分支与发行版有什么不同?
开源软件的发行版和分支是不一样的。了解其中的区别和潜在的风险。

如果你们对开源软件有过一段时间的了解,一定曾在许多相关方面中听说过 分支 和 发行版 两个词。许多人对这两个词的区别不太清楚,因此我将试着通过这篇文章为大家解答这一疑惑。
(LCTT 译注:fork 一词,按我们之前的倡议,在版本控制工作流中,为了避免和同一个仓库的 branch 一词混淆,我们建议翻译为“复刻”。但是在项目和发行版这个语境下,没有这个混淆,惯例上还是称之为“分支”。)
首先,一些定义
在解释分支与发行版两者的细微区别与相似之处之前,让我们先给一些相关的重要概念下定义。
开源软件 是指具有以下特点的软件:
- 在特定的 许可证 限制下,软件供所有人免费分发
- 在特定的许可证限制下,软件源代码可以供所有人查看与修改
开源软件可以按以下方式 使用:
- 以二进制或者源代码的方式下载,通常是免费的。(例如,Eclipse 开发者环境)
- 作为一个商业公司的产品,有时向用户提供一些服务并以此收费。(例如,红帽产品)
- 嵌入在专有的软件解决方案中。(例如一些智能手机和浏览器用于显示字体的 Freetype 软件)
自由开源软件 (FOSS)不一定是“零成本”的“ 免费 ”。自由开源软件仅仅意味着这个软件在遵守软件许可证的前提下可以自由地分发、修改、研究和使用。软件分发者也可能为该软件定价。例如,Linux 可以是 Fedora、Centos、Gentoo 等免费发行版,也可以是付费的发行版,如红帽企业版 Linux(RHEL)、SUSE Linux 企业版(SLES)等。
社区 指的是在一个开源项目上协作的团体或个人。任何人或者团体都可以在遵守协议的前提下,通过编写或审查代码/文档/测试套件、管理会议、更新网站等方式为开源项目作出贡献。例如,在 Openhub.net 网站上,我们可以看见政府、非营利性机构、商业公司和教育团队等组织都在 为一些开源项目作出贡献。
一个开源 项目 是集协作开发、文档和测试的结果。大多数项目都搭建了一个中央仓库用来存储代码、文档、测试文件和目前正在开发的文件。
发行版 是指开源项目的一份的二进制或源代码的副本。例如,CentOS、Fedora、红帽企业版 Linux(RHEL)、SUSE Linux、Ubuntu 等都是 Linux 项目的发行版。Tectonic、谷歌的 Kubernetes 引擎(GKE)、亚马逊的容器服务和红帽的 OpenShift 都是 Kubernetes 项目的发行版。
开源项目的商业发行版经常被称作 产品 ,因此,红帽 OpenStack 平台是红帽 OpenStack 的产品,它是 OpenStack 上游项目的一个发行版,并且是百分百开源的。
主干 是开发开源项目的社区的主要工作流。
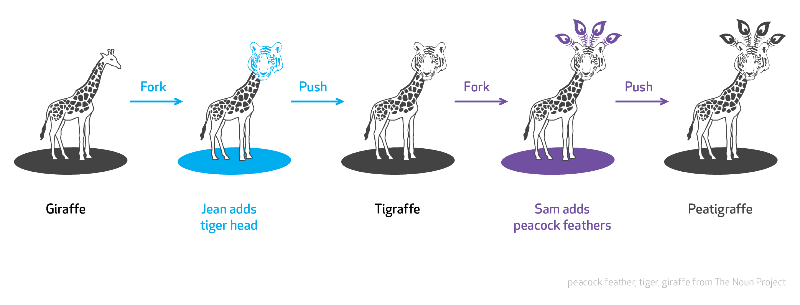
开源分支fork是开源项目主干的一个版本,它是分离自主干的独立工作流。
因此,发行版并不等同于分支。发行版是上游项目的一种包装,由厂商提供,经常作为产品进行销售。然而,发行版的核心代码和文档与上游项目的版本保持一致。分支,以及任何基于分支的的发行版,导致代码和文档的版本与上游项目不同。对上游项目进行了分支的用户必须自己来维护分支项目,这意味着他们失去了上游社区协同工作带来的好处。
为了进一步解释软件分支,让我来用动物迁徙作比喻。鲸鱼和海狮从北极迁徙到加利福尼亚和墨西哥;帝王斑蝶从阿拉斯加迁徙到墨西哥;并且北半球的燕子和许多其他鸟类飞翔南方去过冬。成功迁徙的关键因素在于,团队中的所有动物团结一致,紧跟领导者,找到食物和庇护所,并且不会迷路。
独立前行带来的风险
一只鸟、帝王蝶或者鲸鱼一旦掉队就失去了许多优势,例如团队带来的保护,以及知道哪儿有食物、庇护所和目的地。
相似地,从上游版本获取分支并且独立维护的用户和组织也存在以下风险:
- 由于代码不同,分支用户不能够基于上游版本更新代码。 这就是大家熟知的技术债,对分支的代码修改的越多,将这一分支重新归入上游项目需要花费的时间和金钱成本就越高。
- 分支用户有可能运行不太安全的代码。 由于代码不同的原因,当开源代码的漏洞被找到,并且被上游社区修复时,分支版本的代码可能无法从这次修复中受益。
- 分支用户可能不会从新特性中获益。 拥有众多组织和个人支持的上游版本,将会创建许多符合所有上游项目用户利益的新特性。如果一个组织从上游分支,由于代码不同,它们可能无法纳入新的功能。
- 它们可能无法和其他软件包整合在一起。 开源项目很少是作为单一实体开发的;相反地,它们经常被与其他项目打包在一起构成一套解决方案。分支代码可能无法与其他项目整合,因为分支代码的开发者没有与上游的其他参与者们合作。
- 它们可能不会得到硬件平台认证。 软件包通常被搭载在硬件平台上进行认证,如果有问题发生,硬件与软件工作人员可以合作找出并解决问题发生的根源。
总之,开源发行版只是一个来自上游的、多组织协同开发的、由供应商销售与支持的打包集合。分支是一个开源项目的独立开发工作流,有可能无法从上游社区协同工作的结果中受益。
via: https://opensource.com/article/18/7/forks-vs-distributions
作者:Jonathan Gershater 选题:lujun9972 译者:Wlzzzz-del 校对:wxy