量子计算的开源框架 Cirq 介绍
我们即将讨论的内容正如标题所示,本文通过使用 Cirq 的一个开源视角,尝试去了解我们已经在量子计算领域取得多大的成就,和该领域的发展方向,以加快科学和技术研究。
首先,我们将引领你进入量子计算的世界。在我们深入了解 Cirq 在未来的量子计算中扮演什么样的重要角色之前,我们将尽量向你解释其背后的基本概念。你最近可能听说过,在这个领域中有件重大新闻,就是 Cirq。在这篇开放科学栏目的文章中,我们将去尝试找出答案。
在我们开始了解量子计算之前,必须先去了解“量子”这个术语,量子是已知的 亚原子粒子 中最小的物质。 量子 这个词来自拉丁语 Quantus,意思是 “有多小”,在下面的短视频链接中有描述:
为了易于我们理解量子计算,我们将 量子计算 与 经典计算 (LCTT 译注:也有译做“传统计算”)进行比较。经典计算是指今天的传统计算机如何设计工作的,正如你现在用于阅读本文的设备,就是我们所谓的经典计算设备。
经典计算
经典计算只是描述计算机如何工作的另一种方式。它们通过一个二进制系统工作,即信息使用 1 或 0 来存储。经典计算机不会理解除 1 或 0 之外的任何其它东西。
直白来说,在计算机内部一个晶体管只能是开(1)或关(0)。我们输入的任何信息都被转换为无数个 1 和 0,以便计算机能理解和存储。所有的东西都只能用无数个 1 和 0 的组合来表示。
量子计算
然而,量子计算不再像经典计算那样遵循 “开或关” 的模式。而是,借助量子的名为 叠加和纠缠 的两个现象,能同时处理信息的多个状态,因此能以更快的速率加速计算,并且在信息存储方面效率更高。
请注意,叠加和纠缠 不是同一个现象。
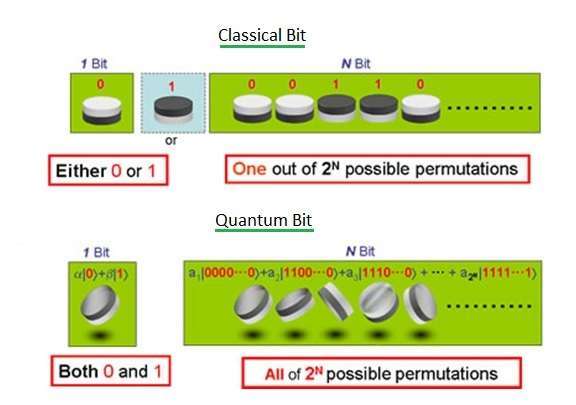
就像在经典计算中,我们有 比特 ,在量子计算中,我们相应也有 量子比特 (即 Quantum bit)。想了解它们二者之间的巨大差异之处,请查看这个 页面,从那里的图片中可以得到答案。
量子计算机并不是来替代我们的经典计算机的。但是,有一些非常巨大的任务用我们的经典计算机是无法完成的,而那些正是量子计算机大显身手的好机会。下面链接的视频详细描述了上述情况,同时也描述了量子计算机的原理。
下面的视频全面描述了量子计算领域到目前为止的最新进展:
嘈杂中型量子
根据最新更新的(2018 年 7 月 31 日)研究论文,术语 “ 嘈杂 ” 是指由于对量子比特未能完全控制所产生的不准确性。正是这种不准确性在短期内严重制约了量子设备实现其目标。
“中型” 指的是在接下来的几年中,量子计算机将要实现的量子规模大小,届时,量子比特的数目将可能从 50 到几百个不等。50 个量子比特是一个重大的量程碑,因为它将超越现有的最强大的 超级计算机 的 暴力破解 所能比拟的计算能力。更多信息请阅读 这里的 论文。
随着 Cirq 出现,许多事情将会发生变化。
Cirq 是什么?
Cirq 是一个 Python 框架,它用于创建、编辑和调用我们前面讨论的嘈杂中型量子(NISQ)。换句话说,Cirq 能够解决挑战,去改善精确度和降低量子计算中的噪声。
Cirq 并不需要必须有一台真实的量子计算机。Cirq 能够使用一个类似模拟器的界面去执行量子电路模拟。
Cirq 的前进步伐越来越快了,Zapata 是使用它的首批用户之一,Zapata 是由来自哈佛大学的专注于量子计算的一群科学家在去年成立的。
Linux 上使用 Cirq 入门
开源的 Cirq 库 开发者建议将它安装在像 virtualenv 这样的一个 虚拟 Python 环境 中。在 Linux 上的开发者安装指南可以在 这里 找到。
但我们在 Ubuntu 16.04 的系统上成功地安装和测试了 Python3 的 Cirq 库,安装步骤如下:
在 Ubuntu 上安装 Cirq

首先,我们需要 pip 或 pip3 去安装 Cirq。Pip 是推荐用于安装和管理 Python 包的工具。
对于 Python 3.x 版本,Pip 能够用如下的命令来安装:
sudo apt-get install python3-pipPython3 包能够通过如下的命令来安装:
pip3 install <package-name>我们继续去使用 Pip3 为 Python3 安装 Cirq 库:
pip3 install cirq启用 Plot 和 PDF 生成(可选)
可选系统的依赖没有被 Pip 安装的,可以使用如下命令去安装它:
sudo apt-get install python3-tk texlive-latex-base latexmk- python3-tk 是 Python 自有的启用了绘图功能的图形库
- texlive-latex-base 和 latexmk 启动了 PDF 输出功能。
最后,我们使用如下的命令和代码成功测试了 Cirq:
python3 -c 'import cirq; print(cirq.google.Foxtail)'我们得到的输出如下图:
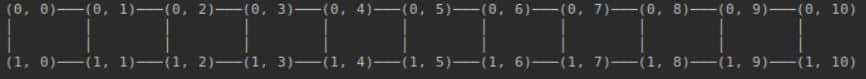
为 Cirq 配置 Pycharm IDE
我们也配置了一个 Python IDE PyCharm 去测试同样的结果:
因为在我们的 Linux 系统上为 Python3 安装了 Cirq,我们在 IDE 中配置项目解释器路径为:
/usr/bin/python3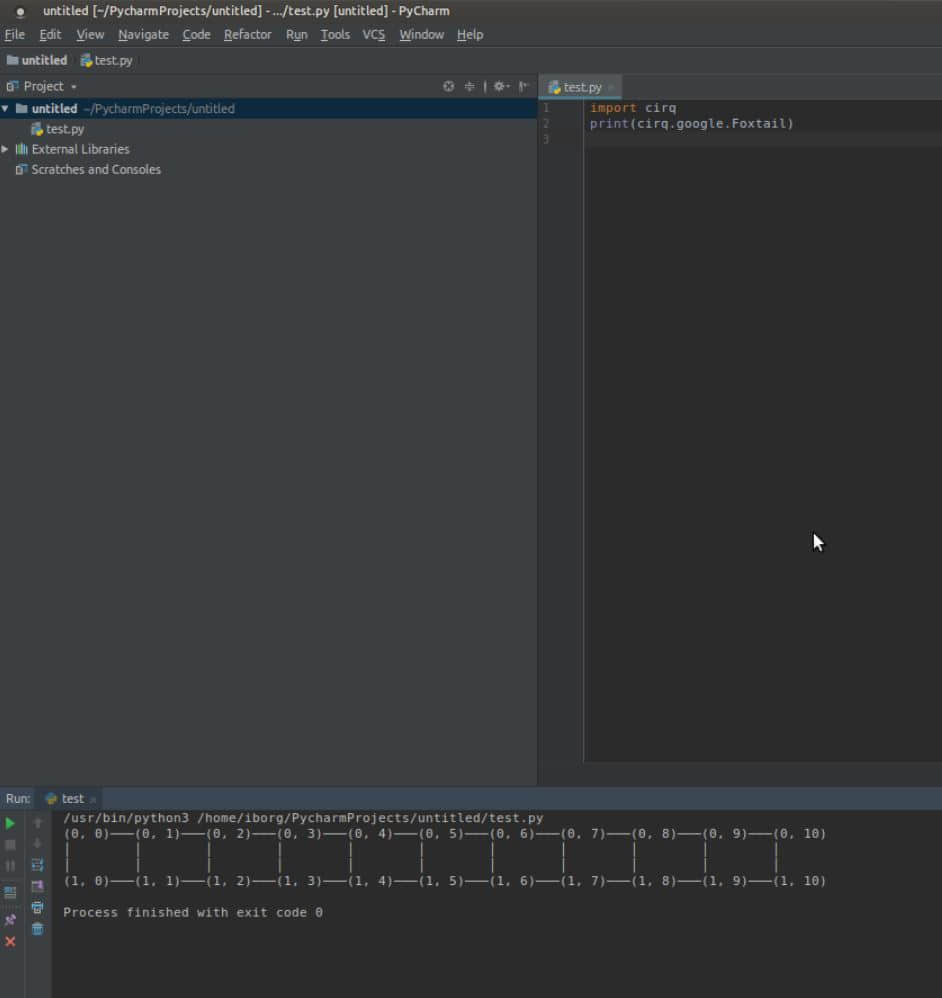
在上面的输出中,你可能注意到我们刚设置的项目解释器路径与测试程序文件(test.py)的路径显示在一起。退出代码 0 表示程序已经成功退出,没有错误。
因此,那是一个已经就绪的 IDE 环境,你可以导入 Cirq 库去开始使用 Python 去编程和模拟量子电路。
Cirq 使用入门
Criq 入门的一个好的开端就是它 GitHub 页面上的 示例。
Cirq 的开发者在 GitHub 上已经放置了学习 教程。如果你想认真地学习量子计算,他们推荐你去看一本非常好的书,它是由 Nielsen 和 Chuang 写的名为 《量子计算和量子信息》。
OpenFermion-Cirq
OpenFermion 是一个开源库,它是为了在量子计算机上模拟获取和操纵代表的费米系统(包含量子化学)。根据 粒子物理学 理论,按照 费米—狄拉克统计,费米系统与 费米子 的产生相关。
OpenFermion 被称为从事 量子化学 的化学家和研究人员的 一个极好的实践工具。量子化学主要专注于 量子力学 在物理模型和化学系统实验中的应用。量子化学也被称为 分子量子力学。
Cirq 的出现使 OpenFermion 通过提供程序和工具去扩展功能成为了可能,通过使用 Cirq 可以去编译和构造仿真量子电路。
Google Bristlecone
2018 年 3 月 5 日,在洛杉矶举行的一年一度的 美国物理学会会议 上,Google 发布了 Bristlecone,这是他们的最新的量子处理器。这个 基于门的超导系统 为 Google 提供了一个测试平台,用以研究 量子比特技术 的 系统错误率 和 扩展性 ,以及在量子 仿真、优化 和 机器学习 方面的应用。
Google 希望在不久的将来,能够制造出它的 云可访问 的 72 个量子比特的 Bristlecone 量子处理器。Bristlecone 将越来越有能力完成一个经典超级计算机无法在合理时间内完成的任务。
Cirq 将让研究人员直接在云上为 Bristlecone 写程序变得很容易,它提供了一个非常方便的、实时的、量子编程和测试的接口。
Cirq 将允许我们去:
- 量子电路的微调管理
- 使用原生门去指定 门 行为
- 在设备上放置适当的门
- 并调度这个门的时刻
开放科学关于 Cirq 的观点
我们知道 Cirq 是在 GitHub 上开源的,在开源科学社区之外,特别是那些专注于量子研究的人们,都可以通过高效率地合作,通过开发新方法,去降低现有量子模型中的错误率和提升精确度,以解决目前在量子计算中所面临的挑战。
如果 Cirq 不走开源模型的路线,事情可能变得更具挑战。一个伟大的创举可能就此错过,我们可能在量子计算领域止步不前。
总结
最后我们总结一下,我们首先通过与经典计算相比较,介绍了量子计算的概念,然后是一个非常重要的视频来介绍了自去年以来量子计算的最新发展。接着我们简单讨论了嘈杂中型量子,也就是为什么要特意构建 Cirq 的原因所在。
我们看了如何在一个 Ubuntu 系统上安装和测试 Cirq。我们也在一个更好用的 IDE 环境中做了安装测试,并使用一些资源去开始学习有关概念。
最后,我们看了两个示例 OpenFermion 和 Bristlecone,介绍了在量子计算中,Cirq 在开发研究中具有什么样的基本优势。最后我们以 Open Science 社区的视角对 Cirq 进行了一些精彩的思考,结束了我们的话题。
我们希望能以一种易于理解的方式向你介绍量子计算框架 Cirq 的使用。如果你有与此相关的任何反馈,请在下面的评论区告诉我们。感谢阅读,希望我们能在开放科学栏目的下一篇文章中再见。
via: https://itsfoss.com/qunatum-computing-cirq-framework/
作者:Avimanyu Bandyopadhyay 选题:lujun9972 译者:qhwdw 校对:wxy






