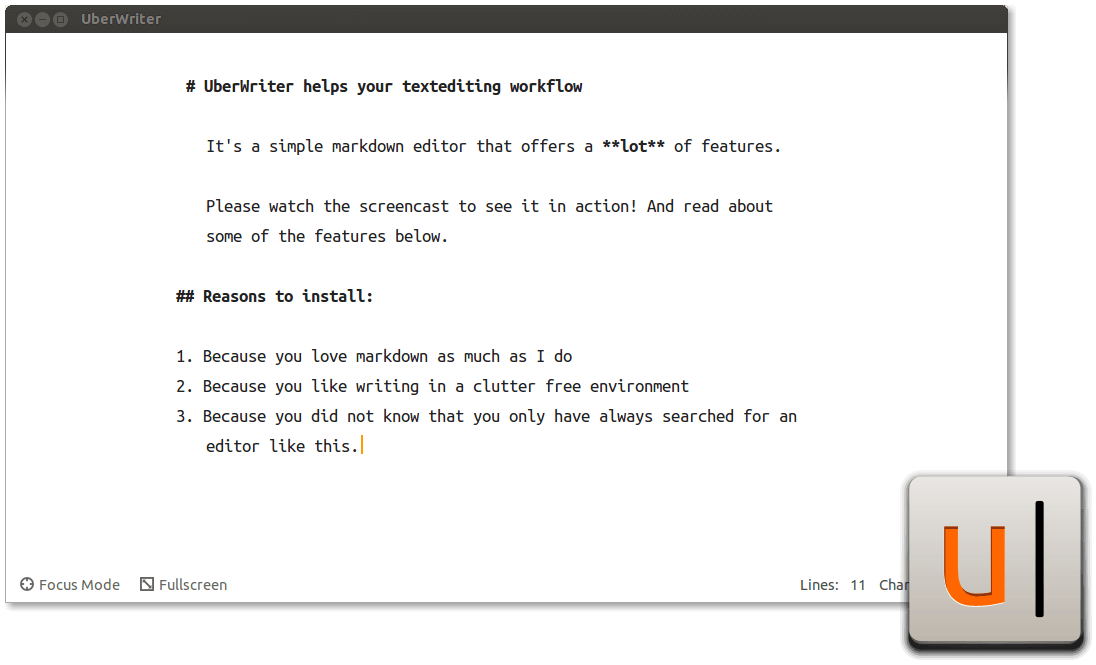
6. UberWriter
UberWriter 是一个简单、易用的 Linux Markdown 编辑器。它的开发受 Mac OS X 上的 iA writer 影响很大,同样它也具备这些卓越的特性:
- 使用 pandoc 进行所有的文本到 HTML 的转换
- 提供了一个简洁的 UI 界面
- 提供了一种 专心 模式,高亮用户最后的句子
- 支持拼写检查
- 支持全屏模式
- 支持用 pandoc 导出 PDF、HTML 和 RTF
- 启用语法高亮和数学函数等等
UberWriter Markdown Editor for Linux
访问主页: http://uberwriter.wolfvollprecht.de/
7. Mark My Words
Mark My Words 同样也是一个轻量、强大的 Markdown 编辑器。它是一个相对比较新的编辑器,因此提供了包含语法高亮在内的大量的功能,简单和直观的 UI。
下面是一些棒极了,但还未捆绑到应用中的功能:
- 实时预览
- Markdown 解析和文件 IO
- 状态管理
- 支持导出 PDF 和 HTML
- 监测文件的修改
- 支持首选项设置
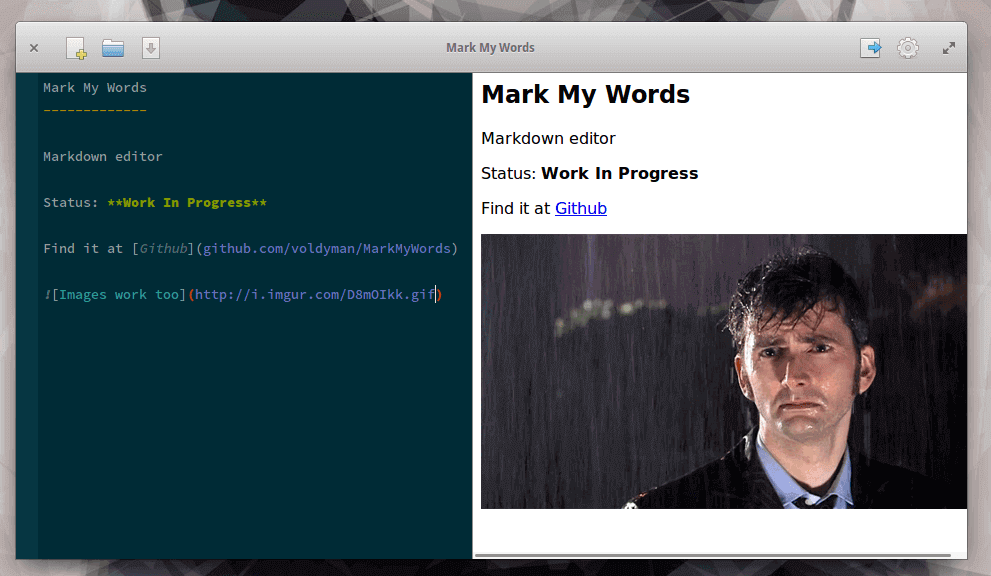
MarkMyWords Markdown Editor for-Linux
访问主页: https://github.com/voldyman/MarkMyWords
8. Vim-Instant-Markdown 插件
Vim 是 Linux 上的一个久经考验的强大、流行而开源的文本编辑器。它用于编程极棒。它也高度支持插件功能,可以让用户为其增加一些其它功能,包括 Markdown 预览。
有好几种 Vim 的 Markdown 预览插件,但是 Vim-Instant-Markdown 的表现最佳。
9. Bracket-MarkdownPreview 插件
Brackets 是一个现代、轻量、开源且跨平台的文本编辑器。它特别为 Web 设计和开发而构建。它的一些重要功能包括:支持内联编辑器、实时预览、预处理支持及更多。
它也是通过插件高度可扩展的,你可以使用 Bracket-MarkdownPreview 插件来编写和预览 Markdown 文档。
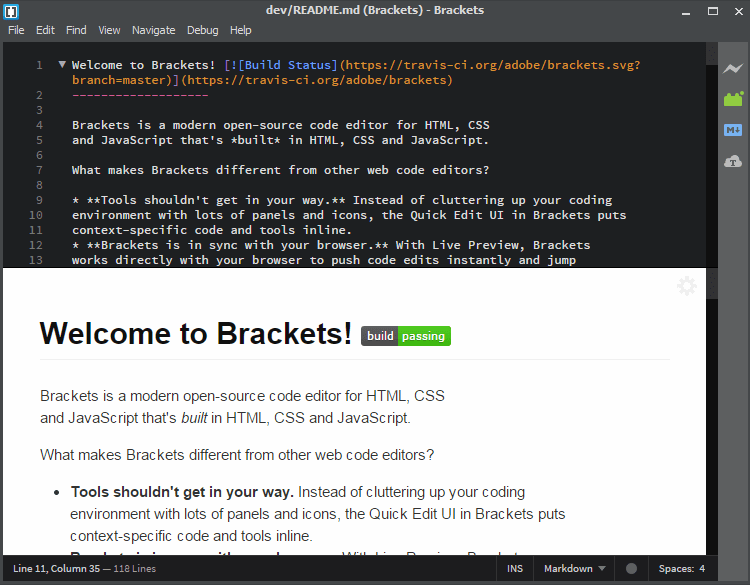
Brackets Markdown Plugin Preview
10. SublimeText-Markdown 插件
Sublime Text 是一个精心打造的、流行的、跨平台文本编辑器,用于代码、markdown 和普通文本。它的表现极佳,包括如下令人兴奋的功能:
- 简洁而美观的 GUI
- 支持多重选择
- 提供专心模式
- 支持窗体分割编辑
- 通过 Python 插件 API 支持高度插件化
- 完全可定制化,提供命令查找模式
SublimeText-Markdown 插件是一个支持格式高亮的软件包,带有一些漂亮的颜色方案。
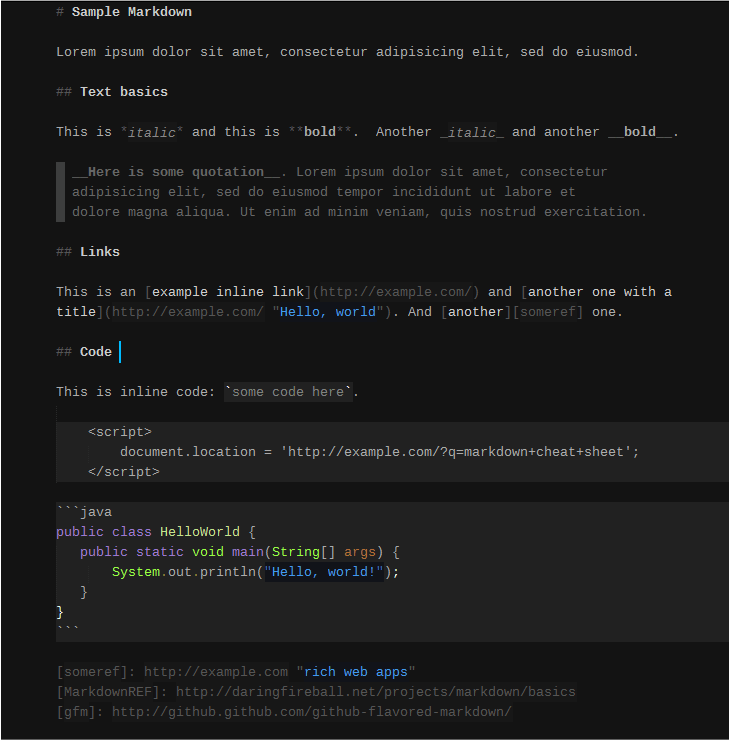
SublimeText Markdown Plugin Preview
结论
通过上面的列表,你大概已经知道要为你的 Linux 桌面下载、安装什么样的 Markdown 编辑器和文档处理程序了。
请注意,这里提到的最好的 Markdown 编辑器可能对你来说并不是最好的选择。因此你可以通过下面的反馈部分,为我们展示你认为列表中未提及的,并且具备足够的资格的,令人兴奋的 Markdown 编辑器。
via: http://www.tecmint.com/best-markdown-editors-for-linux/
作者:Aaron Kili 译者:Locez 校对:wxy