GitHub 2016 章鱼猫观察报告
GitHub 又发布了一年一度的章鱼猫观察报告。在这个报告中,分别对开源和社区做了一些有趣的统计,现将其中一些有趣的数据和趋势撷取出来分享给大家。完整的报告请移步此处。

GitHub 上最流行的开源项目
从让阿波罗 11 号登月的代码到开源课程,过去十二个月中,GitHub 上又涌现了一大批开源项目。以下是最流行的(得到星标最多)项目:
最流行的开源项目
其中使用最多的开源许可证是:MIT、Apache-2.0 和 GNU General Public License v3.0。
GitHub 上最爱用的编程语言
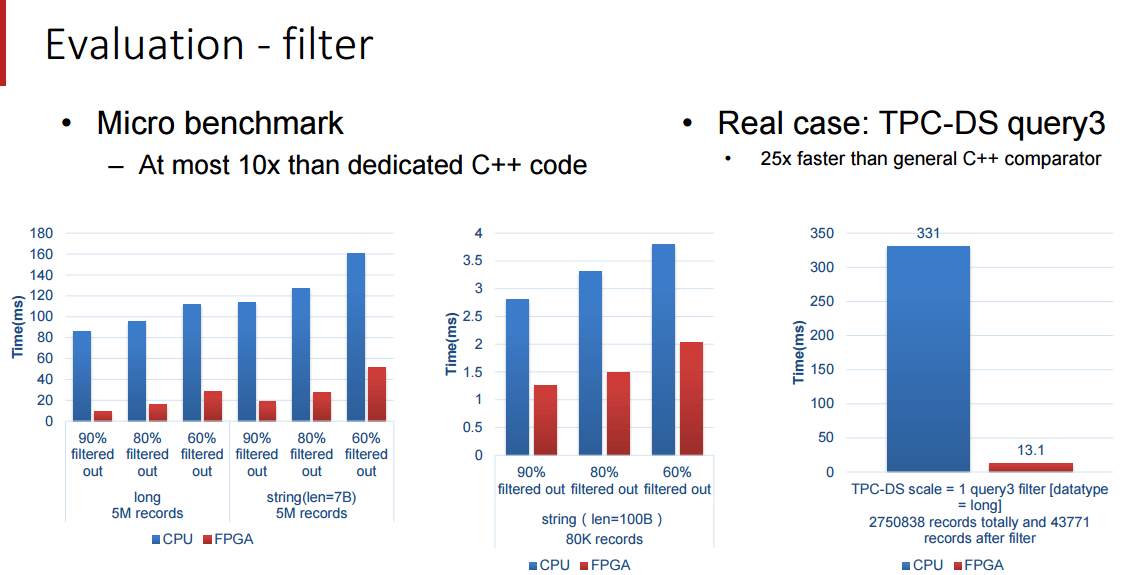
GitHub 上存放的开源项目使用了多达 316 种不同的编程语言,其中在过去十二月中提交的 PR( 拉取请求 ,用于向项目提交补丁) 使用最多的前 15 种编程语言是(其中的数字是 PR 数量):
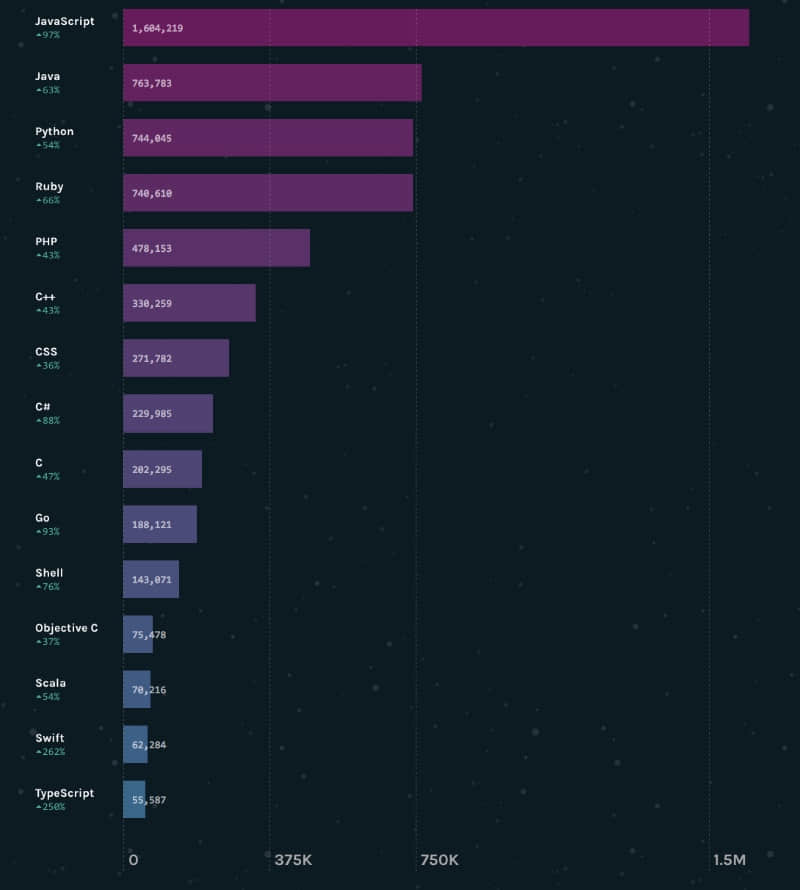
PR 中最流行的 15 种语言
PR 中最流行的语言居然是 JavaScript,是因为 JavaScript 比较容易么?而且 JavaScript、C# 和 Go 语言的 PR 增长率达到了两倍,甚至,Swift 和 TypeScript 虽然总量不多,但是增长率达到了 3.5 倍。
贡献者的活跃程度
“ 活跃 ”是指有过代码提交、写了备注、被星标和 问题汇报 等行为。
这十二个月以来,有 580 万以上的活跃用户、33 万以上的活跃组织、1.9 亿以上的活跃仓库、1 千万以上的活跃问题汇报。
“ 贡献者 ”是指对项目/仓库推送了代码、对打开或评论了问题和 PR 的人,按照贡献者对项目和组织进行排名:
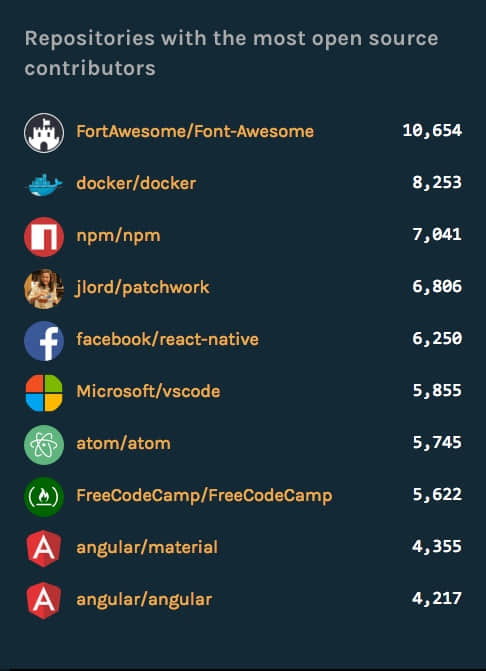
开源贡献者最多的前十个仓库
其中贡献者最多的仓库是 Font-Awesome 项目,这是一个图标字体的项目,不太理解为何有这么多的贡献者。其次是 docker 和 npm。
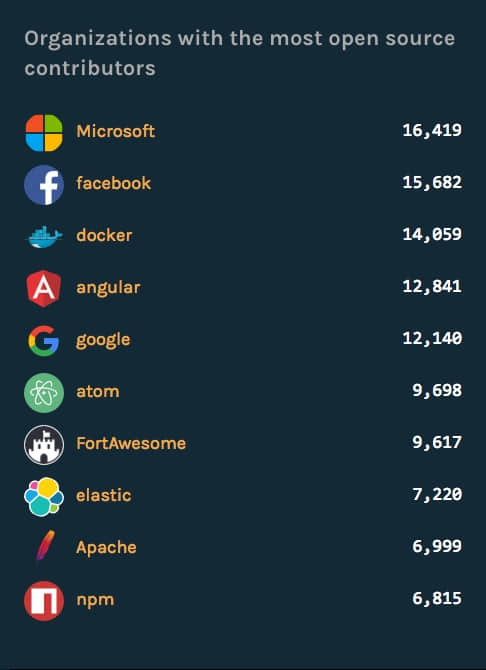
开源贡献者最多的组织
开源贡献者最多的组织是微软,超过了 Facebook、docker,以及谷歌。看来微软这一年确实是在开源方面下了死力。
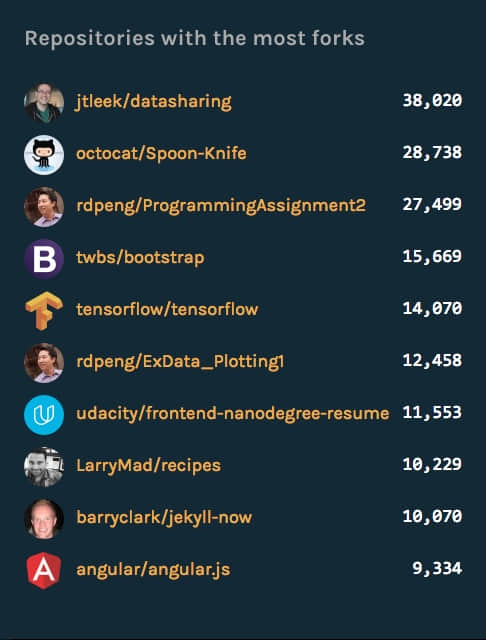
被最多分支的仓库
仓库被 分支 的越多代表了对它感兴趣、甚至会参与到开发中的人越多。这个排名第一的 datasharing 是个啥项目,我去看看——居然是一篇文章……好吧,让我看看第二个 Spoon-Knife,这,是章鱼猫的一个教人如何分支仓库的例子……那么第三个 ProgrammingAssignment2 ,哎,也是一个课程上用的例子……
好吧,我收回之前对分支的看法,就不能有个“正常”点的仓库嘛?
还好,第四 bootstrap 和第五 tensorflow 都是比较正常的开源项目。总之,项目流行不流行,不要看分支数量了。
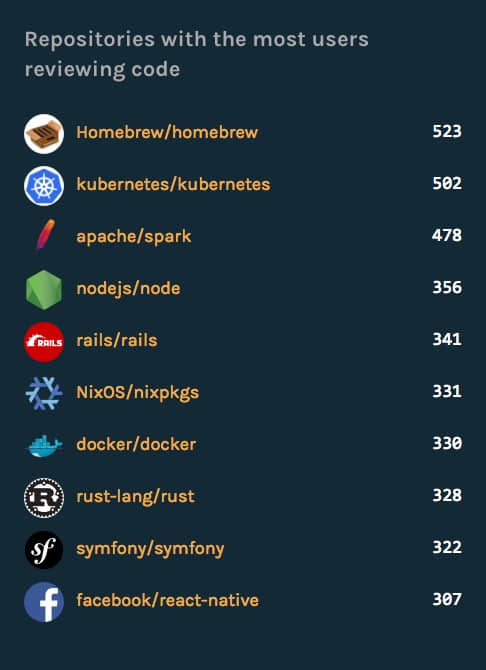
被最多用户评审过代码的仓库
这里的 代码评审者 指的是对修改过的代码进行过评论的人,这也代表贡献者对仓库的关注度。好吧。我除了对第一名 homebrew 有点不解,其它的几名都觉得还算正常。
GitHub 的新增用户
GitHub 已经有超过 520 万的用户和超 30 万的组织。这十二月以来,有超过 81 万的人发起了人生第一个 PR,更有 280 万人创造了他自己的第一个仓库。

新用户注册增长最多的国家
而中国,是新用户注册增长最多的国家,基本上翻了一番。
GitHub 上的组织
GitHub 上已经有超过 8 千万的 PR,而这些 PR 中有超过 85% 的来自于组织。在 GitHub 上以组织形式活动的除了商业性组织以外,很多大公司也在其企业的开发中采用了 GitHub Enterprise ,其中不乏财富50强里面公司。
总结
报告就解读到这里,详细的图文并茂的报告,请移步 GitHub。