安装 pip 轻松管理 PyPI 软件包
在 Linux、Mac 或 Windows 上为旧版 Python 安装 pip。

Python 是一种功能强大、流行广泛的编程语言,在常规编程、数据科学等很多方面它都有丰富的软件包可供使用。但这些软件包通常都不会在 Python 安装时自动附带,而是需要由用户自行下载、安装和管理。所有的这些软件包(包括库和框架)都存放在一个名叫 PyPI(也就是 Python 软件包索引 )的中央存储库当中,而 pip(也就是 首选安装程序 )则是管理这个中央存储库的工具。
在安装 pip 之后,管理 PyPI 的软件包就变得很方便了。大部分的软件包都可以通过在终端或者命令行界面执行 python -m pip install <软件包名> 这样的命令来完成安装。
较新版本的 Python 3(3.4 或以上)和 Python 2(2.7.9 或以上)都已经预装了 pip,旧版本的 Python 没有自带 pip,但可以另外安装。
在这篇文章中,我将会介绍 pip 在 Linux、Mac 和 Windows 系统上的安装过程。想要了解更多详细信息,可以参考 pip.pypa 的文档。
首先需要安装 Python
首先你的系统中需要安装好 Python,否则 pip 安装器无法理解任何相关的命令。你可以在命令行界面、Bash 或终端执行 python 命令确认系统中是否已经安装 Python,如果系统无法识别 python 命令,请先下载 Python 并安装。安装完成后,你就可以看到一些引导你安装 pip 的提示语了。
在 Linux 上安装 pip
在不同发行版的 Linux 上,安装 pip 的命令也有所不同。
在 Fedora、RHEL 或 CentOS 上,执行以下命令安装:
$ sudo dnf install python3在 Debian 或 Ubuntu 上,使用 apt 包管理工具安装:
$ sudo apt install python3-pip其它的发行版可能还会有不同的包管理工具,比如 Arch Linux 使用的是 pacman:
$ sudo pacman -S python-pip执行 pip --version 命令就可以确认 pip 是否已经正确安装。
在 Linux 系统上安装 pip 就是这样简单,你可以直接跳到“使用 pip”部分继续阅读。
在 Mac 上安装 pip
MacOS 已经预装了 Python,但 Python 版本一般是比较旧的。如果你要使用 Python 的话,建议另外安装 Python 3。
在 Mac 上可以使用 homebrew 安装 Python 3:
$ brew update && brew upgrade python如果你安装的是以上提到的新版本 Python 3,它会自带 pip 工具。你可以使用以下命令验证:
$ python3 -m pip --version如果你使用的是 Mac,安装过程也到此结束,可以从“使用 pip”部分继续阅读。
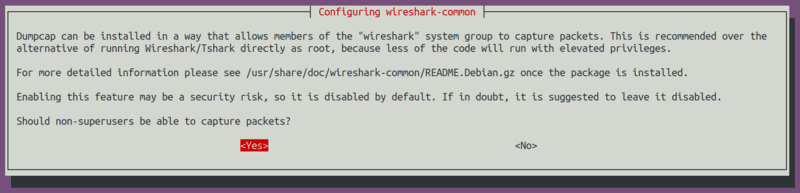
在 Windows 上安装 pip
以下 pip 安装过程是针对 Windows 8 和 Windows 10 的。下面文章中的截图是 Windows 10 环境下的截图,但对 Windows 8 同样适用。
首先确认 Python 已经安装完成。
如果你想在 Windows 系统上像 Linux 一样使用包管理工具,Chocolatey 是一个不错的选择,它可以让 Python 的调用和更新变得更加方便。Chocolatey 在 PowerShell 中就可以运行,只需要简单的命令,Python 就可以顺利安装。
PS> choco install python接下来就可以使用 pip 安装所需的软件包了。
使用 pip
在 Linux、BSD、Windows 和 Mac 上,pip 都是以同样的方式使用的。
例如安装某个库:
python3 -m pip install foo --user卸载某个已安装的库:
python3 -m pip uninstall foo按照名称查找软件包:
python3 -m pip search foo将 pip 更新到一个新版本:
$ sudo pip install --upgrade pip需要注意的是,在 Windows 系统中不需要在前面加上 sudo 命令,这是因为 Windows 通过独有的方式管理用户权限,对应的做法是创建一个执行策略例外。
python -m pip install --upgrade pip希望本文介绍的的方法能对你有所帮助,欢迎在评论区分享你的经验。
via: https://opensource.com/article/20/3/pip-linux-mac-windows
作者:Vijay Singh Khatri 选题:lujun9972 译者:HankChow 校对:wxy