Kubernetes 复杂吗?可以不复杂

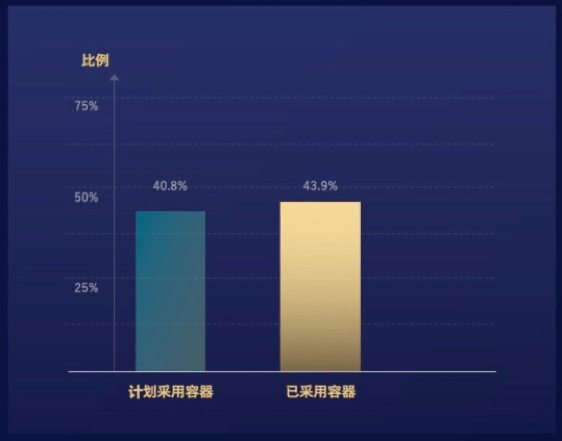
作为云原生的核心产品,Kubernetes 提供的编排和管理功能,能轻松完成大规模容器部署,但 Kubernetes 自身的复杂性也导致众多企业一直徘徊于容器服务之外。据调查,只有不足 10% 的用户表示使用 Kubernetes 时没有遇到阻碍。
在 2019 年的一个关于容器技术的一个调查数据中,有 40% 的受访者表示计划采用容器。然而,据 UCloud 产品经理张鹏波透露说,在他们接触的用户当中,曾经在两年前表示有兴趣迁移到容器的用户,两年过去了,这些用户很多依旧“计划采用”容器服务。
这让我好奇其中发生了什么。让我们一起来探寻一下其中的症结,以及是否可以将复杂的 Kubernetes变得不复杂。
Kubernetes 复杂吗?
自从 2017 年,Kubernetes 在容器编排三强争霸赛中胜出后,就成为了容器编排领域的事实标准,极大的助推了容器技术在业界的发展。作为企业级的容器服务编排系统,Kubernetes 从技术上是现在、乃至未来的主流。
容器拥有很多优点,包括不可变环境、轻量级、快速启动等优势;而容器编排系统又在此基础上更进一步,提供了更加强大的功能,包括自动部署、快速扩容、故障自愈等等。

然而,在这一系列令人神往的优势和功能背后,Kubernetes 也相应的引入了更多的复杂性。这些复杂性体现在多个方面,比如说:
- 首先是 Kubernetes 架构,本质上,Kubernetes 是用来管理分布式系统的平台。而一说到分布式,复杂性是不可避免的,管理分布式系统的平台自然也不例外。
- 另外是容器支持的网络,Kubernetes 支持的网络类型很多。很多用户对于 Kubernetes 的网络非常疑惑或者说很纠结,当业务要迁移到 Kubernetes 时,选择什么类型的网络是一个难以抉择的问题。特别是在业务迁移上去之后又遇到一些问题的话,排查起来会非常麻烦,这给用户带来很大负担。
- 最后还有就是各种各样 Kubernetes 组件的配置,这些都是用户将业务迁移到 Kubernetes 的障碍。
有什么解决方案吗?
如上所述,并不是每个用户都能尝到桃子的美味的,还有很多渴望迁移到容器环境的用户被拒之门外。
在这种情况下,全球各家云服务商,都纷纷推出自己的容器编排服务,在 Kubernetes上构建了自己的 Kubernetes发行版或定制产品。
而作为中国第一家公有云科创板上市公司,UCloud 利用在 UK8S 产品的技术沉淀,推出新的容器管理服务产品 Cube:两步即可部署容器化应用;采用无服务器形态,不需要再维护底层基础设施;按秒后付费,无需预留资源;降低企业部署云原生产品的学习和技术门槛。
为什么要推出 Cube?
在容器和 Kubernetes 如火如荼发展的同时,UCloud 发现,在他们的 UK8S 上线大概两年多的时间里,之前曾经想把业务迁到 Kubernetes 的用户。在两年后的今天,他们还是说这个话,说我很想上 Kubernetes,还需要你们来做技术交流。
UCloud 产品经理张鹏波说:
这让我们一度很困惑,我们一开始也做了一些尝试,比如说做了很多线下的培训、线上的交流,尝试去推动用户把他们的业务迁移到 UK8S 里面来。但是发现这个过程非常缓慢,我们没有办法控制和推动用户的迁移流程。很多公司的业务在快速发展,运维和研发是没有办法做架构上的调整的。
发现沟通、培训这条路实际上是走不通之后的。后来我们想,能不能换一条路,能不能基于 Kubernetes提供这样一个产品:这个产品只具有 Kubernetes 好处,掩盖了 Kubernetes 的复杂性,只提供类似于自动部署、快速扩容这样的特性,而用户不需要关心底层的 Kubernetes 架构,不需要再操心 Kubernetes 的网络了,也不需要去学习 Kubernetes 的各种 API 了。
Cube 的设计思路
沿着这个思路,UCloud 形成了自己的 Cube 产品。它的设计是从以下几个方面考虑的:
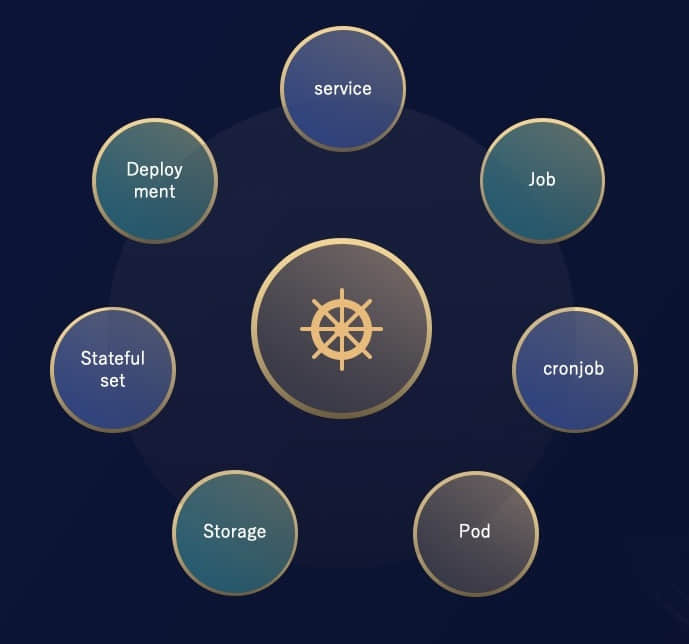
首先,Kubernetes 里面哪些功能是会经常会用到的,比如 Deployment 控制多副本容器组的管理, Job 控制任务型容器组,Service 做服务发现,PVC可以用来抽象使用块存储以及文件存储。这是 Kubernetes 最核心的一些功能。UCloud 在设计 Cube 的时候,希望将这些功能全部保留。这意味着整个 Cube 是基于 Kubernetes 来实现的。把这些复杂性全部屏蔽掉,用户不需要维护 Kubernetes 集群,不需要操心 Kubernetes 网络方案,而是由 Cube 提供一个最优网络方案,把容器的网络和虚拟机的网络扁平化。
其次,把业务迁移到 Kubernetes 的时候,把单体业务变成分布式业务、微服务的时候,用户一定需要考虑容器日志的统一收集、统一管理的问题。在 Cube 里面自动完成了日志的采集工作,集成了日志管理工作。另外,对容器环境的监控也是同样的道理,统一在 Cube 中完成。

当把这些产品全部集成到 Cube 里以后,Cube 是一个什么样的产品形态呢?
首先保证 Kubernetes 最核心的功能,用户能够在 Cube 里面创建 Kubernetes 常用的对象;另外 Cube 的产品形态应该是无服务器的形式;最后,Cube 引入了轻量级的虚拟化技术,实现了容器组与容器组之间虚拟机级别的隔离,这样好处是什么呢?
我们都知道容器的运行是共享使用宿主机的内核的,存在一定的安全风险,Cube 为每一个容器组实现了一层虚拟机的封装,可以使用户安全的运行容器;同时 UCloud 容器团队针对虚拟机的启动进行了深入优化,虚拟机启动速度最快只需要 125 毫秒。
Cube 的功能亮点
快速迁移
让我们横向对比一下,用户使用 Kubernetes 和 Cube 的流程上会有哪些区别。
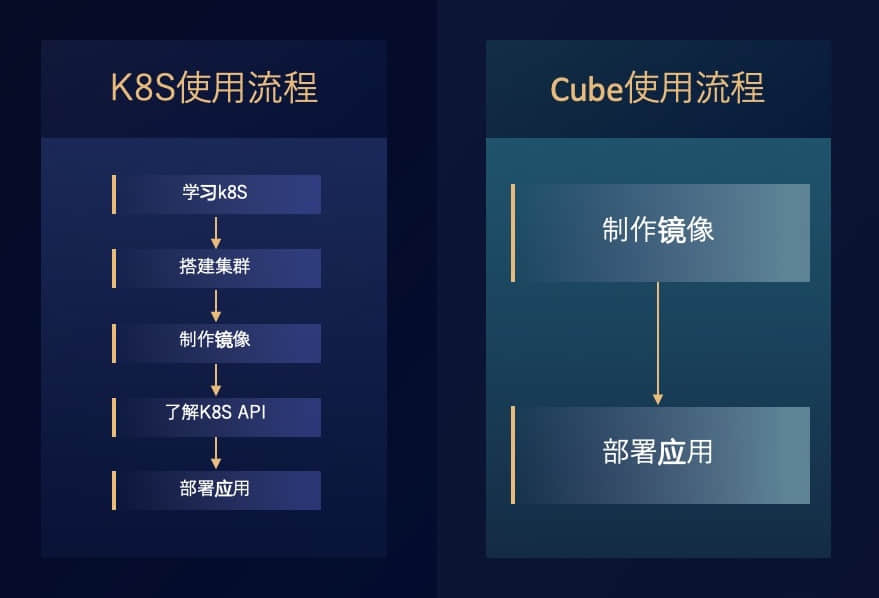
左边是 Kubernetes,用户要把业务迁移到 Kubernetes,大概要经过这几个步骤:
- 第一个步骤学习 Kubernetes,不仅仅是一个人,也可能不仅仅是一个团队,这个过程可能需要三个月到一年。
- 搭建集群,考虑集群的参数配置、集群的维护工作。
- 然后是做业务镜像。
- 之后还要考虑了解 Kubernetes的 API 以及 Kubernetes 应用。
- 最后才部署应用。
从 UCloud 观察到的情况来看,如果是对 Kubernetes非常熟悉的用户,这个过程可能要一两个月;但是如果对 Kubernetes 不熟悉,需要半年乃至一年。
使用 Cube 的话,就不再需要学习复杂的 Kubernetes知识了,和创建虚拟机一样在 Cube 里面创建一个应用,全部都是图形化的方式。所以,Cube 整个流程只有两步:
- 制作镜像。
- 在 Cube 的界面上直接部署应用就好了。
UCloud 产品经理张鹏波说,“我们有几个用户知道了 Cube 公测,公测以后第一天进行了解,第二天就把自己部署的业务迁移到 Cube 上来了,一天的时间就可以完成业务迁移的工作。”
成本降低
另外在成本方面,我们知道 Kubernetes 是一个大型的分布式集群,除了工作节点以外,还有管理节点。管理节点只是用来管理 Kubernetes 支持的应用,这部分开销实际上从企业角度来看是浪费的。对业务没有起到正向的作用,所以 Kubernetes 成本会比较高。
而对于 Cube,因为只需要为容器实例来付费,容器用了多少资源就付多少钱,不再考虑管理节点的开销、资源预留的问题。
更多的便利性
此外,还有一些其他针对 Kubernetes 自身的一些的改进。在 Cube 整个研发过程中,引入了一些亮点。
第一个是镜像预热,我们知道容器的启动速度其实很快的,基本一秒钟就能拉起来容器实例。但是这是热启动的情况,就是说工作节点上有这个镜像时,拉起来速度是很快的。而在冷启动的情况下,如果虚拟机上没有对应的镜像时,并且镜像非常大时,这个过程就非常缓慢了。我们遇到过最大的镜像有 20G 以上,容器的启动的时间就要花费几分钟。这样,容器本来说快速启动的优势就没有了,比虚拟机还慢了。所以,UCloud 在研发 Cube 的时候,使用了镜像预热的技术,把容器镜像变成 MBD 设备,在容器启动的时候,把它纳入到启动容器的节点上去,省去了镜像拉起的时间,让容器冷启动的时间从以前需要十几分钟变成现在只要几秒钟就拉起来了。
另外,因为 Kubernetes 是由谷歌开源的一项方案,很多理念和大部分企业更加超前一点。所以,在这种设计理念下,Kubernetes 每一个容器在重启以后,容器的 IP 就会变化。而我们知道很多传统的应用设计上是依赖于固定 IP 的,IP 一旦变化整个应用就会出现一些问题。很多用户都希望让容器重启后 IP 保持不变。这对于特别是有状态的服务尤为重要。所以,在 Cube 里面使用了 UCloud 的 EIP 功能,能够让用户容器重启时其 IP 保持不变。
最后,Cube 要兼容原有的运维习惯。传统上,虚拟机和 IDC 里面的物理机在使用体验上是没有什么差别的。有些用户之前业务部署在虚拟机,经常需要在出现问题的时候,直接登录到虚拟机里面去排错,查看一些日志。所以,为了兼容用户以前使用虚拟机的习惯,在 Cube 里面的容器也提供了登录功能,让用户在业务出现问题的时候,能够登录到容器里去快速排查问题。
结语
说实话,关于 Kubernetes 和各种发行版,我们也看过和研究过不少产品了,但是更多的是叶公好龙,没有将自己的应用迁移到 Kubernetes上的想法。一方面对着 Kubernetes 的各种先进特性馋涎欲滴,另外一方面却担心没有足够的精力面对全新的技术变化带来的挑战。
不过,今天看到 UCloud 的 Cube 产品,我决定要去亲自试试这个桃子的味道了。