加速老旧 Ubuntu 系统的技巧

你的 Ubuntu 系统可以运行得如此顺畅,以至于你会奇怪为什么没有早一些从那些桌面加载很慢的操作系统(比如 Windows)转过来。Ubuntu 在大多数现代化的机器上都能够很顺畅的运行,一些更老的机器使用 Ubuntu 系统的一些变种版本,比如 Lubuntu、Xubuntu 和 Ubuntu MATE,同样给人留下了深刻印象。极少的情况下,你对 Ubuntu 桌面的使用体验会越来越糟。如果非常不走运,你的 Ubuntu 系统并没有像你所希望的那样运行顺畅,那么你可以做一些事情来提高系统性能和响应速度。
不过首先我们来看一看为什么电脑会运行得很慢?下面是我列举的一些原因:
- 电脑陈旧
- 安装了太多的应用
- 系统里的一些东西坏了
- 还有更多的原因...
现在让我们来看一些改善这个问题的技巧。
1、 交换值
如果你的系统有一个交换分区,那么这个技巧对你是最适合的(注:交换分区不建议为固态驱动器,因为这样会缩短驱动器的使用寿命)。交换分区可以帮助系统,特别是内存容量较低的系统,来管理系统内存。将数据写入交换分区(硬盘)比写入内存要慢一些,所以你可以通过减少 swappiness 值来限制数据写入交换分区的频率。默认情况下, Ubuntu 的 swappiness 值是 60%, 所以你可以通过下面的命令将它减至 10%:
sudo bash -c "echo 'vm.swappiness = 10' >> /etc/sysctl.conf"
2、 停止索引
索引的目的是加快搜索结果,但另一方面,索引会导致较老配置的系统出现一些问题。为了停止索引,输入下面的命令来移除索引工具:
sudo apt-get purge apt-xapian-index
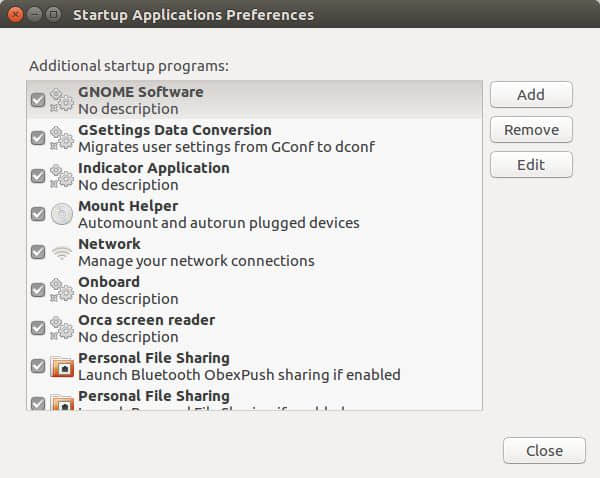
3、 管理 启动应用
启动应用会对系统性能造成很大的影响。当你安装一些应用以后,这些应用会添加启动项,从而当你启动系统的时候它们也跟着启动,但你可以移除这些应用以提高系统性能。通过在 Unity 窗口搜索打开 “启动应用”。绝大多数自启动选项都会被隐藏,所以在终端输入下面的命令使它们可见然后你就可以停止某些 “启动应用”了:
sudo sed -i "s/NoDisplay=true/NoDisplay=false/g" /etc/xdg/autostart/\*.desktop
4、 尝试预载入
预载入(preload) 是一个守护进程/后台服务,它可以监控系统上使用的应用程序,它会将所需要的二进制库在其需要加载到内存前就预先载入,以便应用程序启动得更快。在终端输入下面的命令安装预载入:
sudo apt-get install preload
5、 选择更加轻量型的应用
你在 Ubuntu 桌面上使用什么应用程序呢?有更轻量的替代品吗?如果有,就替换成它们——如果它们也能满足你的需求的话。 LibreOffice 能够给你最好的办公体验,但是它的替代品,比如 Abiword 能够很大程度的改善系统性能。
6、 切换到一个更加轻量型的桌面环境
你在 Ubuntu 系统上使用的桌面环境是 Unity 或 KDE 吗?这些桌面环境对系统的要求很高。相反,你可以在当前桌面环境之外同时安装一个 LxQt 或者 XFCE 环境,然后切换到它们。或者,你也可以换到 Ubuntu 的不同变种版本,比如 Lubuntu 或 Xubuntu ,从而享受更快的体验。
7、 清理系统垃圾
尽管 Ubuntu 系统不会变得像 Windows 系统那么慢,但它还是会变慢。清除系统里不需要的文件可以改善系统性能。尝试使用 Ubuntu Tweak 工具中的 Janitor 工具来清理系统。还有一个 Bleachbit 工具也可用来清理系统。
同时请阅读 - Bleachbit - CCleaner 的一个替代品
8、 尝试重新安装
有时,一些东西可能坏了,清理垃圾或者使用上面提到的大多数技巧都没用。这时,你唯一的选择就是备份文件,然后尝试重新安装。
9、 升级硬件
我列表上的最后一个技巧是升级硬件。在绝大多数情况下,这是可以的。如果可以这样做,那将极大的提高系统性能。你可以增加已安装的内存, 从传统磁盘切换到固态驱动器或者升级你的处理器,特别是如果你在台式电脑上运行 Ubuntu 系统,这将极大提高系统性能。
结论
我希望这些技巧能够陪伴你走很长的一段路,让你的 Ubuntu 桌面以一个令人印象深刻的速度运行。注意,你不需要尝试所有的技巧,只需要找到一个适合你的情况的技巧,然后观察系统响应如何变化。你还知道其他提高 Ubuntu 系统性能的技巧吗?请在评论里分享给我们。
via: http://www.linuxandubuntu.com/home/tips-to-improve-ubuntu-speed
作者:linuxandubuntu.com 译者:ucasFL 校对:jasminepeng