如何知道 CPU 是否支持虚拟化技术(VT)

我们已经知道如何检查你的 Linux 操作系统是 32 位还是 64 位以及如何知道你的 Linux 系统是物理机还是虚拟机。今天,我们将学习另一个有用的话题 - 如何知道 CPU 是否支持虚拟化技术 (VT)?在安装虚拟化程序(如 VirtualBox 或 VMWare workstation)以在 Linux 系统上运行虚拟机之前,你应该首先验证这一点。现在让我们来看看你的电脑是否支持 VT。相信我,这真的很简单!
了解 CPU 是否支持虚拟化技术 (VT)
我们可以通过几种方法检查 CPU 是否支持 VT。在这里我向你展示四种方法。
方法 1:使用 egrep 命令
egrep 是 grep 命令的变体之一,用于使用正则表达式搜索文本文件。为了本指南的目的,我们将 grep /cpu/procinfo/ 文件来确定 CPU 是否支持 VT。
要使用 egrep 命令查明你的CPU是否支持VT,请运行:
$ egrep "(svm|vmx)" /proc/cpuinfo
示例输出:
你将在输出中看到 vmx(Intel-VT 技术)或 svm (AMD-V 支持)。
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer xsave avx lahf_lm epb pti tpr_shadow vnmi flexpriority ept vpid xsaveopt dtherm arat pln pts
[...]
由于输出很长,你可能会发现很难在输出中找到 vmx 或 svm。别担心!你可以像下面那样用颜色来区分这些术语。
$ egrep --color -i "svm|vmx" /proc/cpuinfo
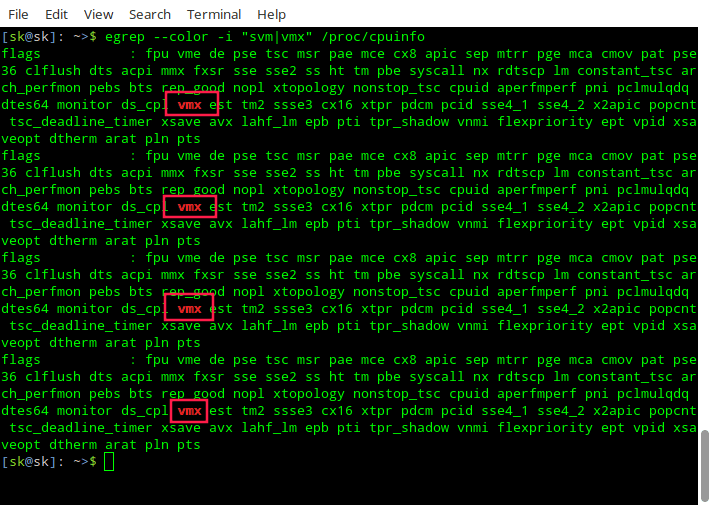
如果你没有看到任何输出,这意味着你的系统不支持虚拟化。
请注意,cpuinfo 中的这些 CPU 标志(vmx 或 svm)表示你的系统支持 VT。在某些 CPU 型号中,默认情况下,可能会在 BIOS 中禁用 VT 支持。在这种情况下,你应该检查 BIOS 设置以启用 VT 支持。
有关 grep/egrep 命令的更多详细信息,请参阅手册页。
$ man grep
方法 2: 使用 lscpu 命令
lscpu 命令用于显示有关 CPU 架构的信息。它从 sysfs、/proc/cpuinfo 收集信息,并显示主机系统的 CPU、线程、内核、套接字和非统一内存访问 (NUMA) 节点的数量。
要确定是否启用 VT 支持,只需运行:
$ lscpu
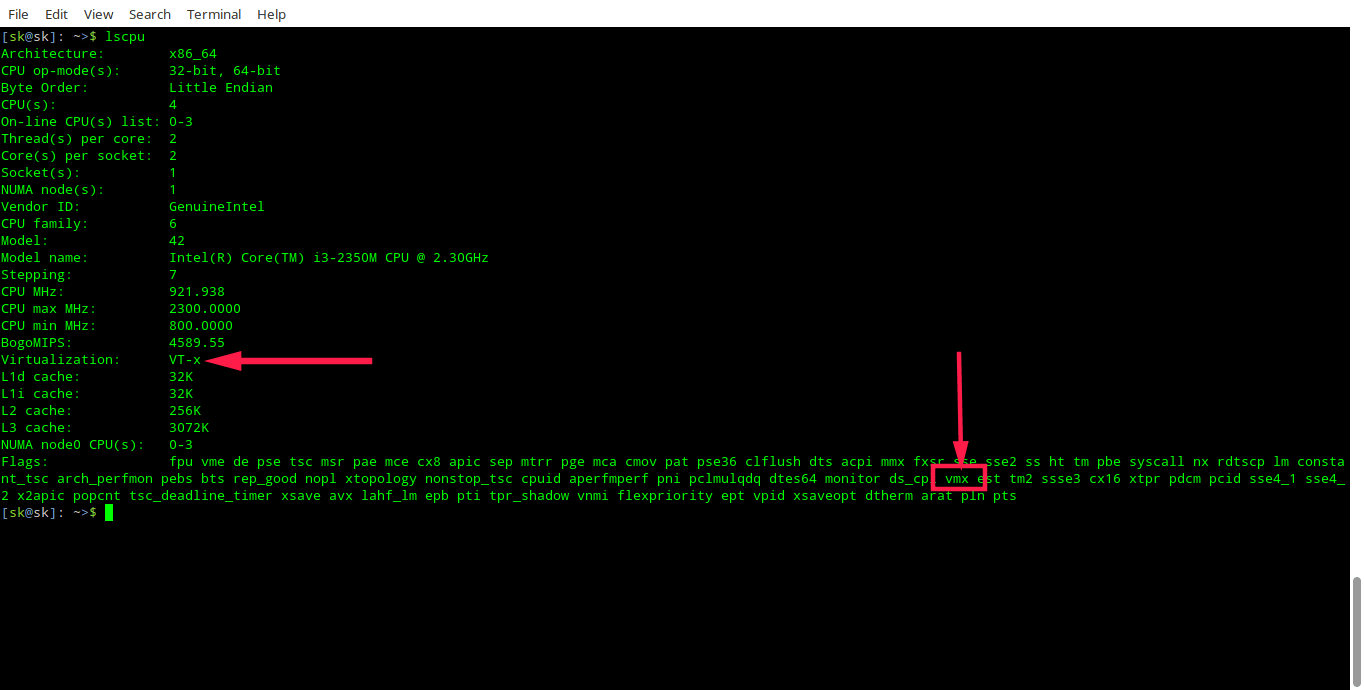
有关更多详细信息,请查看手册页。
$ man lscpu
方法 3:使用 cpu-checker 工具
cpu-checker 是另一个有用的工具,用于测试你的 CPU 是否支持虚拟化。就我在网上搜索得到的,该程序仅适用于基于 Ubuntu 的系统。要安装它,请运行:
$ sudo apt-get install cpu-checker
安装 cpu-checker 包之后,运行以下命令来检查是否启用 VT 支持:
$ sudo kvm-ok
如果您的 CPU 支持 VT,你将得到以下输出:
INFO: /dev/kvm exists
KVM acceleration can be used
如果你的 CPU 不支持 VT,你会看到如下的输出。
INFO: Your CPU does not support KVM extensions
KVM acceleration can NOT be used
方法 4:使用 virt-host-validate 工具
该工具专门用于基于 RHEL 的发行版,如 CentOS 和 Scientific Linux。 libvirt-client 包提供 virt-host-validate 二进制文件。所以你需要安装 libvert-client 包来使用这个工具。
$ sudo yum install libvirt-client
现在,运行 virt-host-validate 命令来确定基于 RHEL 的系统中是否启用了 VT。
$ sudo virt-host-validate
如果所有的结果是 pass,那么你的系统支持 VT。
QEMU: Checking for hardware virtualization : PASS
QEMU: Checking if device /dev/vhost-net exists : PASS
QEMU: Checking if device /dev/net/tun exists : PASS
QEMU: Checking for cgroup 'memory' controller support : PASS
QEMU: Checking for cgroup 'memory' controller mount-point : PASS
QEMU: Checking for cgroup 'cpu' controller support : PASS
QEMU: Checking for cgroup 'cpu' controller mount-point : PASS
QEMU: Checking for cgroup 'cpuacct' controller support : PASS
QEMU: Checking for cgroup 'cpuacct' controller mount-point : PASS
QEMU: Checking for cgroup 'cpuset' controller support : PASS
QEMU: Checking for cgroup 'cpuset' controller mount-point : PASS
QEMU: Checking for cgroup 'devices' controller support : PASS
QEMU: Checking for cgroup 'devices' controller mount-point : PASS
QEMU: Checking for cgroup 'blkio' controller support : PASS
QEMU: Checking for cgroup 'blkio' controller mount-point : PASS
QEMU: Checking for device assignment IOMMU support : PASS
LXC: Checking for Linux >= 2.6.26 : PASS
LXC: Checking for namespace ipc : PASS
LXC: Checking for namespace mnt : PASS
LXC: Checking for namespace pid : PASS
LXC: Checking for namespace uts : PASS
LXC: Checking for namespace net : PASS
LXC: Checking for namespace user : PASS
LXC: Checking for cgroup 'memory' controller support : PASS
LXC: Checking for cgroup 'memory' controller mount-point : PASS
LXC: Checking for cgroup 'cpu' controller support : PASS
LXC: Checking for cgroup 'cpu' controller mount-point : PASS
LXC: Checking for cgroup 'cpuacct' controller support : PASS
LXC: Checking for cgroup 'cpuacct' controller mount-point : PASS
LXC: Checking for cgroup 'cpuset' controller support : PASS
LXC: Checking for cgroup 'cpuset' controller mount-point : PASS
LXC: Checking for cgroup 'devices' controller support : PASS
LXC: Checking for cgroup 'devices' controller mount-point : PASS
LXC: Checking for cgroup 'blkio' controller support : PASS
LXC: Checking for cgroup 'blkio' controller mount-point : PASS
如果你的系统不支持 VT,你会看到下面的输出。
QEMU: Checking for hardware virtualization : FAIL (Only emulated CPUs are available, performance will be significantly limited)
[...]
就是这样了。在本文中,我们讨论了确定 CPU 是否支持 VT 的不同方法。如你所见,这很简单。希望这个有用。还有更多好的东西。敬请关注!
干杯!
via: https://www.ostechnix.com/how-to-find-if-a-cpu-supports-virtualization-technology-vt/