Python 数据科学入门
不需要昂贵的工具即可领略数据科学的力量,从这些开源工具起步即可。

无论你是一个具有数学或计算机科学背景的资深数据科学爱好者,还是一个其它领域的专家,数据科学提供的可能性都在你力所能及的范围内,而且你不需要昂贵的,高度专业化的企业级软件。本文中讨论的开源工具就是你入门时所需的全部内容。
Python,其机器学习和数据科学库(pandas、 Keras、 TensorFlow、 scikit-learn、 SciPy、 NumPy 等),以及大量可视化库(Matplotlib、pyplot、 Plotly 等)对于初学者和专家来说都是优秀的自由及开源软件工具。它们易于学习,很受欢迎且受到社区支持,并拥有为数据科学而开发的最新技术和算法。它们是你在开始学习时可以获得的最佳工具集之一。
许多 Python 库都是建立在彼此之上的(称为依赖项),其基础是 NumPy 库。NumPy 专门为数据科学设计,经常被用于在其 ndarray 数据类型中存储数据集的相关部分。ndarray 是一种方便的数据类型,用于将关系表中的记录存储为 cvs 文件或其它任何格式,反之亦然。将 scikit 函数应用于多维数组时,它特别方便。SQL 非常适合查询数据库,但是对于执行复杂和资源密集型的数据科学操作,在 ndarray 中存储数据可以提高效率和速度(但请确保在处理大量数据集时有足够的 RAM)。当你使用 pandas 进行知识提取和分析时,pandas 中的 DataFrame 数据类型和 NumPy 中的 ndarray 之间的无缝转换分别为提取和计算密集型操作创建了一个强大的组合。
作为快速演示,让我们启动 Python shell 并在 pandas DataFrame 变量中加载来自巴尔的摩的犯罪统计数据的开放数据集,并查看加载的一部分 DataFrame:
>>> import pandas as pd
>>> crime_stats = pd.read_csv('BPD_Arrests.csv')
>>> crime_stats.head()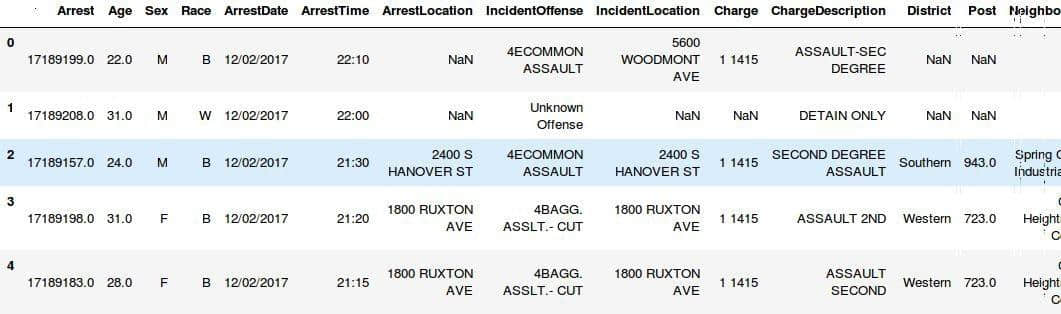
我们现在可以在这个 pandas DataFrame 上执行大多数查询,就像我们可以在数据库中使用 SQL 一样。例如,要获取 Description 属性的所有唯一值,SQL 查询是:
$ SELECT unique(“Description”) from crime_stats;利用 pandas DataFrame 编写相同的查询如下所示:
>>> crime_stats['Description'].unique()
['COMMON ASSAULT' 'LARCENY' 'ROBBERY - STREET' 'AGG. ASSAULT'
'LARCENY FROM AUTO' 'HOMICIDE' 'BURGLARY' 'AUTO THEFT'
'ROBBERY - RESIDENCE' 'ROBBERY - COMMERCIAL' 'ROBBERY - CARJACKING'
'ASSAULT BY THREAT' 'SHOOTING' 'RAPE' 'ARSON']它返回的是一个 NumPy 数组(ndarray 类型):
>>> type(crime_stats['Description'].unique())
<class 'numpy.ndarray'>接下来让我们将这些数据输入神经网络,看看它能多准确地预测使用的武器类型,给出的数据包括犯罪事件,犯罪类型以及发生的地点:
>>> from sklearn.neural_network import MLPClassifier
>>> import numpy as np
>>>
>>> prediction = crime_stats[[‘Weapon’]]
>>> predictors = crime_stats['CrimeTime', ‘CrimeCode’, ‘Neighborhood’]
>>>
>>> nn_model = MLPClassifier(solver='lbfgs', alpha=1e-5, hidden_layer_sizes=(5,
2), random_state=1)
>>>
>>>predict_weapon = nn_model.fit(prediction, predictors)现在学习模型准备就绪,我们可以执行一些测试来确定其质量和可靠性。对于初学者,让我们输入一个训练集数据(用于训练模型的原始数据集的一部分,不包括在创建模型中):
>>> predict_weapon.predict(training_set_weapons)
array([4, 4, 4, ..., 0, 4, 4])如你所见,它返回一个列表,每个数字预测训练集中每个记录的武器。我们之所以看到的是数字而不是武器名称,是因为大多数分类算法都是用数字优化的。对于分类数据,有一些技术可以将属性转换为数字表示。在这种情况下,使用的技术是标签编码,使用 sklearn 预处理库中的 LabelEncoder 函数:preprocessing.LabelEncoder()。它能够对一个数据和其对应的数值表示来进行变换和逆变换。在这个例子中,我们可以使用 LabelEncoder() 的 inverse_transform 函数来查看武器 0 和 4 是什么:
>>> preprocessing.LabelEncoder().inverse_transform(encoded_weapons)
array(['HANDS', 'FIREARM', 'HANDS', ..., 'FIREARM', 'FIREARM', 'FIREARM']这很有趣,但为了了解这个模型的准确程度,我们将几个分数计算为百分比:
>>> nn_model.score(X, y)
0.81999999999999995
这表明我们的神经网络模型准确度约为 82%。这个结果似乎令人印象深刻,但用于不同的犯罪数据集时,检查其有效性非常重要。还有其它测试来做这个,如相关性、混淆、矩阵等。尽管我们的模型有很高的准确率,但它对于一般犯罪数据集并不是非常有用,因为这个特定数据集具有不成比例的行数,其列出 FIREARM 作为使用的武器。除非重新训练,否则我们的分类器最有可能预测 FIREARM,即使输入数据集有不同的分布。
在对数据进行分类之前清洗数据并删除异常值和畸形数据非常重要。预处理越好,我们的见解准确性就越高。此外,为模型或分类器提供过多数据(通常超过 90%)以获得更高的准确度是一个坏主意,因为它看起来准确但由于过度拟合而无效。
Jupyter notebooks 相对于命令行来说是一个很好的交互式替代品。虽然 CLI 对于大多数事情都很好,但是当你想要运行代码片段以生成可视化时,Jupyter 会很出色。它比终端更好地格式化数据。
这篇文章 列出了一些最好的机器学习免费资源,但是还有很多其它的指导和教程。根据你的兴趣和爱好,你还会发现许多开放数据集可供使用。作为起点,由 Kaggle 维护的数据集,以及在州政府网站上提供的数据集是极好的资源。
via: https://opensource.com/article/18/3/getting-started-data-science
作者:Payal Singh 译者:MjSeven 校对:wxy





{kind=link}