Headless Chrome 入门

摘要
在 Chrome 59 中开始搭载 Headless Chrome。这是一种在 无需显示 的环境下运行 Chrome 浏览器的方式。从本质上来说,就是不用 chrome 浏览器来运行 Chrome 的功能!它将 Chromium 和 Blink 渲染引擎提供的所有现代 Web 平台的功能都带入了命令行。
它有什么用?
无需显示 的浏览器对于自动化测试和不需要可视化 UI 界面的服务器环境是一个很好的工具。例如,你可能需要对真实的网页运行一些测试,创建一个 PDF,或者只是检查浏览器如何呈现 URL。
注意: Mac 和 Linux 上的 Chrome 59 都可以运行无需显示模式。对 Windows 的支持将在 Chrome 60 中提供。要检查你使用的 Chrome 版本,请在浏览器中打开 chrome://version。开启 无需显示 模式(命令行界面)
开启 无需显示 模式最简单的方法是从命令行打开 Chrome 二进制文件。如果你已经安装了 Chrome 59 以上的版本,请使用 --headless 标志启动 Chrome:
chrome \
--headless \ # Runs Chrome in headless mode.
--disable-gpu \ # Temporarily needed for now.
--remote-debugging-port=9222 \
https://www.chromestatus.com # URL to open. Defaults to about:blank.
注意:目前你仍然需要使用 --disable-gpu 标志。但它最终会不需要的。chrome 二进制文件应该指向你安装 Chrome 的位置。确切的位置会因平台差异而不同。当前我在 Mac 上操作,所以我为安装的每个版本的 Chrome 都创建了方便使用的别名。
如果您使用 Chrome 的稳定版,并且无法获得测试版,我建议您使用 chrome-canary 版本:
alias chrome="/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome"
alias chrome-canary="/Applications/Google\ Chrome\ Canary.app/Contents/MacOS/Google\ Chrome\ Canary"
alias chromium="/Applications/Chromium.app/Contents/MacOS/Chromium"
在这里下载 Chrome Cannary。
命令行的功能
在某些情况下,你可能不需要以脚本编程的方式操作 Headless Chrome。可以使用一些有用的命令行标志来执行常见的任务。
打印 DOM
--dump-dom 标志将打印 document.body.innerHTML 到标准输出:
chrome --headless --disable-gpu --dump-dom https://www.chromestatus.com/
创建一个 PDF
--print-to-pdf 标志将页面转出为 PDF 文件:
chrome --headless --disable-gpu --print-to-pdf https://www.chromestatus.com/
截图
要捕获页面的屏幕截图,请使用 --screenshot 标志:
chrome --headless --disable-gpu --screenshot https://www.chromestatus.com/
# Size of a standard letterhead.
chrome --headless --disable-gpu --screenshot --window-size=1280,1696 https://www.chromestatus.com/
# Nexus 5x
chrome --headless --disable-gpu --screenshot --window-size=412,732 https://www.chromestatus.com/
使用 --screenshot 标志运行 Headless Chrome 将在当前工作目录中生成一个名为 screenshot.png 的文件。如果你正在寻求整个页面的截图,那么会涉及到很多事情。来自 David Schnurr 的一篇很棒的博文已经介绍了这一内容。请查看 使用 headless Chrome 作为自动截屏工具。
REPL 模式 (read-eval-print loop)
--repl 标志可以使 Headless Chrome 运行在一个你可以使用浏览器评估 JS 表达式的模式下。执行下面的命令:
$ chrome --headless --disable-gpu --repl https://www.chromestatus.com/
[0608/112805.245285:INFO:headless_shell.cc(278)] Type a Javascript expression to evaluate or "quit" to exit.
>>> location.href
{"result":{"type":"string","value":"https://www.chromestatus.com/features"}}
>>> quit
在没有浏览器界面的情况下调试 Chrome
当你使用 --remote-debugging-port=9222 运行 Chrome 时,它会启动一个支持 DevTools 协议的实例。该协议用于与 Chrome 进行通信,并且驱动 Headless Chrome 浏览器实例。它也是一个类似 Sublime、VS Code 和 Node 的工具,可用于应用程序的远程调试。#协同效应
由于你没有浏览器用户界面可用来查看网页,请在另一个浏览器中输入 http://localhost:9222,以检查一切是否正常。你将会看到一个 可检查的 页面的列表,可以点击它们来查看 Headless Chrome 正在呈现的内容:
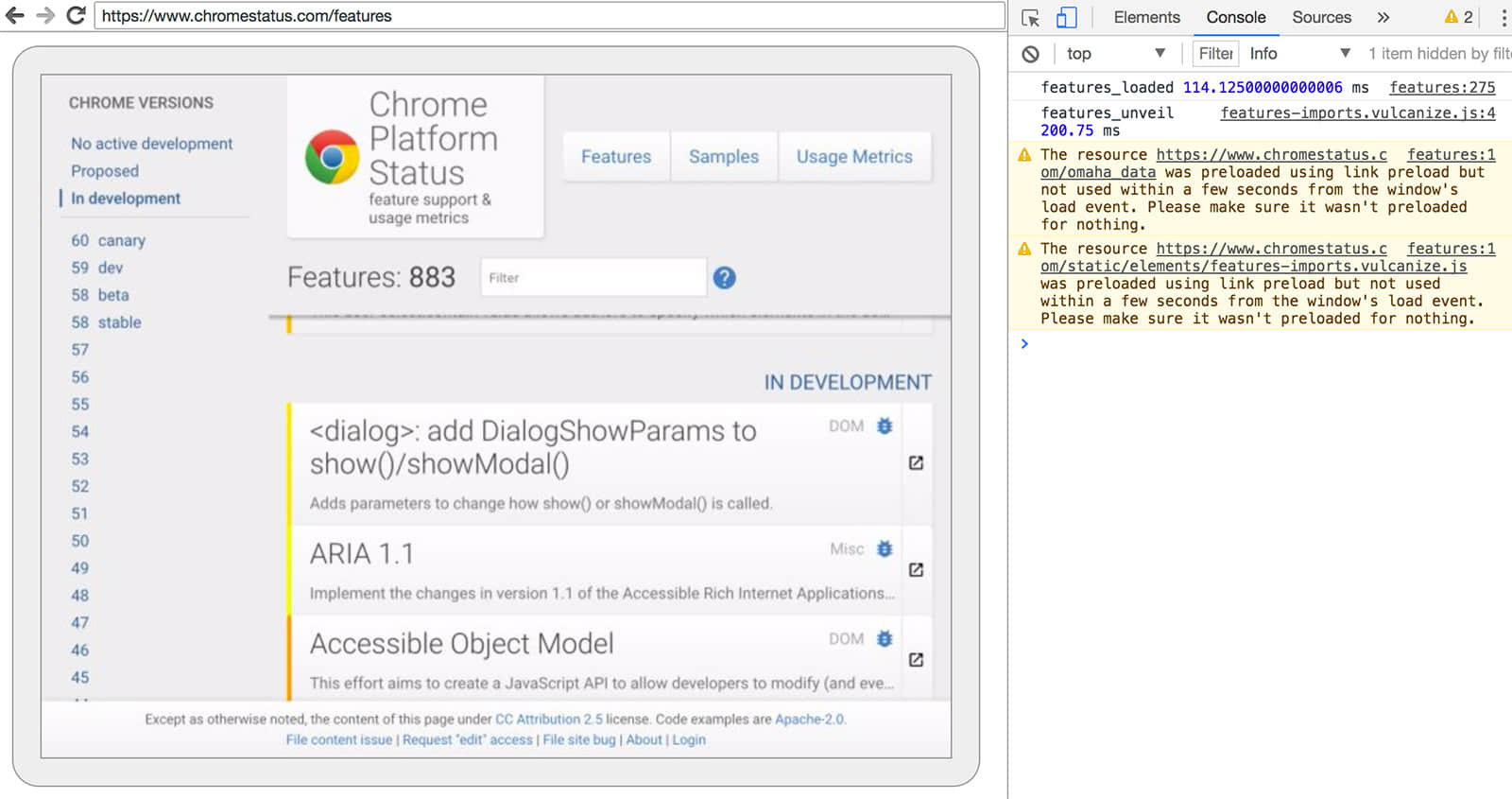
DevTools 远程调试界面
从这里,你就可以像往常一样使用熟悉的 DevTools 来检查、调试和调整页面了。如果你以编程方式使用 Headless Chrome,这个页面也是一个功能强大的调试工具,用于查看所有通过网络与浏览器交互的原始 DevTools 协议命令。
使用编程模式 (Node)
Puppeteer 库 API
Puppeteer 是一个由 Chrome 团队开发的 Node 库。它提供了一个高层次的 API 来控制无需显示版(或 完全版)的 Chrome。它与其他自动化测试库,如 Phantom 和 NightmareJS 相类似,但是只适用于最新版本的 Chrome。
除此之外,Puppeteer 还可用于轻松截取屏幕截图,创建 PDF,页面间导航以及获取有关这些页面的信息。如果你想快速地自动化进行浏览器测试,我建议使用该库。它隐藏了 DevTools 协议的复杂性,并可以处理诸如启动 Chrome 调试实例等繁冗的任务。
安装:
yarn add puppeteer
例子 - 打印用户代理:
const puppeteer = require('puppeteer');
(async() => {
const browser = await puppeteer.launch();
console.log(await browser.version());
browser.close();
})();
例子 - 获取页面的屏幕截图:
const puppeteer = require('puppeteer');
(async() => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.chromestatus.com', {waitUntil: 'networkidle'});
await page.pdf({path: 'page.pdf', format: 'A4'});
browser.close();
})();
查看 Puppeteer 的文档,了解完整 API 的更多信息。
CRI 库
chrome-remote-interface 是一个比 Puppeteer API 更低层次的库。如果你想要更接近原始信息和更直接地使用 DevTools 协议的话,我推荐使用它。
启动 Chrome
chrome-remote-interface 不会为你启动 Chrome,所以你要自己启动它。
在前面的 CLI 章节中,我们使用 --headless --remote-debugging-port=9222 手动启动了 Chrome。但是,要想做到完全自动化测试,你可能希望从你的应用程序中启动 Chrome。
其中一种方法是使用 child_process:
const execFile = require('child_process').execFile;
function launchHeadlessChrome(url, callback) {
// Assuming MacOSx.
const CHROME = '/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome';
execFile(CHROME, ['--headless', '--disable-gpu', '--remote-debugging-port=9222', url], callback);
}
launchHeadlessChrome('https://www.chromestatus.com', (err, stdout, stderr) => {
...
});
但是如果你想要在多个平台上运行可移植的解决方案,事情会变得很棘手。请注意 Chrome 的硬编码路径:
使用 ChromeLauncher
Lighthouse 是一个令人称奇的网络应用的质量测试工具。Lighthouse 内部开发了一个强大的用于启动 Chrome 的模块,现在已经被提取出来单独使用。chrome-launcher NPM 模块 可以找到 Chrome 的安装位置,设置调试实例,启动浏览器和在程序运行完之后将其杀死。它最好的一点是可以跨平台工作,感谢 Node!
默认情况下,chrome-launcher 会尝试启动 Chrome Canary(如果已经安装),但是你也可以更改它,手动选择使用的 Chrome 版本。要想使用它,首先从 npm 安装:
yarn add chrome-launcher
例子 - 使用 chrome-launcher 启动 Headless Chrome:
const chromeLauncher = require('chrome-launcher');
// Optional: set logging level of launcher to see its output.
// Install it using: yarn add lighthouse-logger
// const log = require('lighthouse-logger');
// log.setLevel('info');
/**
* Launches a debugging instance of Chrome.
* @param {boolean=} headless True (default) launches Chrome in headless mode.
* False launches a full version of Chrome.
* @return {Promise<ChromeLauncher>}
*/
function launchChrome(headless=true) {
return chromeLauncher.launch({
// port: 9222, // Uncomment to force a specific port of your choice.
chromeFlags: [
'--window-size=412,732',
'--disable-gpu',
headless ? '--headless' : ''
]
});
}
launchChrome().then(chrome => {
console.log(`Chrome debuggable on port: ${chrome.port}`);
...
// chrome.kill();
});
运行这个脚本没有做太多的事情,但你应该能在任务管理器中看到启动了一个 Chrome 的实例,它加载了页面 about:blank。记住,它不会有任何的浏览器界面,我们是无需显示的。
为了控制浏览器,我们需要 DevTools 协议!
检索有关页面的信息
警告: DevTools 协议可以做一些有趣的事情,但是起初可能有点令人生畏。我建议先花点时间浏览 DevTools 协议查看器。然后,转到 chrome-remote-interface 的 API 文档,看看它是如何包装原始协议的。我们来安装该库:
yarn add chrome-remote-interface
例子 - 打印用户代理:
const CDP = require('chrome-remote-interface');
...
launchChrome().then(async chrome => {
const version = await CDP.Version({port: chrome.port});
console.log(version['User-Agent']);
});
结果是类似这样的东西:HeadlessChrome/60.0.3082.0。
例子 - 检查网站是否有 Web 应用程序清单:
const CDP = require('chrome-remote-interface');
...
(async function() {
const chrome = await launchChrome();
const protocol = await CDP({port: chrome.port});
// Extract the DevTools protocol domains we need and enable them.
// See API docs: https://chromedevtools.github.io/devtools-protocol/
const {Page} = protocol;
await Page.enable();
Page.navigate({url: 'https://www.chromestatus.com/'});
// Wait for window.onload before doing stuff.
Page.loadEventFired(async () => {
const manifest = await Page.getAppManifest();
if (manifest.url) {
console.log('Manifest: ' + manifest.url);
console.log(manifest.data);
} else {
console.log('Site has no app manifest');
}
protocol.close();
chrome.kill(); // Kill Chrome.
});
})();
例子 - 使用 DOM API 提取页面的 <title>:
const CDP = require('chrome-remote-interface');
...
(async function() {
const chrome = await launchChrome();
const protocol = await CDP({port: chrome.port});
// Extract the DevTools protocol domains we need and enable them.
// See API docs: https://chromedevtools.github.io/devtools-protocol/
const {Page, Runtime} = protocol;
await Promise.all([Page.enable(), Runtime.enable()]);
Page.navigate({url: 'https://www.chromestatus.com/'});
// Wait for window.onload before doing stuff.
Page.loadEventFired(async () => {
const js = "document.querySelector('title').textContent";
// Evaluate the JS expression in the page.
const result = await Runtime.evaluate({expression: js});
console.log('Title of page: ' + result.result.value);
protocol.close();
chrome.kill(); // Kill Chrome.
});
})();
使用 Selenium、WebDriver 和 ChromeDriver
现在,Selenium 开启了 Chrome 的完整实例。换句话说,这是一个自动化的解决方案,但不是完全无需显示的。但是,Selenium 只需要进行小小的配置即可运行 Headless Chrome。如果你想要关于如何自己设置的完整说明,我建议你阅读“使用 Headless Chrome 来运行 Selenium”,不过你可以从下面的一些示例开始。
使用 ChromeDriver
ChromeDriver 2.3.0 支持 Chrome 59 及更新版本,可与 Headless Chrome 配合使用。在某些情况下,你可能需要等到 Chrome 60 以解决 bug。例如,Chrome 59 中屏幕截图已知存在问题。
安装:
yarn add selenium-webdriver chromedriver
例子:
const fs = require('fs');
const webdriver = require('selenium-webdriver');
const chromedriver = require('chromedriver');
// This should be the path to your Canary installation.
// I'm assuming Mac for the example.
const PATH_TO_CANARY = '/Applications/Google Chrome Canary.app/Contents/MacOS/Google Chrome Canary';
const chromeCapabilities = webdriver.Capabilities.chrome();
chromeCapabilities.set('chromeOptions', {
binary: PATH_TO_CANARY // Screenshots require Chrome 60\. Force Canary.
'args': [
'--headless',
]
});
const driver = new webdriver.Builder()
.forBrowser('chrome')
.withCapabilities(chromeCapabilities)
.build();
// Navigate to google.com, enter a search.
driver.get('https://www.google.com/');
driver.findElement({name: 'q'}).sendKeys('webdriver');
driver.findElement({name: 'btnG'}).click();
driver.wait(webdriver.until.titleIs('webdriver - Google Search'), 1000);
// Take screenshot of results page. Save to disk.
driver.takeScreenshot().then(base64png => {
fs.writeFileSync('screenshot.png', new Buffer(base64png, 'base64'));
});
driver.quit();
使用 WebDriverIO
WebDriverIO 是一个在 Selenium WebDrive 上构建的更高层次的 API。
安装:
yarn add webdriverio chromedriver
例子:过滤 chromestatus.com 上的 CSS 功能:
const webdriverio = require('webdriverio');
const chromedriver = require('chromedriver');
// This should be the path to your Canary installation.
// I'm assuming Mac for the example.
const PATH_TO_CANARY = '/Applications/Google Chrome Canary.app/Contents/MacOS/Google Chrome Canary';
const PORT = 9515;
chromedriver.start([
'--url-base=wd/hub',
`--port=${PORT}`,
'--verbose'
]);
(async () => {
const opts = {
port: PORT,
desiredCapabilities: {
browserName: 'chrome',
chromeOptions: {
binary: PATH_TO_CANARY // Screenshots require Chrome 60\. Force Canary.
args: ['--headless']
}
}
};
const browser = webdriverio.remote(opts).init();
await browser.url('https://www.chromestatus.com/features');
const title = await browser.getTitle();
console.log(`Title: ${title}`);
await browser.waitForText('.num-features', 3000);
let numFeatures = await browser.getText('.num-features');
console.log(`Chrome has ${numFeatures} total features`);
await browser.setValue('input[type="search"]', 'CSS');
console.log('Filtering features...');
await browser.pause(1000);
numFeatures = await browser.getText('.num-features');
console.log(`Chrome has ${numFeatures} CSS features`);
const buffer = await browser.saveScreenshot('screenshot.png');
console.log('Saved screenshot...');
chromedriver.stop();
browser.end();
})();
更多资源
以下是一些可以带你入门的有用资源:
文档
- DevTools Protocol Viewer - API 参考文档
工具
- chrome-remote-interface - 基于 DevTools 协议的 node 模块
- Lighthouse - 测试 Web 应用程序质量的自动化工具;大量使用了协议
- chrome-launcher - 用于启动 Chrome 的 node 模块,可以自动化
样例
- "The Headless Web" - Paul Kinlan 发布的使用了 Headless 和 api.ai 的精彩博客
常见问题
我需要 --disable-gpu 标志吗?
目前是需要的。--disable-gpu 标志在处理一些 bug 时是需要的。在未来版本的 Chrome 中就不需要了。查看 https://crbug.com/546953#c152 和 https://crbug.com/695212 获取更多信息。
所以我仍然需要 Xvfb 吗?
不。Headless Chrome 不使用窗口,所以不需要像 Xvfb 这样的显示服务器。没有它你也可以愉快地运行你的自动化测试。
什么是 Xvfb?Xvfb 是一个用于类 Unix 系统的运行于内存之内的显示服务器,可以让你运行图形应用程序(如 Chrome),而无需附加的物理显示器。许多人使用 Xvfb 运行早期版本的 Chrome 进行 “headless” 测试。
如何创建一个运行 Headless Chrome 的 Docker 容器?
查看 lighthouse-ci。它有一个使用 Ubuntu 作为基础镜像的 Dockerfile 示例,并且在 App Engine Flexible 容器中安装和运行了 Lighthouse。
我可以把它和 Selenium / WebDriver / ChromeDriver 一起使用吗?
是的。查看 Using Selenium, WebDrive, or ChromeDriver。
它和 PhantomJS 有什么关系?
Headless Chrome 和 PhantomJS 是类似的工具。它们都可以用来在无需显示的环境中进行自动化测试。两者的主要不同在于 Phantom 使用了一个较老版本的 WebKit 作为它的渲染引擎,而 Headless Chrome 使用了最新版本的 Blink。
目前,Phantom 提供了比 DevTools protocol 更高层次的 API。
我在哪儿提交 bug?
对于 Headless Chrome 的 bug,请提交到 crbug.com。
对于 DevTools 协议的 bug,请提交到 github.com/ChromeDevTools/devtools-protocol。
作者简介
Eric Bidelman 谷歌工程师,Lighthouse 开发,Web 和 Web 组件开发,Chrome 开发
via: https://developers.google.com/web/updates/2017/04/headless-chrome
作者:Eric Bidelman 译者:firmianay 校对:wxy