今天我在 libcurl 内部又做了一个小改动,使其做更少的 malloc。这一次,泛型链表函数被转换成更少的 malloc (这才是链表函数应有的方式,真的)。
研究 malloc
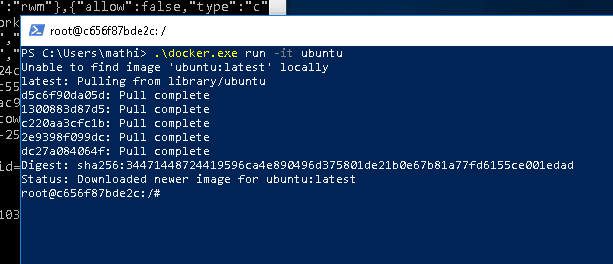
几周前我开始研究内存分配。这很容易,因为多年前我们 curl 中就已经有内存调试和日志记录系统了。使用 curl 的调试版本,并在我的构建目录中运行此脚本:
#!/bin/sh
export CURL_MEMDEBUG=$HOME/tmp/curlmem.log
./src/curl http://localhost
./tests/memanalyze.pl -v $HOME/tmp/curlmem.log
对于 curl 7.53.1,这大约有 115 次内存分配。这算多还是少?
内存日志非常基础。为了让你有所了解,这是一个示例片段:
MEM getinfo.c:70 free((nil))
MEM getinfo.c:73 free((nil))
MEM url.c:294 free((nil))
MEM url.c:297 strdup(0x559e7150d616) (24) = 0x559e73760f98
MEM url.c:294 free((nil))
MEM url.c:297 strdup(0x559e7150d62e) (22) = 0x559e73760fc8
MEM multi.c:302 calloc(1,480) = 0x559e73760ff8
MEM hash.c:75 malloc(224) = 0x559e737611f8
MEM hash.c:75 malloc(29152) = 0x559e737a2bc8
MEM hash.c:75 malloc(3104) = 0x559e737a9dc8
检查日志
然后,我对日志进行了更深入的研究,我意识到在相同的代码行做了许多小内存分配。我们显然有一些相当愚蠢的代码模式,我们分配一个结构体,然后将该结构添加到链表或哈希,然后该代码随后再添加另一个小结构体,如此这般,而且经常在循环中执行。(我在这里说的是我们,不是为了责怪某个人,当然大部分的责任是我自己……)
这两种分配操作将总是成对地出现,并被同时释放。我决定解决这些问题。做非常小的(小于 32 字节)的分配也是浪费的,因为非常多的数据将被用于(在 malloc 系统内)跟踪那个微小的内存区域。更不用说堆碎片了。
因此,将该哈希和链表代码修复为不使用 malloc 是快速且简单的方法,对于最简单的 “curl http://localhost” 传输,它可以消除 20% 以上的 malloc。
此时,我根据大小对所有的内存分配操作进行排序,并检查所有最小的分配操作。一个突出的部分是在 curl_multi_wait() 中,它是一个典型的在 curl 传输主循环中被反复调用的函数。对于大多数典型情况,我将其转换为使用堆栈。在大量重复的调用函数中避免 malloc 是一件好事。
重新计数
现在,如上面的脚本所示,同样的 curl localhost 命令从 curl 7.53.1 的 115 次分配操作下降到 80 个分配操作,而没有牺牲任何东西。轻松地有 26% 的改善。一点也不差!
由于我修改了 curl_multi_wait(),我也想看看它实际上是如何改进一些稍微更高级一些的传输。我使用了 multi-double.c 示例代码,添加了初始化内存记录的调用,让它使用 curl_multi_wait(),并且并行下载了这两个 URL:
http://www.example.com/
http://localhost/512M
第二个文件是 512 兆字节的零,第一个文件是一个 600 字节的公共 html 页面。这是 count-malloc.c 代码。
首先,我使用 7.53.1 来测试上面的例子,并使用 memanalyze 脚本检查:
Mallocs: 33901
Reallocs: 5
Callocs: 24
Strdups: 31
Wcsdups: 0
Frees: 33956
Allocations: 33961
Maximum allocated: 160385
好了,所以它总共使用了 160KB 的内存,分配操作次数超过 33900 次。而它下载超过 512 兆字节的数据,所以它每 15KB 数据有一次 malloc。是好是坏?
回到 git master,现在是 7.54.1-DEV 的版本 - 因为我们不太确定当我们发布下一个版本时会变成哪个版本号。它可能是 7.54.1 或 7.55.0,它还尚未确定。我离题了,我再次运行相同修改的 multi-double.c 示例,再次对内存日志运行 memanalyze,报告来了:
Mallocs: 69
Reallocs: 5
Callocs: 24
Strdups: 31
Wcsdups: 0
Frees: 124
Allocations: 129
Maximum allocated: 153247
我不敢置信地反复看了两遍。发生什么了吗?为了仔细检查,我最好再运行一次。无论我运行多少次,结果还是一样的。
33961 vs 129
在典型的传输中 curl_multi_wait() 被调用了很多次,并且在传输过程中至少要正常进行一次内存分配操作,因此删除那个单一的微小分配操作对计数器有非常大的影响。正常的传输也会做一些将数据移入或移出链表和散列操作,但是它们现在也大都是无 malloc 的。简单地说:剩余的分配操作不会在传输循环中执行,所以它们的重要性不大。
以前的 curl 是当前示例分配操作数量的 263 倍。换句话说:新的是旧的分配操作数量的 0.37% 。
另外还有一点好处,新的内存分配量更少,总共减少了 7KB(4.3%)。
malloc 重要吗?
在几个 G 内存的时代里,在传输中有几个 malloc 真的对于普通人有显著的区别吗?对 512MB 数据进行的 33832 个额外的 malloc 有什么影响?
为了衡量这些变化的影响,我决定比较 localhost 的 HTTP 传输,看看是否可以看到任何速度差异。localhost 对于这个测试是很好的,因为没有网络速度限制,更快的 curl 下载也越快。服务器端也会相同的快/慢,因为我将使用相同的测试集进行这两个测试。
我相同方式构建了 curl 7.53.1 和 curl 7.54.1-DEV,并运行这个命令:
curl http://localhost/80GB -o /dev/null
下载的 80GB 的数据会尽可能快地写到空设备中。
我获得的确切数字可能不是很有用,因为它将取决于机器中的 CPU、使用的 HTTP 服务器、构建 curl 时的优化级别等,但是相对数字仍然应该是高度相关的。新代码对决旧代码!
7.54.1-DEV 反复地表现出更快 30%!我的早期版本是 2200MB/秒增加到当前版本的超过 2900 MB/秒。
这里的要点当然不是说它很容易在我的机器上使用单一内核以超过 20GB/秒的速度来进行 HTTP 传输,因为实际上很少有用户可以通过 curl 做到这样快速的传输。关键在于 curl 现在每个字节的传输使用更少的 CPU,这将使更多的 CPU 转移到系统的其余部分来执行任何需要做的事情。或者如果设备是便携式设备,那么可以省电。
关于 malloc 的成本:512MB 测试中,我使用旧代码发生了 33832 次或更多的分配。旧代码以大约 2200MB/秒的速率进行 HTTP 传输。这等于每秒 145827 次 malloc - 现在它们被消除了!600 MB/秒的改进意味着每秒钟 curl 中每个减少的 malloc 操作能额外换来多传输 4300 字节。
去掉这些 malloc 难吗?
一点也不难,非常简单。然而,有趣的是,在这个旧项目中,仍然有这样的改进空间。我有这个想法已经好几年了,我很高兴我终于花点时间来实现。感谢我们的测试套件,我可以有相当大的信心做这个“激烈的”内部变化,而不会引入太可怕的回归问题。由于我们的 API 很好地隐藏了内部,所以这种变化可以完全不改变任何旧的或新的应用程序……
(是的,我还没在版本中发布该变更,所以这还有风险,我有点后悔我的“这很容易”的声明……)
注意数字
curl 的 git 仓库从 7.53.1 到今天已经有 213 个提交。即使我没有别的想法,可能还会有一次或多次的提交,而不仅仅是内存分配对性能的影响。
还有吗?
还有其他类似的情况么?
也许。我们不会做很多性能测量或比较,所以谁知道呢,我们也许会做更多的愚蠢事情,我们可以收手并做得更好。有一个事情是我一直想做,但是从来没有做,就是添加所使用的内存/malloc 和 curl 执行速度的每日“监视” ,以便更好地跟踪我们在这些方面不知不觉的回归问题。
补遗,4/23
(关于我在 hacker news、Reddit 和其它地方读到的关于这篇文章的评论)
有些人让我再次运行那个 80GB 的下载,给出时间。我运行了三次新代码和旧代码,其运行“中值”如下:
旧代码:
real 0m36.705s
user 0m20.176s
sys 0m16.072s
新代码:
real 0m29.032s
user 0m12.196s
sys 0m12.820s
承载这个 80GB 文件的服务器是标准的 Apache 2.4.25,文件存储在 SSD 上,我的机器的 CPU 是 i7 3770K 3.50GHz 。
有些人也提到 alloca() 作为该补丁之一也是个解决方案,但是 alloca() 移植性不够,只能作为一个孤立的解决方案,这意味着如果我们要使用它的话,需要写一堆丑陋的 #ifdef。
via: https://daniel.haxx.se/blog/2017/04/22/fewer-mallocs-in-curl/
作者:DANIEL STENBERG 译者:geekpi 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出