极客漫画:现代的邪恶——不许 Ctrl-C

在页面上,Control-C 的作用是复制,当一个页面禁用了 Control-C 时……这得是多邪恶?!
via: https://turnoff.us/geek/modern-evil/
作者:Daniel Stori 译者&点评:Bestony 校对&合成:wxy
在页面上,Control-C 的作用是复制,当一个页面禁用了 Control-C 时……这得是多邪恶?!
via: https://turnoff.us/geek/modern-evil/
作者:Daniel Stori 译者&点评:Bestony 校对&合成:wxy
你想成为开源项目中得意满满、功成名就的那个人吗,那就要遵守下面的“潜规则”。

正如体育界不成文的规定一样,这些规则基本上不会出现在官方文档和正式记录上。比如说,在棒球运动中,从比分领先时不要盗垒,到跑垒员跑了第一时也不要放弃四坏球保送。对于圈外人来讲,这些东西很难懂,甚至觉得没什么意义。但是对于那些想成为 MVP 的队员来说,这些都是理所当然的。
软件开发,特别是开源软件开发中,也有一套不成文的规定。和其它的团队运动一样,这些规定很大程度上决定了开源社区如何看待一名开发者,特别是新加入社区的开发者。
在参与社区之前,比如开放源代码或者其它什么的,你需要做一些基本工作。对于有眼界的开源贡献者,这意味这你需要理解社区的目标,并学习应该从哪里起步。人人都想贡献源代码,但是只有少量的人做过准备,并且乐意、同时也有能力完成这项艰苦卓绝的工作:测试补丁、复审代码、撰写文档、修正错误。所有的这些不受待见的任务在一个健康的社区中都是必要的。
为什么要在优雅地写代码前做这些呢?这是一种信任,更重要的是,不要只关注自己开发的功能,而是要关注整个社区的动向。
当你在某个社区中建立起自己的声望,那么很有必要全面了解该项目和代码。不要停留于任务状态上,而是要去钻研项目本身,理解那些超出你擅长范围之外的知识。不要只把自己的理解局限于开发者,这样会让你着眼于让你的代码有更大的影响,而不只是你那一亩三分地。
打个比方,你已经完成了一个网络模块的测试版本。你测试了一下,觉得不错。然后你把它开放到社区,想要更多的人测试。结果发现,当它以特定的方式部署时,有可能会破坏安全设置,还可能导致主存储泄露。如果你将代码视为一个整体时问题就可以迎刃而解,而不是孤立地看待问题。这表明,你要对项目各个部分如何与其他人协作交互有比较深入的理解。让你的补丁填坑而不是挖坑。这样你朝成为社区精英的目标上又前进了一大步。
代码提交完毕后你的工作还没结束。如果代码被接受,还会有一些关于这些更改的讨论和常见的问答,还要做测试。你要确保你可以准时提交,努力去理解如何在不影响社区其他成员的情况下,改进代码和补丁。
开源社区不是自相残杀的丛林世界,我们更看重项目的价值而非个体的贡献和成功。如果你想给自己加分,让自己成为更重要的社区成员、让社区接纳你的代码,那就努力帮助别人。如果你熟悉网络部分,那就去复审网络部分,用你的专业技能让整个代码更加优雅。道理很简单,顶级的审查者经常和顶级的贡献者打交道。你帮助的人越多,你就越有价值。
作为一个开发者,你很可能希望为开源项目解决一个特定的痛点。或许你想要运行在一个目前还不支持的系统上,抑或你很希望改革社区目前使用的安全技术。想要引进新技术,特别是比较有争议的技术,最好的办法就是让人无法拒绝它。你需要透彻地了解底层代码,考虑每个极端情况。在不影响已实现功能的前提下增加新功能。不仅仅是完成就行,还要在特性的完善上下功夫。
开源社区也有许多玩玩就算的人,但是承诺了就不要轻易失信。不要就因为提交被拒就离开社区。找出原因,修正错误,然后再试一试。当你开发时候,要和整个代码库保持一致,确保即使项目发生变化而你的补丁仍然可用。不要把你的代码留给别人修复,要自己修复。这样可以在社区形成良好的风气,每个人都自己改。
这些“潜规则”看上去很简单,但是还是有许多开源项目的贡献者并没有遵守。这样做的开发者不仅可以为成功地推动他们自己的项目,而且也有助于开源社区。
作者简介:
Matt Hicks 是 Red Hat 软件工程的副主席,也是 Red Hat 开源合作团队的奠基成员之一。他历时十五年,在软件工程中担任多种职务:开发,运行,架构,管理。
作者:Matt Hicks 译者:Taylor1024 校对:wxy,martin2011qi

现有的技术无法对微芯片进行有效的冷却,这正快速成为摩尔定律消亡的第一原因。
随着对数字计算速度的需求,科学家和工程师正努力地将更多的晶体管和支撑电路放在已经很拥挤的硅片上。的确,它非常地复杂,然而,和复杂性相比,热量聚积引起的问题更严重。
洛克希德马丁公司首席研究员 John Ditri 在新闻稿中说到:当前,我们可以放入微芯片的功能是有限的,最主要的原因之一是发热的管理。如果你能管理好发热,你可以用较少的芯片,也就是说较少的材料,那样就可以节约成本,并能减少系统的大小和重量。如果你能管理好发热,用相同数量的芯片将能获得更好的系统性能。
硅对电子流动的阻力产生了热量,在如此小的空间封装如此多的晶体管累积了足以毁坏元器件的热量。一种消除热累积的方法是在芯片层用光子学技术减少电子的流动,然而光子学技术有它的一系列问题。
为了寻找其他解决办法,美国国防高级研究计划局 DARPA 发起了一个关于 ICECool 应用 (片内/片间增强冷却技术)的项目。 GSA 的网站 FedBizOpps.gov 报道:ICECool 正在探索革命性的热技术,其将减轻热耗对军用电子系统的限制,同时能显著减小军用电子系统的尺寸,重量和功耗。
微流冷却方法的独特之处在于组合使用片内和(或)片间微流冷却技术和片上热互连技术。

MicroCooling 1 Image: DARPA
DARPA ICECool 应用发布的公告 指出,这种微型片内和(或)片间通道可采用轴向微通道、径向通道和(或)横流通道,采用微孔和歧管结构及局部液体喷射形式来疏散和重新引导微流,从而以最有利的方式来满足指定的散热指标。
通过上面的技术,洛克希德马丁的工程师已经实验性地证明了片上冷却是如何得到显著改善的。洛克希德马丁新闻报道:ICECool 项目的第一阶段发现,当冷却具有多个局部 30kW/cm2 热点,发热为 1kw/cm2 的芯片时热阻减少了 4 倍,进而验证了洛克希德的嵌入式微流冷却方法的有效性。
第二阶段,洛克希德马丁的工程师聚焦于 RF 放大器。通过 ICECool 的技术,团队演示了 RF 的输出功率可以得到 6 倍的增长,而放大器仍然比其常规冷却的更凉。
出于对技术的信心,洛克希德马丁已经在设计和制造实用的微流冷却发射天线。 洛克希德马丁还与 Qorvo 合作,将其热解决方案与 Qorvo 的高性能 GaN 工艺 相集成。
研究论文 DARPA 的片间/片内增强冷却技术(ICECool)流程 的作者认为 ICECool 将使电子系统的热管理模式发生改变。ICECool 应用的执行者将根据应用来定制片内和片间的热管理方法,这个方法需要兼顾应用的材料,制造工艺和工作环境。
如果微流冷却能像科学家和工程师所说的成功的话,似乎摩尔定律会起死回生。
(题图:iStock/agsandrew)
via: http://www.techrepublic.com/article/microfluidic-cooling-may-prevent-the-demise-of-moores-law/
作者:Michael Kassner 译者:messon007 校对:wxy

TensorFlow 是用于机器学习任务的开源软件。它的创建者 Google 希望提供一个强大的工具以帮助开发者探索和建立基于机器学习的应用,所以他们在去年作为开源项目发布了它。TensorFlow 是一个非常强大的工具,专注于一种称为 深层神经网络 (DNN)的神经网络。
深层神经网络被用来执行复杂的机器学习任务,例如图像识别、手写识别、自然语言处理、聊天机器人等等。这些神经网络被训练学习其所要执行的任务。由于训练所需的计算是非常巨大的,在大多数情况下需要 GPU 支持,这时 TensorFlow 就派上用场了。启用了 GPU 并安装了支持 GPU 的软件,那么训练所需的时间就可以大大减少。
本教程可以帮助你安装只支持 CPU 的和同时支持 GPU 的 TensorFlow。要使用带有 GPU 支持的 TensorFLow,你必须要有一块支持 CUDA 的 Nvidia GPU。CUDA 和 CuDNN(Nvidia 的计算库)的安装有点棘手,本指南会提供在实际安装 TensorFlow 之前一步步安装它们的方法。
Nvidia CUDA 是一个 GPU 加速库,它已经为标准神经网络中用到的标准例程调优过。CuDNN 是一个用于 GPU 的调优库,它负责 GPU 性能的自动调整。TensorFlow 同时依赖这两者用于训练并运行深层神经网络,因此它们必须在 TensorFlow 之前安装。
需要指出的是,那些不希望安装支持 GPU 的 TensorFlow 的人,你可以跳过以下所有的步骤并直接跳到:“步骤 5:安装只支持 CPU 的 TensorFlow”。
关于 TensorFlow 的介绍可以在这里找到。
首先,在这里下载用于 Ubuntu 16.04 的 CUDA 库。此文件非常大(2GB),因此也许会花费一些时间下载。
下载的文件是 “.deb” 包。要安装它,运行下面的命令:
sudo dpkg -i cuda-repo-ubuntu1604-8-0-local_8.0.44-1_amd64.deb

下面的的命令会安装所有的依赖,并最后安装 cuda 工具包:
sudo apt install -f
sudo apt update
sudo apt install cuda
如果成功安装,你会看到一条消息说:“successfully installed”。如果已经安装了,接着你可以看到类似下面的输出:

CuDNN 下载需要花费一些功夫。Nvidia 没有直接提供下载文件(虽然它是免费的)。通过下面的步骤获取 CuDNN。
最后,在下拉中点击 “Download cuDNN v5.1 (Jan 20, 2017), for CUDA 8.0”,最后,你需要下载这两个文件:
注意:即使上面说的是用于 Ubuntu 14.04 的库。它也适用于 16.04。
现在你已经同时有 CuDNN 的两个文件了,是时候安装它们了!在包含这些文件的文件夹内运行下面的命令:
sudo dpkg -i libcudnn5_5.1.5-1+cuda8.0_amd64.deb
sudo dpkg -i libcudnn5-dev_5.1.5-1+cuda8.0_amd64.deb
下面的图片展示了这些命令的输出:

安装位置应该被添加到 bashrc 文件中,以便系统下一次知道如何找到这些用于 CUDA 的文件。使用下面的命令打开 bashrc 文件:
sudo gedit ~/.bashrc
文件打开后,添加下面两行到文件的末尾:
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64"
export CUDA_HOME=/usr/local/cuda
这步我们将安装带有 GPU 支持的 TensorFlow。如果你使用的是 Python 2.7,运行下面的命令:
pip install TensorFlow-gpu
如果安装了 Python 3.x,使用下面的命令:
pip3 install TensorFlow-gpu
安装完后,你会看到一条 “successfully installed” 的消息。现在,剩下要测试的是是否已经正确安装。打开终端并输入下面的命令测试:
python
import TensorFlow as tf
你应该会看到类似下面图片的输出。在图片中你可以观察到 CUDA 库已经成功打开了。如果有任何错误,消息会提示说无法打开 CUDA 甚至无法找到模块。为防你或许遗漏了上面的某步,仔细重做教程的每一步就行了。

注意:这步是对那些没有 GPU 或者没有 Nvidia GPU 的人而言的。其他人请忽略这步!!
安装只支持 CPU 的 TensorFlow 非常简单。使用下面两个命令:
pip install TensorFlow
如果你有 python 3.x,使用下面的命令:
pip3 install TensorFlow
是的,就是这么简单!
安装指南至此结束,你现在可以开始构建深度学习应用了。如果你刚刚起步,你可以在这里看下适合初学者的官方教程。如果你正在寻找更多的高级教程,你可以在这里学习了解如何设置可以高精度识别上千个物体的图片识别系统/工具。
(题图:Pixabay,CC0)
作者:Akshay Pai 译者:geekpi 校对:wxy

虽然插件毫无疑问是 Vim 最大的优势,然而,还有其它一些功能,使得它成为当今 Linux 用户中最强大、功能最丰富的文本编辑器/IDE 之一。其中一个功能就是可以根据文件做特定的设置。我们可以使用该编辑器的 模式行 特性来实现该功能。
在这篇文章中,我将讨论如何使用 Vim 的 模式行 特性来简单的理解一些例子。
在开始之前,值得提醒一下,这篇教程中提及的所有例子、命令和指令都已经在 Ubuntu 16.04 中使用 Vim 7.4 版本测试过。
正如上面已经提到的, Vim 的模式行特性让你能够进行特定于文件的更改。比如,假设你想把项目中的一个特定文件中的所有制表符用空格替换,并且确保这个更改不会影响到其它所有文件。这是模式行帮助你完成你想做的事情的一个理想情况。
因此,你可以考虑将下面这一行加入文件的开头或结尾来完成这件事。
# vim: set expandtab:
(LCTT 译注:模式行就是一行以注释符,如 #、//、/* 开头,间隔一个空格,以 vim: 关键字触发的设置命令。可参看:http://vim.wikia.com/wiki/Modeline_magic )
如果你是在 Linux 系统上尝试上面的练习来测试用例,很有可能它将不会像你所期望的那样工作。如果是这样,也不必担心,因为某些情况下,模式行特性需要先激活才能起作用(出于安全原因,在一些系统比如 Debian、Ubuntu、GGentoo 和 OSX 上默认情况下禁用)。
为了启用该特性,打开 .vimrc 文件(位于 home 目录),然后加入下面一行内容:
set modeline
现在,无论何时你在该文件输入一个制表符然后保存时(文件中已输入 expandtab 模式行命令的前提下),都会被自动转换为空格。
让我们考虑另一个用例。假设在 Vim 中, 制表符默认设置为 4 个空格,但对于某个特殊的文件,你想把它增加到 8 个。对于这种情况,你需要在文件的开头或末尾加上下面这行内容:
// vim: noai:ts=8:
现在,输入一个制表符,你会看到,空格的数量为 8 个。
你可能已经注意到我刚才说的,这些模式行命令需要加在靠近文件的顶部或底部。如果你好奇为什么是这样,那么理由是该特性以这种方式设计的。下面这一行(来自 Vim 官方文件)将会解释清楚:
“模式行不能随意放在文件中的任何位置:它需要放在文件中的前几行或最后几行。modelines变量控制 Vim 检查模式行在文件中的确切位置。请查看:help modelines。默认情况下,设置为 5 行。”
下面是 :help modelines 命令(上面提到的)输出的内容:
如果modeline已启用并且modelines给出了行数,那么便在相应位置查找set命令。如果modeline禁用或modelines设置的行数为 0 则不查找。
尝试把模式行命令置于超出 5 行的范围(距离文件底部和顶部的距离均超过 5 行),你会发现, 制表符将会恢复为 Vim 默认数目的空格 — 在我的情况里是 4 个空格。
然而,你可以按照自己的意愿改变默认行数,只需在你的 .vimrc 文件中加入下面一行命令
set modelines=[新值]
比如,我把值从 5 增加到了 10 。
set modelines=10
这意味着,现在我可以把模式行命令置于文件前 10 行或最后 10 行的任意位置。
继续,无论何时,当你在编辑一个文件的时候,你可以输入下面的命令(在 Vim 编辑器的命令模式下输入)来查看当前与命令行相关的设置以及它们最新的设置。
:verbose set modeline? modelines?
比如,在我的例子中,上面的命令产生了如下所示的输出:
modeline
Last set from ~/.vimrc
modelines=10
Last set from ~/.vimrc
关于 Vim 的模式行特性,你还需要知道一些重要的点:
nocompatible)模式运行时该特性是启用的,但需要注意的是,在一些发行版中,出于安全考虑,系统的 vimrc 文件禁用了该选项。sudo 方式打开该文件,那么该特性依旧能够正常工作)。set 来设置模式行,其结束于第一个冒号,而非反斜杠。不使用 set,则后面的文本都是选项。比如,/* vim: noai:ts=4:sw=4 */ 是一个无效的模式行。(LCTT 译注:关于模式行中的 set,上述描述指的是:如果用 set 来设置,那么当发现第一个 : 时,表明选项结束,后面的 */ 之类的为了闭合注释而出现的文本均无关;而如果不用 set 来设置,那么以 vim: 起头的该行所有内容均视作选项。 )
令人沮丧的是, Vim 的模式行特性可能会造成安全性问题。事实上,在过去,已经报道过多个和模式行相关的问题,包括 shell 命令注入,任意命令执行和无授权访问等。我知道,这些问题发生在很早的一些时候,现在应该已经修复好了,但是,这提醒了我们,模式行特性有可能会被黑客滥用。
模式行可能是 Vim 编辑器的一个高级命令,但是它并不难理解。毫无疑问,它的学习曲线会有一些复杂,但是不需多问也知道,该特性是多么的有用。当然,出于安全考虑,在启用并使用该选项前,你需要对自己的选择进行权衡。
你有使用过模式行特性吗?你的体验是什么样的?记得在下面的评论中分享给我们。
via: https://www.howtoforge.com/tutorial/vim-modeline-settings/
从 Software Collections、EPEL 和 Remi 获得可靠的 CentOS 新版软件。
在 Red Hat 企业 Linux(RHEL) 上,提供那些早已老掉牙的软件已经是企业级软件厂商的传统了。这倒不是因为他们懒,而确实是用户需要。很多公司像看待家具一样看待软件:我买一张桌子,能用一辈子,软件不应该也这样吗?
CentOS 作为 RHEL 的复制品有着同样的遭遇。虽然 Red Hat 还在为这些被厂商抛弃的过时软件提供支持、修补安全漏洞等,但如果你的应用依赖新版软件,你就得想办法了。 我在这个问题上不止一次碰壁。 LAMP 组合里任一个组件都需要其它所有组件能与其兼容,这有时就显得很麻烦。 比如说去年我就被 RHEL/CentOS 折腾得够呛。REHL/CentOS 第 6 版最高支持 PHP 5.3 ,第 7 版支持到 PHP 5.4 。而 PHP 5.3 早在 2014 年 8 月就到达 EOL(End Of Life) ,不再被厂商支持了, PHP 5.4 的 EOL 在 2015 年 9 月, 5.5 则是 2016 年 7 月。 有太多古老的软件版本,包括 MySQL、Python 等,它们应该像木乃伊一样被展示在博物馆里,但它们却活在你的系统上。
那么,可怜的管理员们该怎么办呢?如果你跑着 RHEL/CentOS ,那应该先试试 Software Collections,因为这是 Red Hat 唯一支持的新软件包源。 Software Collections 为 CentOS 设立了专门的仓库,安装和管理都和其它第三方仓库一样。但如果你用的是 RHEL 的,情况就有点不同了,具体请参考 RHEL 的解决方法。Software Collections 同样支持 Fedora 和 Scientific Linux 。
在 CentOS 6/7 上安装 Software Collections 的命令如下:
$ sudo yum install centos-release-scl
centos-release-scl-rh 可能作为依赖包被同时安装。
然后就可以像平常一样搜索、安装软件包了:
$ yum search php7
[...]
rh-php70.x86_64 : Package that installs PHP 7.0
[...]
$ sudo yum install rh-php70
最后一件事就是启用你的新软件包:
$ scl enable rh-php70 bash
$ php -v
PHP 7.0.10
此命令会开启一个新的 bash 并配置好环境变量以便运行新软件包。 如果需要的话,你还得安装对应的扩展包,比如对于 Python 、PHP、MySQL 等软件包,有些配置文件也需要修改以指向新版软件(比如 Apache )。
这些 SCL 软件包在重启后不会激活。SCL 的设计初衷就是在不影响原有配置的前提下,让新旧软件能一起运行。不过你可以通过 ~/.bashrc 加载 SCL 提供的 enable 脚本来实现自动启用。 SCL 的所有软件包都安装在 /opt 下, 以我们的 PHP 7 为例,在 ~/.bashrc 里加入一行:
source /opt/rh/rh-php70/enable
以后相应的软件包就能在重启后自动启用了。有新软件保驾护航,你终于可以专注于自己的业务了。
那么,到底 Software Collections 里都是些什么呢? centos-release-scl 里有一些由社区维护的额外的软件包。除了在 CentOS Wiki 查看软件包列表外,你还可以使用 Yum 。我们先来看看安装了哪些仓库:
$ yum repolist
[...]
repo id repo name
base/7/x86_64 CentOS-7 - Base
centos-sclo-rh/x86_64 CentOS-7 - SCLo rh
centos-sclo-sclo/x86_64 CentOS-7 - SCLo sclo
extras/7/x86_64 CentOS-7 - Extras
updates/7/x86_64 CentOS-7 - Updates
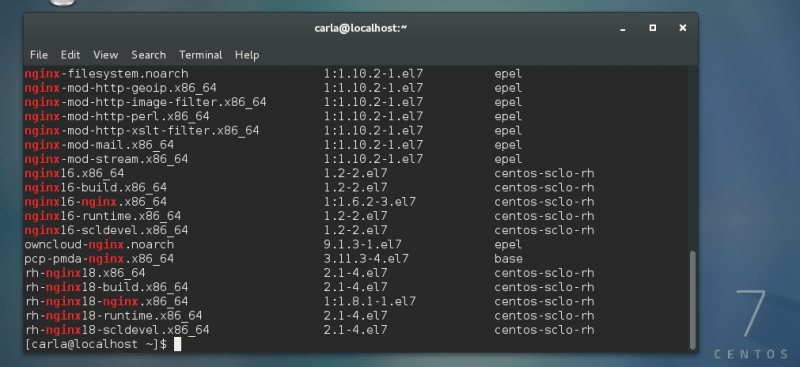
Yum 没有专门用来打印某一个仓库中所有软件包的命令,所以你得这样来: (LCTT 译注:实际上有,yum repo-pkgs REPO list,需要 root 权限,dnf 同)
$ yum --disablerepo "*" --enablerepo centos-sclo-rh \
list available | less
--disablerepo 与 --enablerepo 选项的用法没有详细的文档,这里简单说下。 实际上在这个命令里你并没有禁用或启用什么东西,而只是将你的搜索范围限制在某一个仓库内。 此命令会打印出一个很长的列表,所以我们用管道传递给 less 输出。
强大的 Fedora 社区为 Feora 及所有 RHEL 系的发行版维护着 EPEL:Extra Packages for Enterprise Linux 。 里面包含一些最新软件包以及一些未被发行版收纳的软件包。安装 EPEL 里的软件就不用麻烦 enable 脚本了,直接像平常一样用。你还可以用 --disablerepo 和 --enablerepo 选项指定从 EPEL 里安装软件包:
$ sudo yum --disablerepo "*" --enablerepo epel install [package]
Remi Collet 在 Remi 的 RPM 仓库 里维护着大量更新的和额外的软件包。需要先安装 EPEL ,因为 Remi 仓库依赖它。
CentOS wiki 上有较完整的仓库列表:更多的第三方仓库 ,用哪些,不用哪些,里面都有建议。
via: https://www.linux.com/learn/intro-to-linux/2017/2/best-third-party-repositories-centos
作者:CARLA SCHRODER 译者:Dotcra 校对:wxy