如何让网站不下线而从 Redis 2 迁移到 Redis 3
我们在 Sky Betting&Gaming 中使用 Redis 作为共享内存缓存,用于那些需要跨 API 服务器或者 Web 服务器鉴别令牌之类的操作。在 Core Tribe 内,它用来帮助处理日益庞大的登录数量,特别是在繁忙的时候,我们在一分钟内登录数量会超过 20,000 人。这在很大程度上适用于数据存放在大量服务器的情况下(在 SSO 令牌用于 70 台 Apache HTTPD 服务器的情况下)。我们最近着手升级 Redis 服务器,此升级旨在使用 Redis 3.2 提供的原生集群功能。这篇博客希望解释为什么我们要使用集群、我们遇到的问题以及我们的解决方案。

在开始阶段(或至少在升级之前)
我们的传统缓存中每个缓存都包括一对 Redis 服务器,使用 keepalive 确保始终有一个主节点监听 浮动 IP 地址。当出现问题时,这些服务器对需要很大的精力来进行管理,而故障模式有时是非常各种各样的。有时,只允许读取它所持有的数据,而不允许写入的从属节点却会得到浮动 IP 地址,这种问题是相对容易诊断的,但会让无论哪个程序试图使用该缓存时都很麻烦。
新的应用程序
因此,这种情况下,我们需要构建一个新的应用程序,一个使用 共享内存缓存 的应用程序,但是我们不希望对该缓存进行迂回的故障切换过程。因此,我们的要求是共享的内存缓存,没有单点故障,可以使用尽可能少的人为干预来应对多种不同的故障模式,并且在事件恢复之后也能够在很少的人为干预下恢复,一个额外的要求是提高缓存的安全性,以减少数据泄露的范围(稍后再说)。当时 Redis Sentinel 看起来很有希望,并且有许多程序支持代理 Redis 连接,比如 twemproxy。这会导致还要安装其它很多组件,它应该有效,并且人际交互最少,但它复杂而需要运行大量的服务器和服务,并且相互通信。
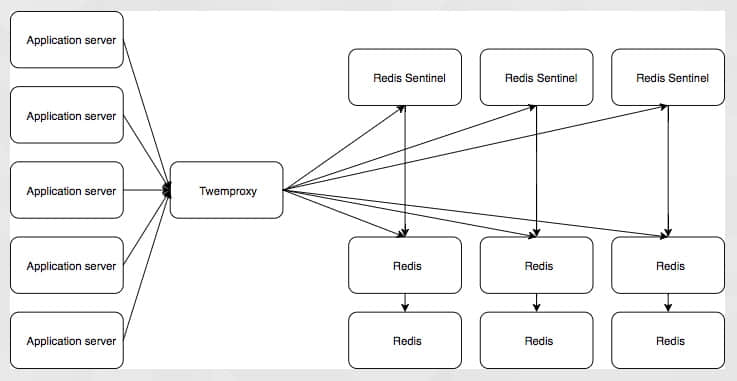
将会有大量的应用服务器与 twemproxy 进行通信,这会将它们的调用路由到合适的 Redis 主节点,twemproxy 将从 sentinal 集群获取主节点的信息,它将控制哪台 Redis 实例是主,哪台是从。这个设置是复杂的,而且仍有单点故障,它依赖于 twemproxy 来处理分片,来连接到正确的 Redis 实例。它具有对应用程序透明的优点,所以我们可以在理论上做到将现有的应用程序转移到这个 Redis 配置,而不用改变应用程序。但是我们要从头开始构建一个应用程序,所以迁移应用程序不是一个必需条件。
幸运的是,这个时候,Redis 3.2 出来了,而且内置了原生集群,消除了对单一 sentinel 集群需要。
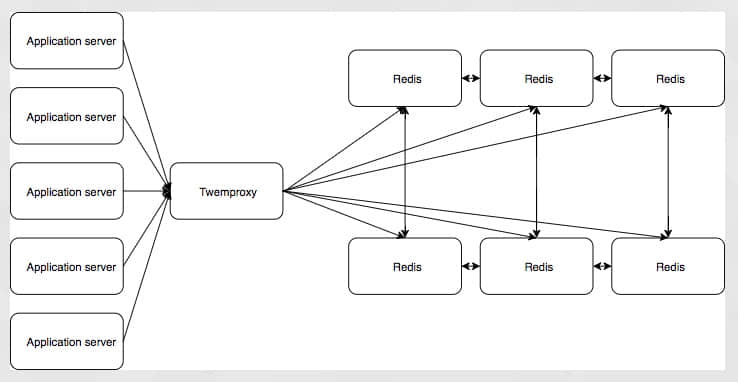
它有一个更简单的设置,但 twemproxy 不支持 Redis 集群分片,它能为你分片数据,但是如果尝试在与分片不一致的集群中这样做会导致问题。有参考的指南可以使其匹配,但是集群可以自动改变形式,并改变分片的设置方式。它仍然有单点故障。正是在这一点上,我将永远感谢我的一位同事发现了一个 Node.js 的 Redis 的集群发现驱动程序,让我们完全放弃了 twemproxy。
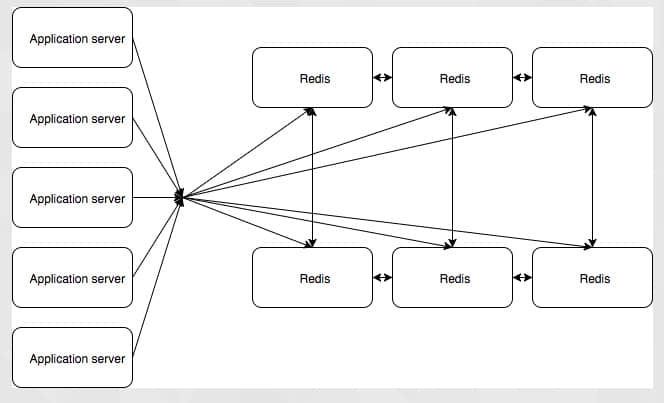
因此,我们能够自动分片数据,故障转移和故障恢复基本上是自动的。应用程序知道哪些节点存在,并且在写入数据时,如果写入错误的节点,集群将自动重定向该写入。这是被选的配置,这让我们共享的内存缓存相当健壮,可以没有干预地应付基本的故障模式。在测试期间,我们的确发现了一些缺陷。复制是在一个接一个节点的基础上进行的,因此如果我们丢失了一个主节点,那么它的从节点会成为一个单点故障,直到死去的节点恢复服务,也只有主节点对集群健康投票,所以如果我们一下失去太多主节点,那么集群无法自我恢复。但这比我们过去的好。
向前进
随着使用集群 Redis 配置的新程序,我们对于老式 Redis 实例的状态变得越来越不适应,但是新程序与现有程序的规模并不相同(超过 30GB 的内存专用于我们最大的老式 Redis 实例数据库)。因此,随着 Redis 集群在底层得到了证实,我们决定迁移老式的 Redis 实例到新的 Redis 集群中。
由于我们有一个原生支持 Redis 集群的 Node.js Redis 驱动程序,因此我们开始将 Node.js 程序迁移到 Redis 集群。但是,如何将数十亿字节的数据从一个地方移动到另一个地方,而不会造成重大问题?特别是考虑到这些数据是认证令牌,所以如果它们错了,我们的终端用户将会被登出。一个选择是要求网站完全下线,将所有内容都指向新的 Redis 群集,并将数据迁移到其中,以希望获得最佳效果。另一个选择是切换到新集群,并强制所有用户再次登录。由于显而易见的原因,这些都不是非常合适的。我们决定采取的替代方法是将数据同时写入老式 Redis 实例和正在替换它的集群,同时随着时间的推移,我们将逐渐更多地向该集群读取。由于数据的有效期有限(令牌在几个小时后到期),这种方法可以导致零停机,并且不会有数据丢失的风险。所以我们这么做了。迁移是成功的。
剩下的就是服务于我们的 PHP 代码(其中还有一个项目是有用的,其它的最终是没必要的)的 Redis 的实例了,我们在这过程中遇到了一个困难,实际上是两个。首先,也是最紧迫的是找到在 PHP 中使用的 Redis 集群发现驱动程序,还要是我们正在使用的 PHP 版本。这被证明是可行的,因为我们升级到了最新版本的 PHP。我们选择的驱动程序不喜欢使用 Redis 的授权方式,因此我们决定使用 Redis 集群作为一个额外的安全步骤 (我告诉你,这将有更多的安全性)。当我们用 Redis 集群替换每个老式 Redis 实例时,修复似乎很直接,将 Redis 授权关闭,这样它将会响应所有的请求。然而,这并不是真的,由于某些原因,Redis 集群不会接受来自 Web 服务器的连接。 Redis 在版本 3 中引入的称为“保护模式”的新安全功能将在 Redis 绑定到任何接口时将停止监听来自外部 IP 地址的连接,并无需配置 Redis 授权密码。这被证明相当容易修复,但让我们保持警惕。
现在?
这就是我们现在的情况。我们已经迁移了我们的一些老式 Redis 实例,并且正在迁移其余的。我们通过这样做解决了我们的一些技术债务,并提高了我们的平台的稳定性。使用 Redis 集群,我们还可以扩展内存数据库并扩展它们。 Redis 是单线程的,所以只要在单个实例中留出更多的内存就会可以得到这么多的增长,而且我们已经紧跟在这个限制后面。我们期待着从新的集群中获得改进的性能,同时也为我们提供了扩展和负载均衡的更多选择。
未来怎么样?
我们解决了一些技术性债务,这使我们的服务更容易支持,更加稳定。但这并不意味着这项工作完成了,Redis 4 似乎有一些我们可能想要研究的功能。而且 Redis 并不是我们使用的唯一软件。我们将继续努力改进平台,缩短处理技术债务的时间,但随着客户群体的扩大,我们力求提供更丰富的服务,我们总是会遇到需要改进的事情。下一个挑战可能与每分钟超过 20,000次 登录到超过 40,000 次甚至更高的扩展有关。
via: http://engineering.skybettingandgaming.com/2017/09/25/redis-2-to-redis-3/
作者:Craig Stewart 译者:geekpi 校对:wxy