使用 Kubespray 安装 Kubernetes 集群

你是否正在寻找有关如何使用 Kubespray 安装 Kubernetes(k8s)的简单指南?
此页面上的分步指南将向你展示如何在 Linux 系统上使用 Kubespray 安装 Kubernetes 集群。
Kubespray 是一个自由开源的工具,它提供了 Ansible 剧本 来部署和管理 Kubernetes 集群。它旨在简化跨多个节点的 Kubernetes 集群的安装过程,允许用户快速轻松地部署和管理生产就绪的 Kubernetes 集群。
它支持一系列操作系统,包括 Ubuntu、CentOS、Rocky Linux 和 Red Hat Enterprise Linux(RHEL),它可以在各种平台上部署 Kubernetes,包括裸机、公共云和私有云。
在本指南中,我们使用以下实验室:
- Ansible 节点(Kubespray 节点):最小安装的 Ubuntu 22.04 LTS(192.168.1.240)
- 3 个控制器节点:最小安装的 Rocky Linux 9(192.168.1.241/242/243)
- 2 个工作节点:最小安装的 Rocky Linux 9(192.168.1.244/245)
Kubespray 的最低系统要求
- 主节点:1500 MB RAM、2 个 CPU 和 20 GB 可用磁盘空间
- 工作节点:1024 MB、2 个 CPU、20 GB 可用磁盘空间
- Ansible 节点:1024 MB、1 个 CPU 和 20 GB 磁盘空间
- 每个节点上的互联网连接
- 拥有 sudo 管理员权限
事不宜迟,让我们深入了解安装步骤。
步骤 1)配置 Kubespray 节点
登录到你的 Ubuntu 22.04 系统并安装 Ansible。运行以下一组命令:
$ sudo apt update
$ sudo apt install git python3 python3-pip -y
$ git clone https://github.com/kubernetes-incubator/kubespray.git
$ cd kubespray
$ pip install -r requirements.txt
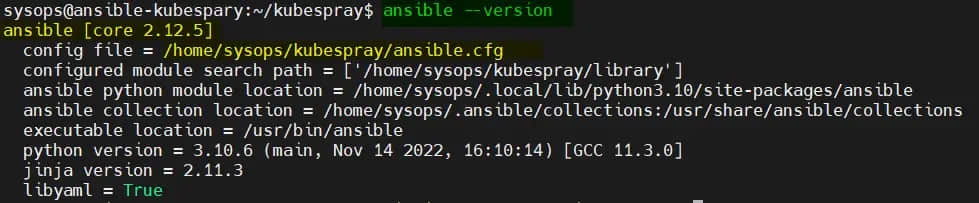
验证 Ansible 版本,运行:
$ ansible --version
创建主机清单,运行以下命令,不要忘记替换适合你部署的 IP 地址:
$ cp -rfp inventory/sample inventory/mycluster
$ declare -a IPS=(192.168.1.241 192.168.1.241 192.168.1.242 192.168.1.243 192.168.1.244 192.168.1.245)
$ CONFIG_FILE=inventory/mycluster/hosts.yaml python3 contrib/inventory_builder/inventory.py ${IPS[@]}
修改清单文件,设置 3 个控制节点和 2 个工作节点:
$ vi inventory/mycluster/hosts.yaml
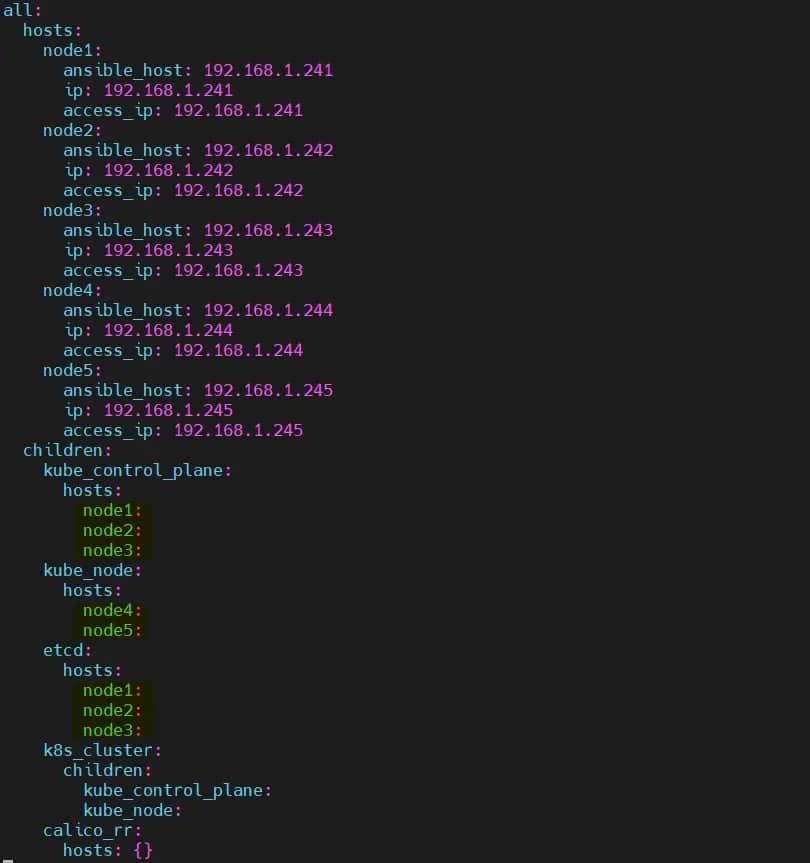
保存并关闭文件。
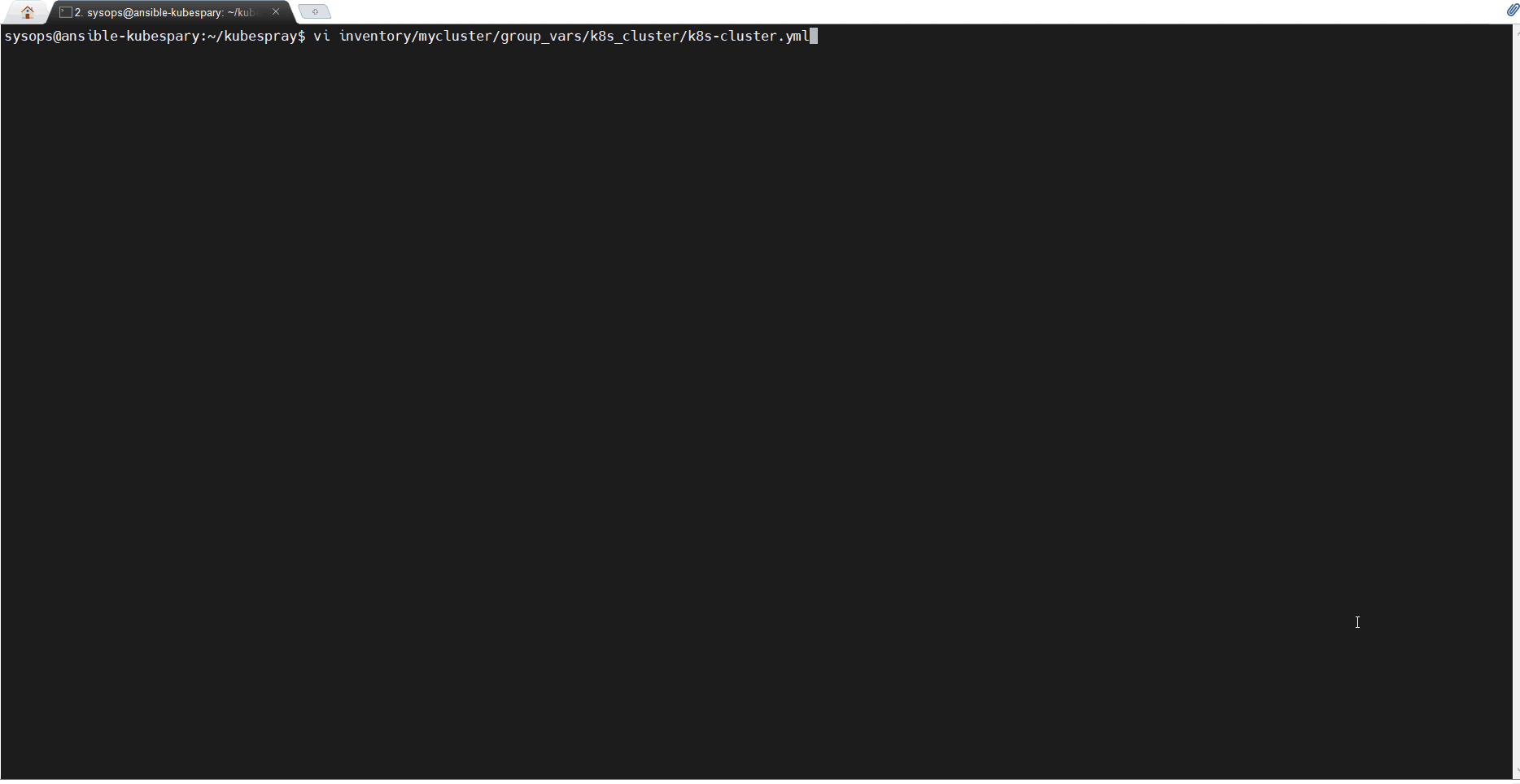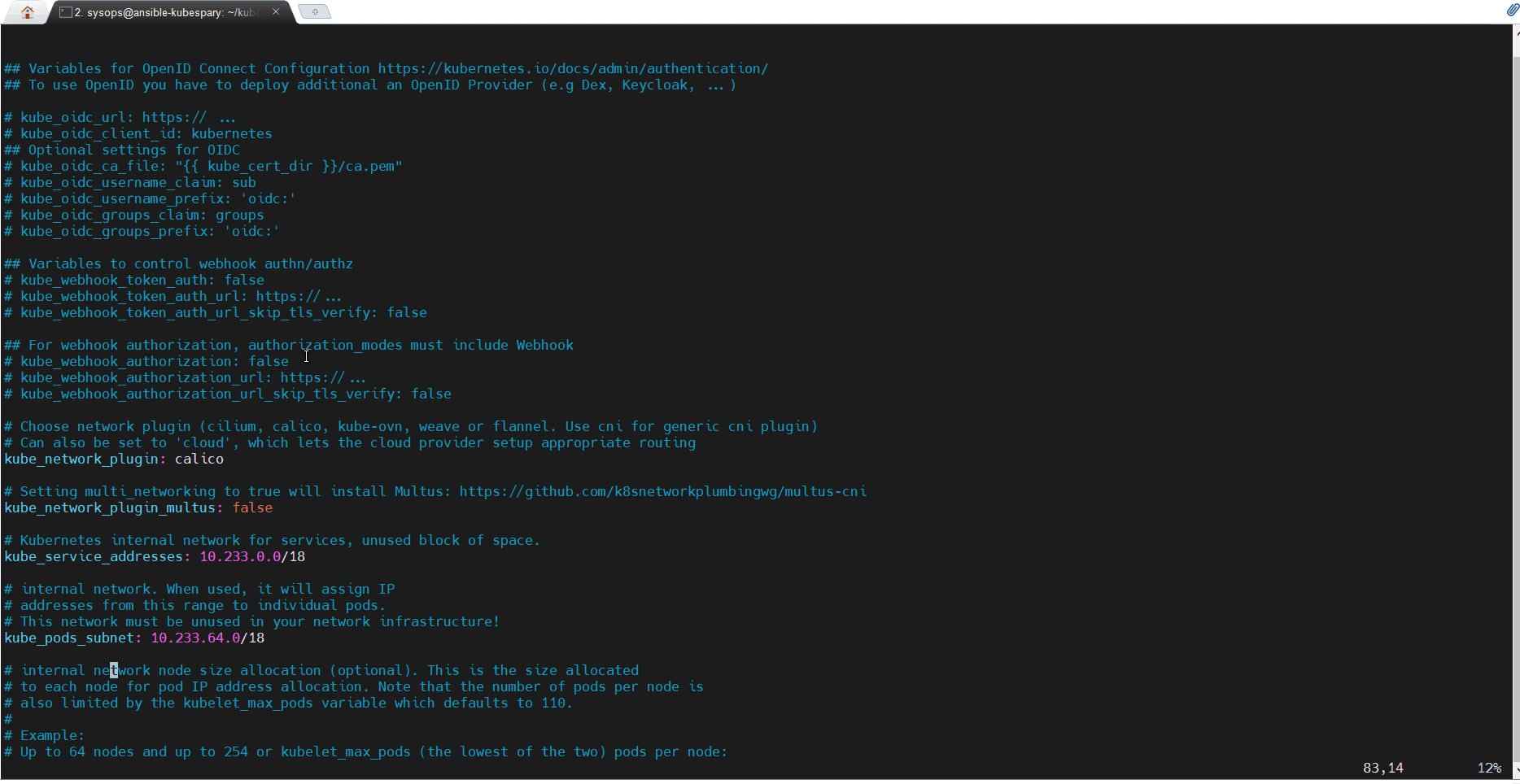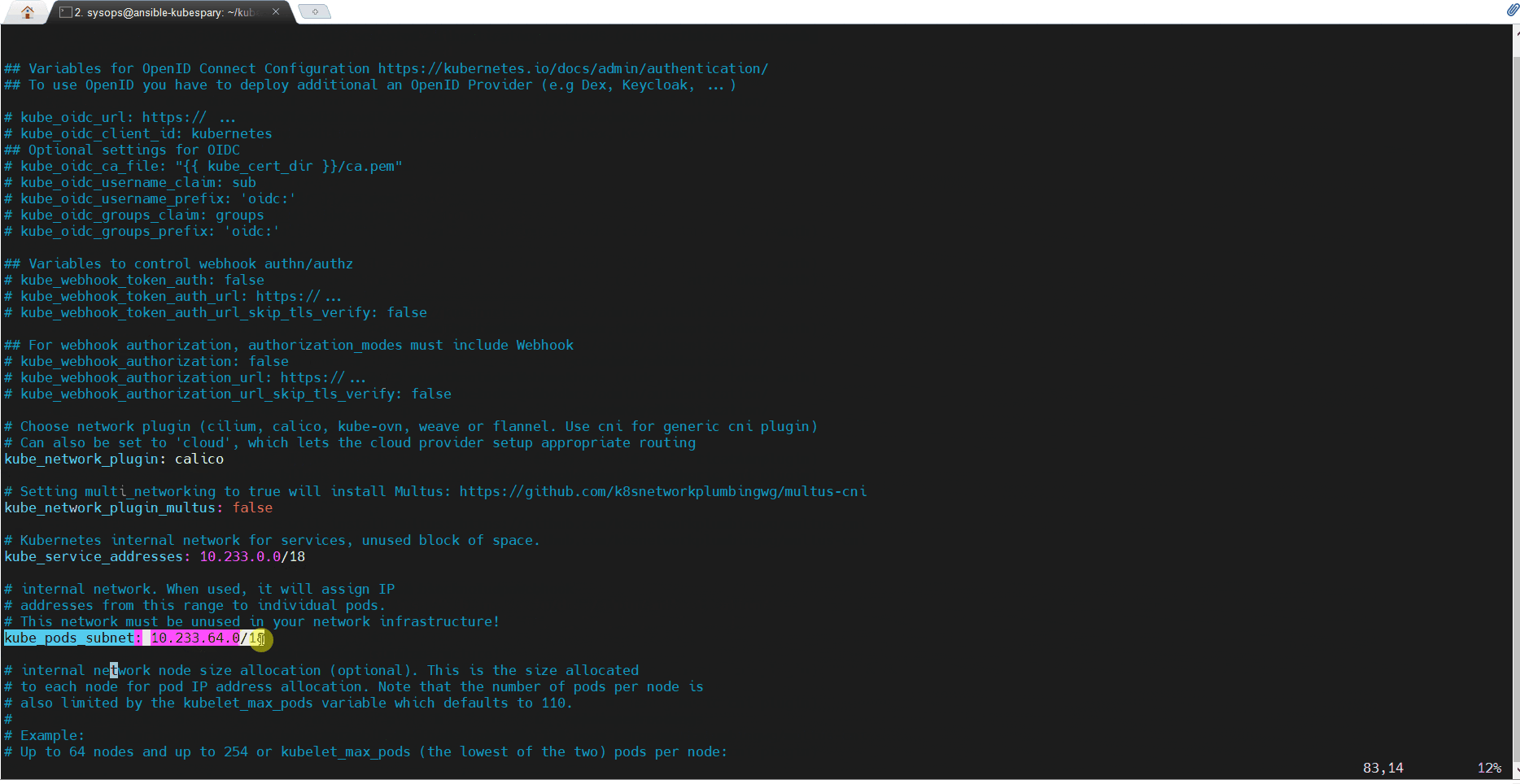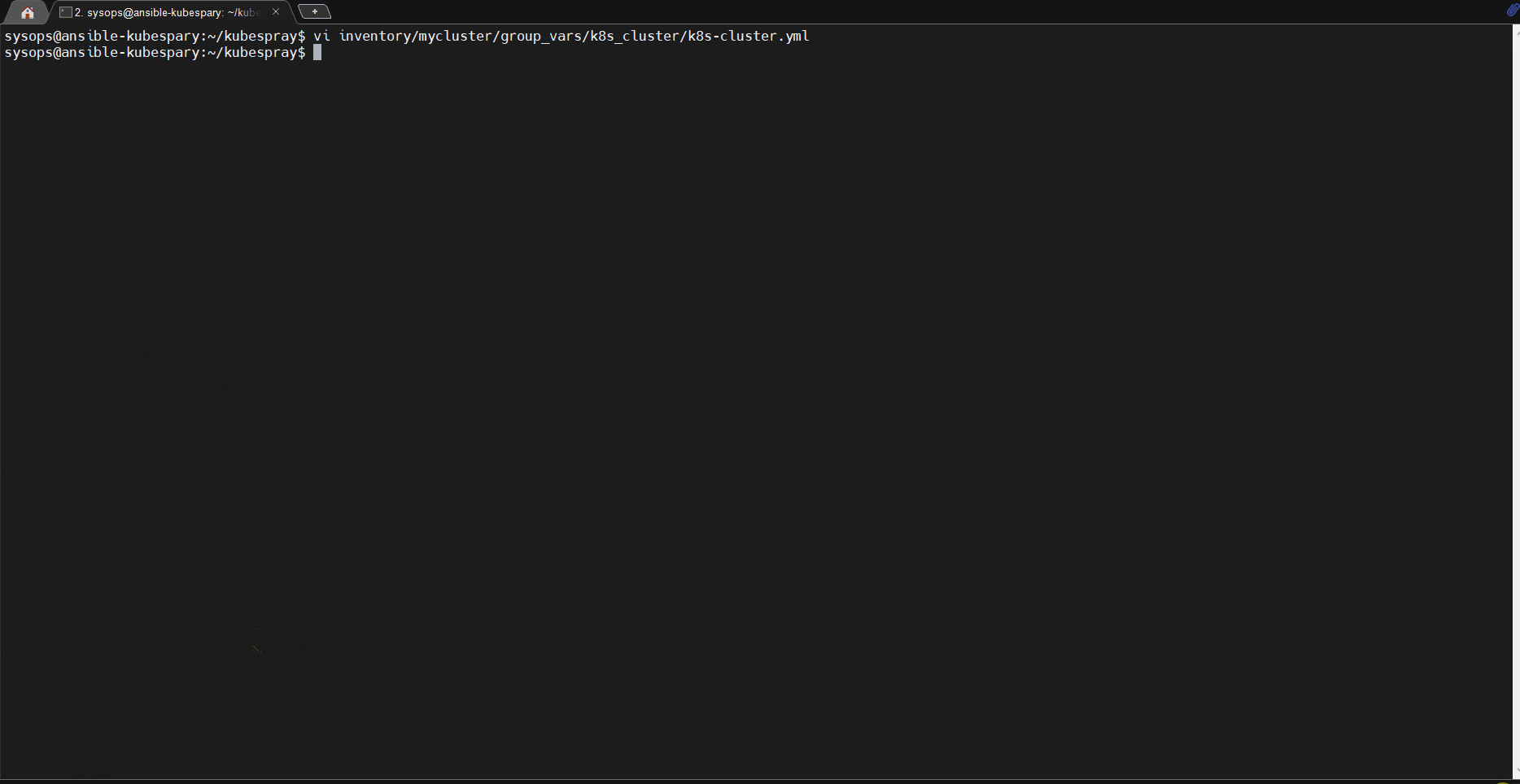
查看并修改文件 inventory/mycluster/group_vars/k8s_cluster/k8s-cluster.yml 中的以下参数:
kube_version: v1.26.2
kube_network_plugin: calico
kube_pods_subnet: 10.233.64.0/18
kube_service_addresses: 10.233.0.0/18
cluster_name: linuxtechi.local
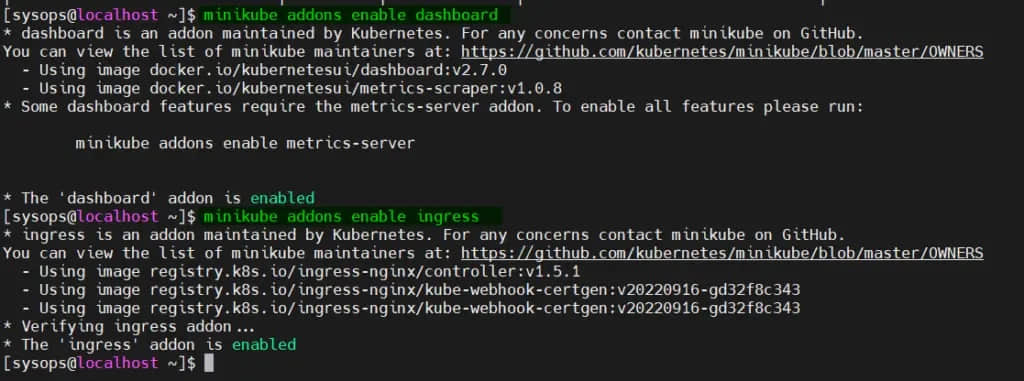
要启用 Kuberenetes 仪表板和入口控制器等插件,请在文件 inventory/mycluster/group_vars/k8s_cluster/addons.yml 中将参数设置为已启用:
$ vi inventory/mycluster/group_vars/k8s_cluster/addons.yml
dashboard_enabled: true
ingress_nginx_enabled: true
ingress_nginx_host_network: true
保存并退出文件。
步骤 2)将 SSH 密钥从 Ansible 节点复制到所有其他节点
首先在你的 Ansible 节点上为你的本地用户生成 SSH 密钥:
$ ssh-keygen
使用 ssh-copy-id 命令复制 SSH 密钥:
$ ssh-copy-id [email protected]
$ ssh-copy-id [email protected]
$ ssh-copy-id [email protected]
$ ssh-copy-id [email protected]
$ ssh-copy-id [email protected]
还要在每个节点上运行以下命令:
$ echo "sysops ALL=(ALL) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/sysops
步骤 3)禁用防火墙并启用 IPV4 转发
要在所有节点上禁用防火墙,请从 Ansible 节点运行以下 ansible 命令:
$ cd kubespray
$ ansible all -i inventory/mycluster/hosts.yaml -m shell -a "sudo systemctl stop firewalld && sudo systemctl disable firewalld"
运行以下 ansible 命令以在所有节点上启用 IPv4 转发和禁用交换:
$ ansible all -i inventory/mycluster/hosts.yaml -m shell -a "echo 'net.ipv4.ip_forward=1' | sudo tee -a /etc/sysctl.conf"
$ ansible all -i inventory/mycluster/hosts.yaml -m shell -a "sudo sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab && sudo swapoff -a"
步骤 4)启动 Kubernetes 部署
现在,我们都准备好开始 Kubernetes 集群部署,从 Ansible 节点运行下面的 Ansible 剧本:
$ cd kubespray
$ ansible-playbook -i inventory/mycluster/hosts.yaml --become --become-user=root cluster.yml
现在监控部署,可能需要 20 到 30 分钟,具体取决于互联网速度和硬件资源。
部署完成后,我们将在屏幕上看到以下输出:
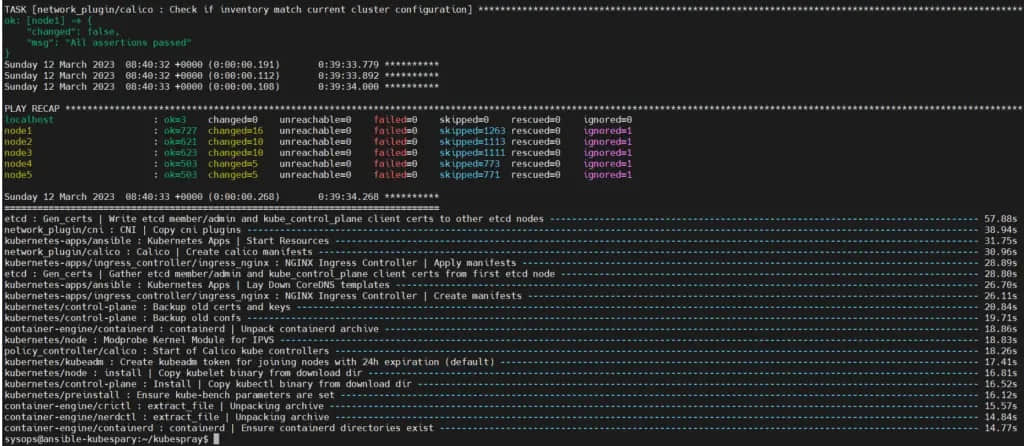
很好,上面的输出确认部署已成功完成。
步骤 5)访问 Kubernetes 集群
登录到第一个主节点,切换到 root 用户,在那里运行 kubectl 命令:
$ sudo su -
# kubectl get nodes
# kubectl get pods -A
输出:
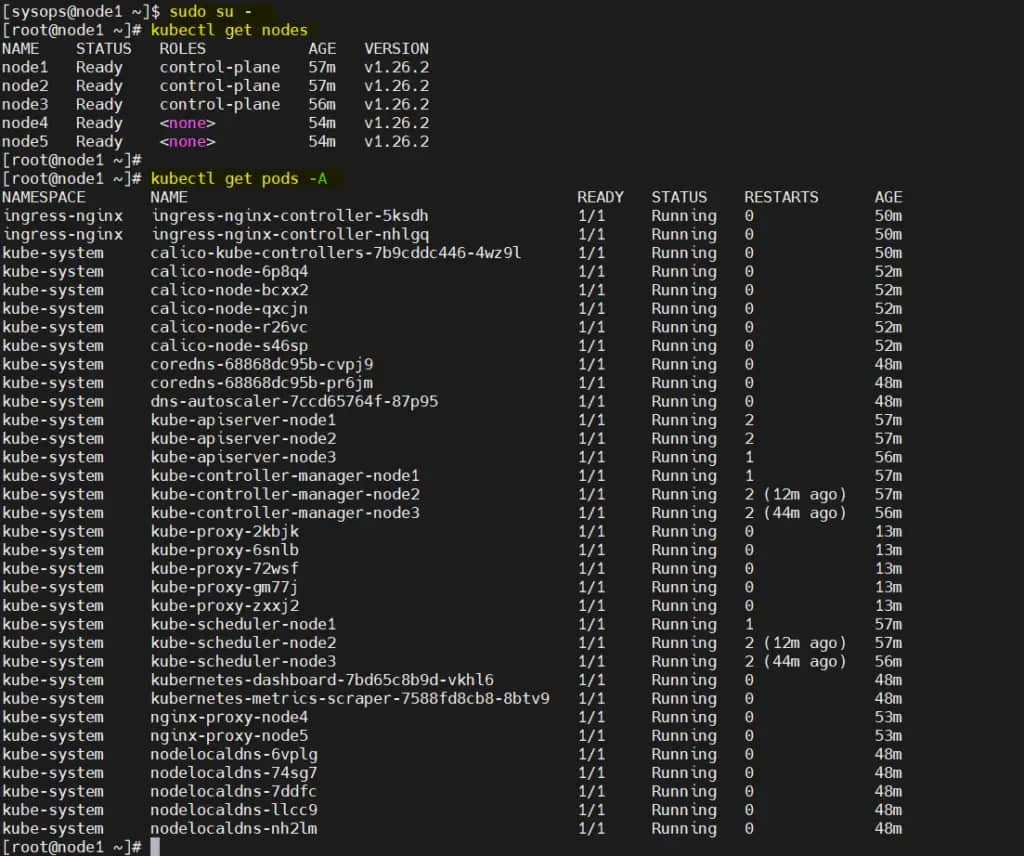
完美,上面的输出确认集群中的所有节点都处于就绪状态,并且所有命名空间的 容器荚 都已启动并正在运行。这表明我们的 Kubernetes 集群部署成功。
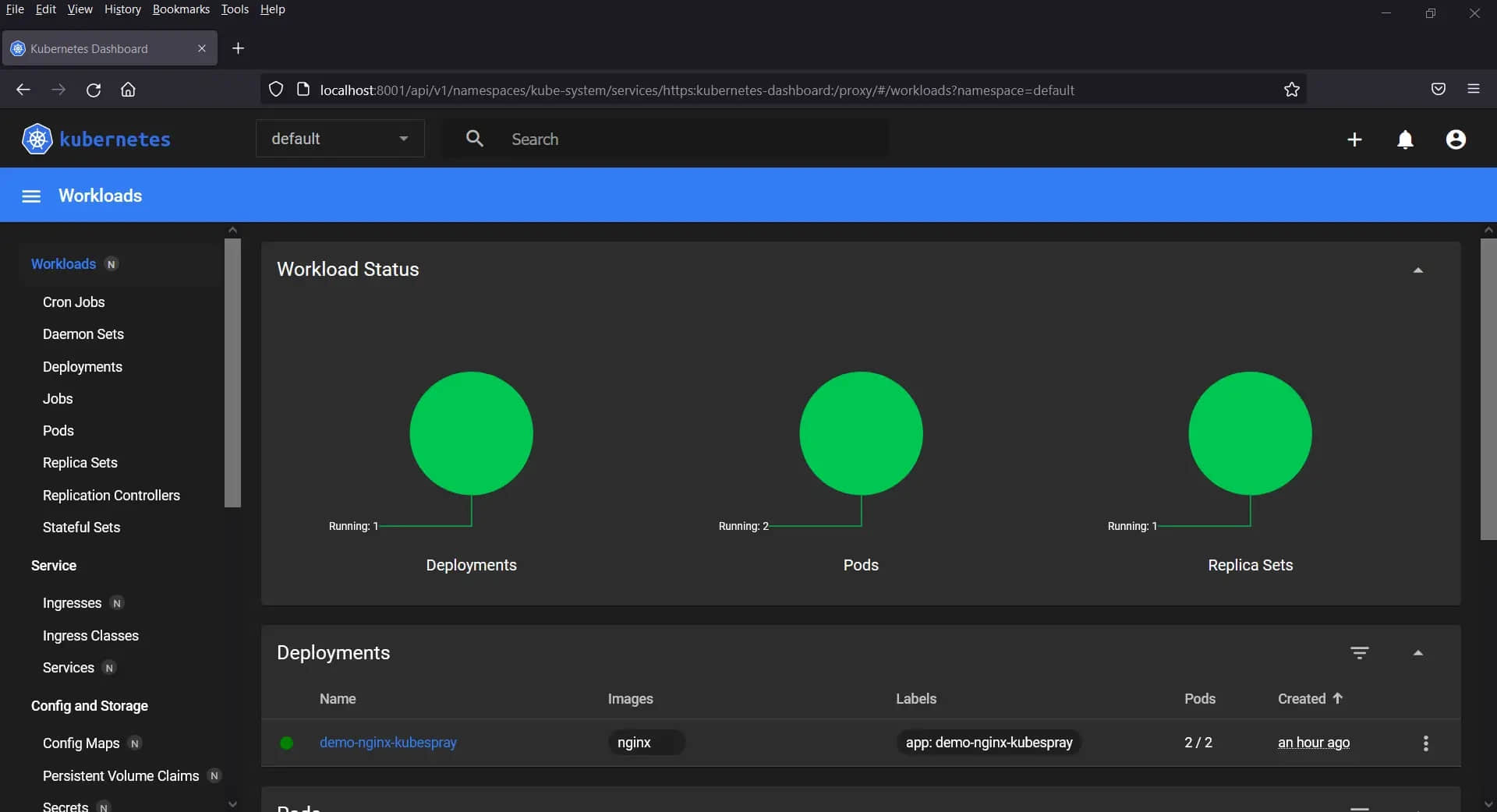
让我们尝试部署基于 Nginx 的部署并将其公开为节点端口,运行以下 kubectl 命令:
$ kubectl create deployment demo-nginx-kubespray --image=nginx --replicas=2
$ kubectl expose deployment demo-nginx-kubespray --type NodePort --port=80
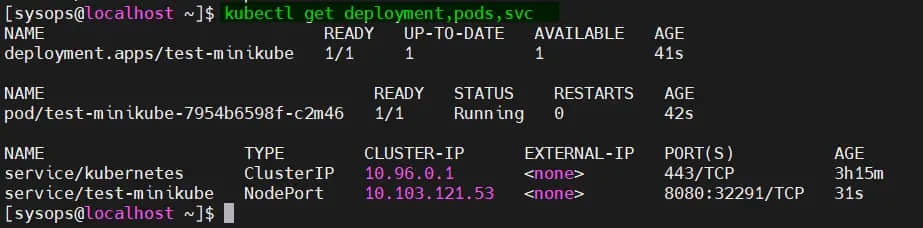
$ kubectl get deployments.apps
$ kubectl get pods
$ kubectl get svc demo-nginx-kubespray
以上命令的输出:
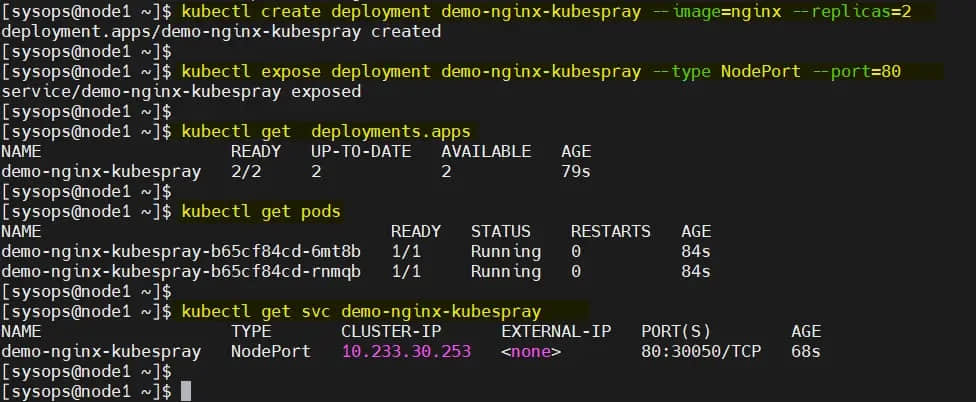
现在尝试使用工作节点的 IP 地址和节点端口(30050)访问此 Nginx 应用。
使用以下 curl 命令或 Web 浏览器访问此应用。
$ curl 192.168.1.245:30050
或者,
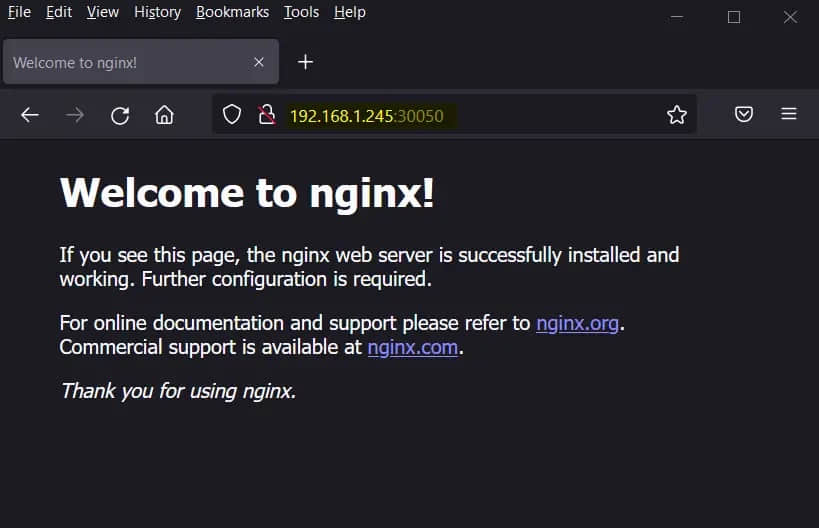
完美,这证实了应用可以在我们的集群之外访问。
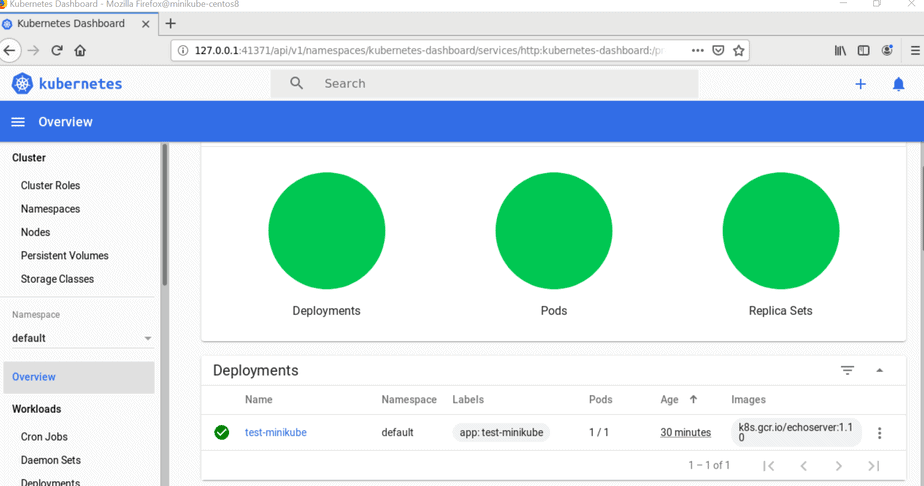
步骤 6)Kubernetes 仪表板(GUI)
要访问 Kubernetes 仪表板,让我们首先创建服务帐户并分配管理员权限,以便它可以使用令牌访问仪表板。
在 kube-system 命名空间中创建名为 “admin-user” 的服务帐户:
$ vi dashboard-adminuser.yml
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kube-system
保存并关闭文件。
$ kubectl apply -f dashboard-adminuser.yml
serviceaccount/admin-user created
创建集群角色绑定:
$ vi admin-role-binding.yml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kube-system
保存并退出文件。
$ kubectl apply -f admin-role-binding.yml
clusterrolebinding.rbac.authorization.k8s.io/admin-user created
现在,为管理员用户创建令牌:
$ kubectl -n kube-system create token admin-user

复制此令牌并将其放在安全的地方,因为我们将使用令牌登录 Kubernetes 仪表板。
使用以下 ssh 命令从你的系统连接到第一个主节点:
$ ssh -L8001:localhost:8001 [email protected]
注意:替换适合你环境的 IP 地址。
登录后,切换到 root 用户并运行 kubectl proxy 命令:
$ sudo su -
# kubectl proxy
Starting to serve on 127.0.0.1:8001

打开系统的网络浏览器,如下设置代理:
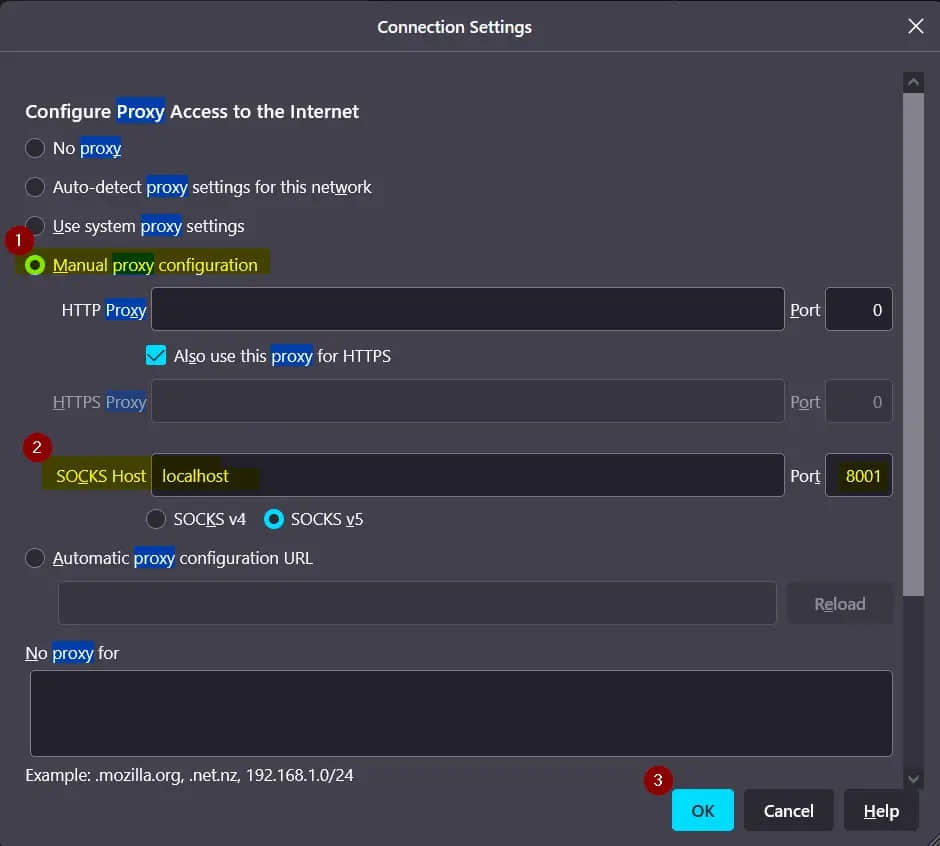
完成代理设置后,将以下网址粘贴到浏览器中:
http://localhost:8001/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy/#/login
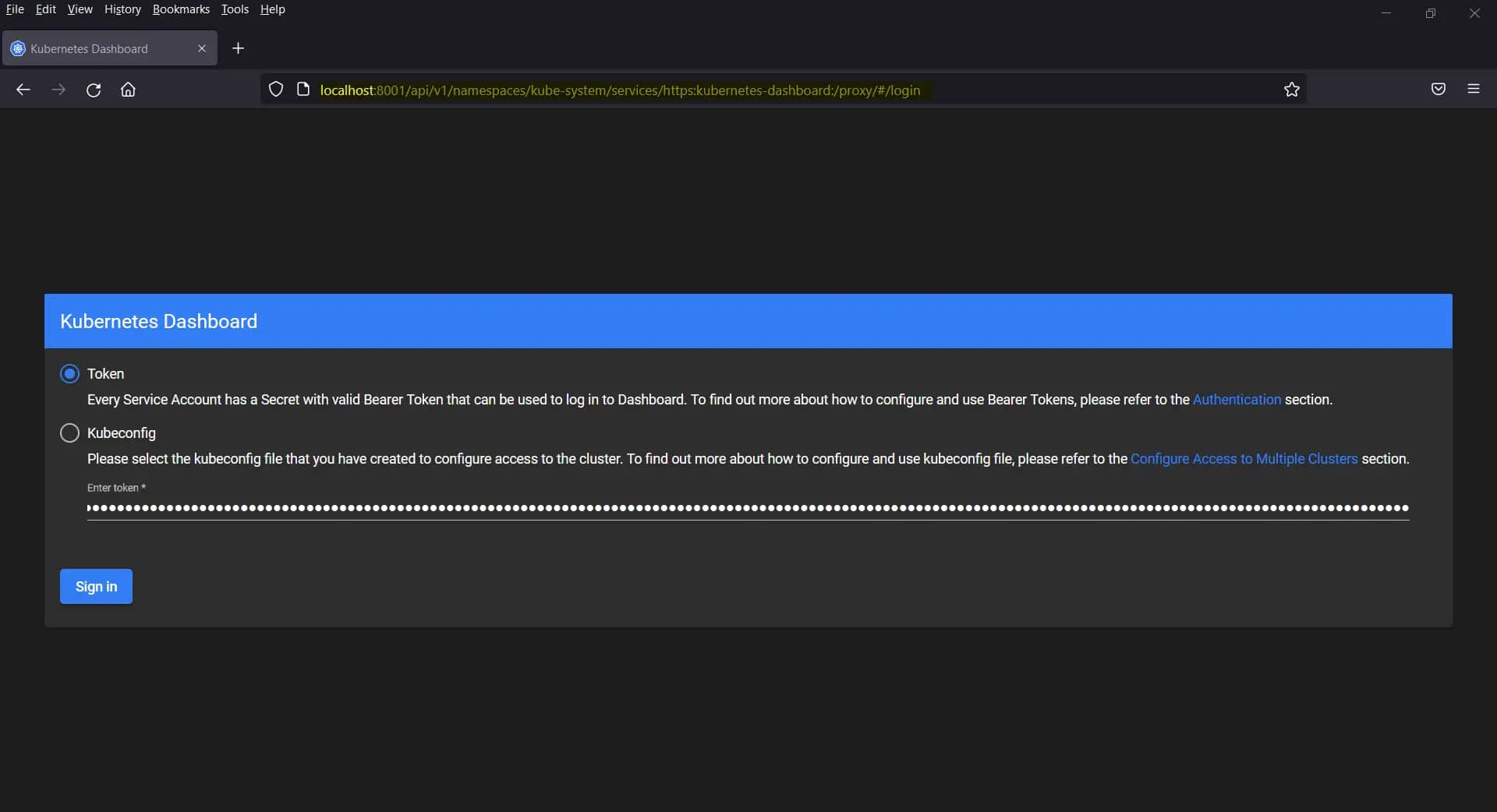
选择令牌登录并粘贴你在上面为管理员用户生成的令牌,然后单击“ 登录 ”。
这就是本指南的全部内容,我希望你能从中找到有用的信息。请在下面的评论部分中发表你的疑问和反馈。
via: https://www.linuxtechi.com/install-kubernetes-using-kubespray/
作者:Pradeep Kumar 选题:lkxed 译者:geekpi 校对:wxy