用 Kubernetes 和 Docker 部署 Java 应用
大规模容器应用编排起步

通过《面向 Java 开发者的 Kubernetes》,学习基本的 Kubernetes 概念和自动部署、维护和扩展你的 Java 应用程序的机制。下载该电子书的免费副本
在 《Java 的容器化持续交付》 中,我们探索了在 Docker 容器内打包和部署 Java 应用程序的基本原理。这只是创建基于容器的生产级系统的第一步。在真实的环境中运行容器还需要一个容器编排和计划的平台,并且,现在已经存在了很多个这样的平台(如,Docker Swarm、Apach Mesos、AWS ECS),而最受欢迎的是 Kubernetes。Kubernetes 被用于很多组织的产品中,并且,它现在由原生云计算基金会(CNCF)所管理。在这篇文章中,我们将使用以前的一个简单的基于 Java 的电子商务商店,我们将它打包进 Docker 容器内,并且在 Kubernetes 上运行它。
“Docker Java Shopfront” 应用程序
我们将打包进容器,并且部署在 Kubernetes 上的 “Docker Java Shopfront” 应用程序的架构,如下面的图所示:
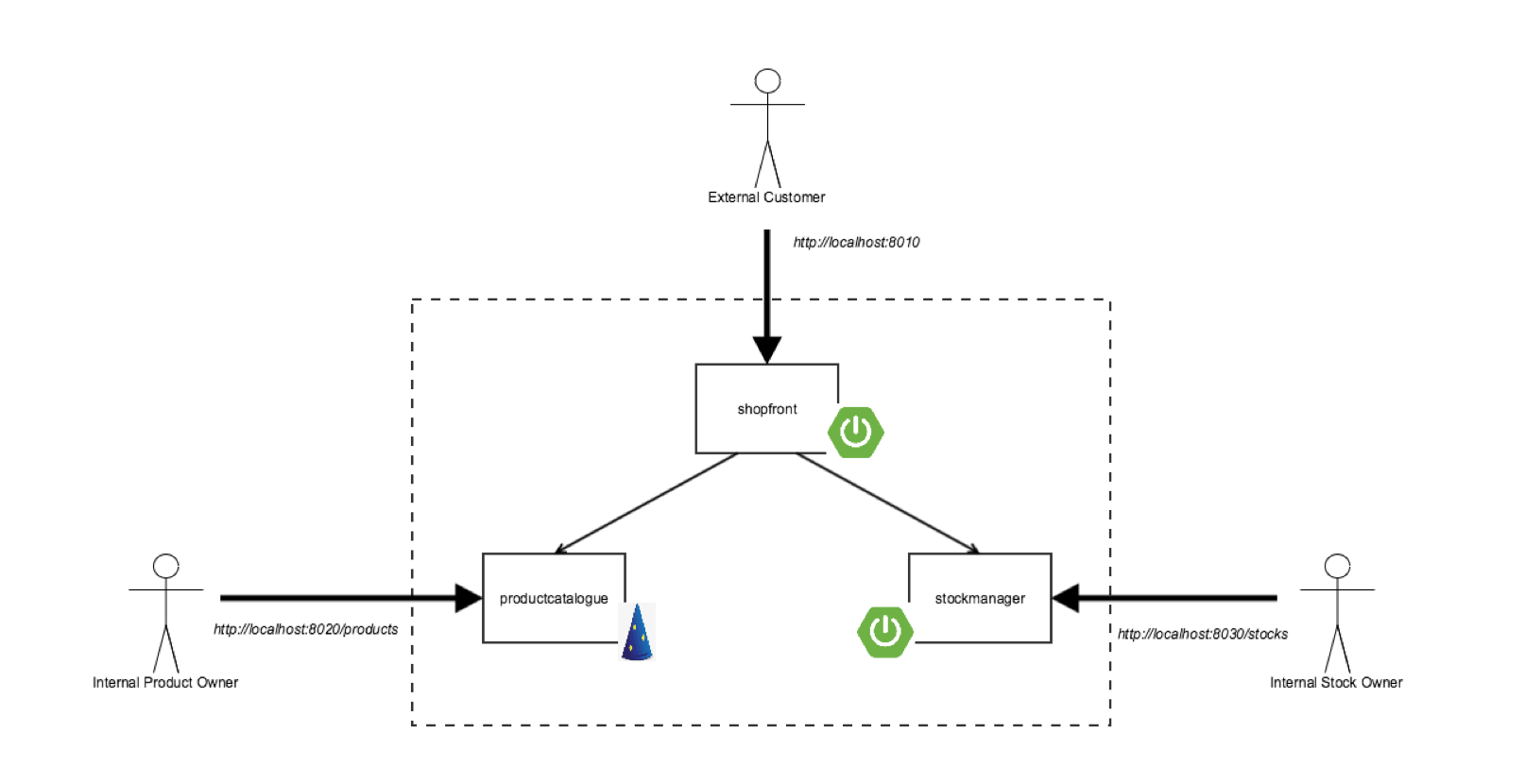
在我们开始去创建一个所需的 Kubernetes 部署配置文件之前,让我们先学习一下关于容器编排平台中的一些核心概念。
Kubernetes 101
Kubernetes 是一个最初由谷歌开发的开源的部署容器化应用程序的 编排器 。谷歌已经运行容器化应用程序很多年了,并且,由此产生了 Borg 容器编排器,它是应用于谷歌内部的,是 Kubernetes 创意的来源。如果你对这个技术不熟悉,一些出现的许多核心概念刚开始你会不理解,但是,实际上它们都很强大。首先, Kubernetes 采用了不可变的基础设施的原则。部署到容器中的内容(比如应用程序)是不可变的,不能通过登录到容器中做成改变。而是要以部署新的版本替代。第二,Kubernetes 内的任何东西都是 声明式 配置。开发者或运维指定系统状态是通过部署描述符和配置文件进行的,并且,Kubernetes 是可以响应这些变化的——你不需要去提供命令,一步一步去进行。
不可变基础设施和声明式配置的这些原则有许多好处:它容易防止配置 偏移 ,或者 “ 雪花 ” 应用程序实例;声明部署配置可以保存在版本控制中,与代码在一起;并且, Kubernetes 大部分都可以自我修复,比如,如果系统经历失败,假如是一个底层的计算节点失败,系统可以重新构建,并且根据在声明配置中指定的状态去重新均衡应用程序。
Kubernetes 提供几个抽象概念和 API,使之可以更容易地去构建这些分布式的应用程序,比如,如下的这些基于微服务架构的:
- 豆荚 —— 这是 Kubernetes 中的最小部署单元,并且,它本质上是一组容器。 豆荚 可以让一个微服务应用程序容器与其它“挎斗” 容器,像日志、监视或通讯管理这样的系统服务一起被分组。在一个豆荚中的容器共享同一个文件系统和网络命名空间。注意,一个单个的容器也是可以被部署的,但是,通常的做法是部署在一个豆荚中。
- 服务 —— Kubernetes 服务提供负载均衡、命名和发现,以将一个微服务与其它隔离。服务是通过复制控制器支持的,它反过来又负责维护在系统内运行期望数量的豆荚实例的相关细节。服务、复制控制器和豆荚在 Kubernetes 中通过使用“标签”连接到一起,并通过它进行命名和选择。
现在让我们来为我们的基于 Java 的微服务应用程序创建一个服务。
构建 Java 应用程序和容器镜像
在我们开始创建一个容器和相关的 Kubernetes 部署配置之前,我们必须首先确认,我们已经安装了下列必需的组件:
- 适用于 Mac / Windows / Linux 的 Docker - 这允许你在本地机器上,在 Kubernetes 之外去构建、运行和测试 Docker 容器。
- Minikube - 这是一个工具,它可以通过虚拟机,在你本地部署的机器上很容易地去运行一个单节点的 Kubernetes 测试集群。
- 一个 GitHub 帐户和本地安装的 Git - 示例代码保存在 GitHub 上,并且通过使用本地的 Git,你可以复刻该仓库,并且去提交改变到该应用程序的你自己的副本中。
- Docker Hub 帐户 - 如果你想跟着这篇教程进行,你将需要一个 Docker Hub 帐户,以便推送和保存你将在后面创建的容器镜像的拷贝。
- Java 8 (或 9) SDK 和 Maven - 我们将使用 Maven 和附属的工具使用 Java 8 特性去构建代码。
从 GitHub 克隆项目库代码(可选,你可以 复刻 这个库,并且克隆一个你个人的拷贝),找到 “shopfront” 微服务应用: https://github.com/danielbryantuk/oreilly-docker-java-shopping/。
$ git clone [email protected]:danielbryantuk/oreilly-docker-java-shopping.git
$ cd oreilly-docker-java-shopping/shopfront
请加载 shopfront 代码到你选择的编辑器中,比如,IntelliJ IDE 或 Eclipse,并去研究它。让我们使用 Maven 来构建应用程序。最终生成包含该应用的可运行的 JAR 文件位于 ./target 的目录中。
$ mvn clean install
…
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 17.210 s
[INFO] Finished at: 2017-09-30T11:28:37+01:00
[INFO] Final Memory: 41M/328M
[INFO] ------------------------------------------------------------------------
现在,我们将构建 Docker 容器镜像。一个容器镜像的操作系统选择、配置和构建步骤,一般情况下是通过一个 Dockerfile 指定的。我们看一下,我们的示例中位于 shopfront 目录中的 Dockerfile:
FROM openjdk:8-jre
ADD target/shopfront-0.0.1-SNAPSHOT.jar app.jar
EXPOSE 8010
ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"]
第一行指定了,我们的容器镜像将被 “ 从 ” 这个 openjdk:8-jre 基础镜像中创建。openjdk:8-jre 镜像是由 OpenJDK 团队维护的,并且包含了我们在 Docker 容器(就像一个安装和配置了 OpenJDK 8 JDK的操作系统)中运行 Java 8 应用程序所需要的一切东西。第二行是,将我们上面构建的可运行的 JAR “ 添加 ” 到这个镜像。第三行指定了端口号是 8010,我们的应用程序将在这个端口号上监听,如果外部需要可以访问,必须要 “ 暴露 ” 它,第四行指定 “ 入口 ” ,即当容器初始化后去运行的命令。现在,我们来构建我们的容器:
$ docker build -t danielbryantuk/djshopfront:1.0 .
Successfully built 87b8c5aa5260
Successfully tagged danielbryantuk/djshopfront:1.0
现在,我们推送它到 Docker Hub。如果你没有通过命令行登入到 Docker Hub,现在去登入,输入你的用户名和密码:
$ docker login
Login with your Docker ID to push and pull images from Docker Hub. If you don't have a Docker ID, head over to https://hub.docker.com to create one.
Username:
Password:
Login Succeeded
$
$ docker push danielbryantuk/djshopfront:1.0
The push refers to a repository [docker.io/danielbryantuk/djshopfront]
9b19f75e8748: Pushed
...
cf4ecb492384: Pushed
1.0: digest: sha256:8a6b459b0210409e67bee29d25bb512344045bd84a262ede80777edfcff3d9a0 size: 2210
部署到 Kubernetes 上
现在,让我们在 Kubernetes 中运行这个容器。首先,切换到项目根目录的 kubernetes 目录:
$ cd ../kubernetes
打开 Kubernetes 部署文件 shopfront-service.yaml,并查看内容:
---
apiVersion: v1
kind: Service
metadata:
name: shopfront
labels:
app: shopfront
spec:
type: NodePort
selector:
app: shopfront
ports:
- protocol: TCP
port: 8010
name: http
---
apiVersion: v1
kind: ReplicationController
metadata:
name: shopfront
spec:
replicas: 1
template:
metadata:
labels:
app: shopfront
spec:
containers:
- name: shopfront
image: danielbryantuk/djshopfront:latest
ports:
- containerPort: 8010
livenessProbe:
httpGet:
path: /health
port: 8010
initialDelaySeconds: 30
timeoutSeconds: 1
这个 yaml 文件的第一节创建了一个名为 “shopfront” 的服务,它将到该服务(8010 端口)的 TCP 流量路由到标签为 “app: shopfront” 的豆荚中 。配置文件的第二节创建了一个 ReplicationController ,其通知 Kubernetes 去运行我们的 shopfront 容器的一个复制品(实例),它是我们标为 “app: shopfront” 的声明(spec)的一部分。我们也指定了暴露在我们的容器上的 8010 应用程序端口,并且声明了 “livenessProbe” (即健康检查),Kubernetes 可以用于去决定我们的容器应用程序是否正确运行并准备好接受流量。让我们来启动 minikube 并部署这个服务(注意,根据你部署的机器上的可用资源,你可能需要去修 minikube 中的指定使用的 CPU 和 内存 ):
$ minikube start --cpus 2 --memory 4096
Starting local Kubernetes v1.7.5 cluster...
Starting VM...
Getting VM IP address...
Moving files into cluster...
Setting up certs...
Connecting to cluster...
Setting up kubeconfig...
Starting cluster components...
Kubectl is now configured to use the cluster.
$ kubectl apply -f shopfront-service.yaml
service "shopfront" created
replicationcontroller "shopfront" created
你可以通过使用 kubectl get svc 命令查看 Kubernetes 中所有的服务。你也可以使用 kubectl get pods 命令去查看所有相关的豆荚(注意,你第一次执行 get pods 命令时,容器可能还没有创建完成,并被标记为未准备好):
$ kubectl get svc
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes 10.0.0.1 <none> 443/TCP 18h
shopfront 10.0.0.216 <nodes> 8010:31208/TCP 12s
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
shopfront-0w1js 0/1 ContainerCreating 0 18s
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
shopfront-0w1js 1/1 Running 0 2m
我们现在已经成功地在 Kubernetes 中部署完成了我们的第一个服务。
是时候进行烟雾测试了
现在,让我们使用 curl 去看一下,我们是否可以从 shopfront 应用程序的健康检查端点中取得数据:
$ curl $(minikube service shopfront --url)/health
{"status":"UP"}
你可以从 curl 的结果中看到,应用的 health 端点是启用的,并且是运行中的,但是,在应用程序按我们预期那样运行之前,我们需要去部署剩下的微服务应用程序容器。
构建剩下的应用程序
现在,我们有一个容器已经运行,让我们来构建剩下的两个微服务应用程序和容器:
$ cd ..
$ cd productcatalogue/
$ mvn clean install
…
$ docker build -t danielbryantuk/djproductcatalogue:1.0 .
...
$ docker push danielbryantuk/djproductcatalogue:1.0
...
$ cd ..
$ cd stockmanager/
$ mvn clean install
...
$ docker build -t danielbryantuk/djstockmanager:1.0 .
...
$ docker push danielbryantuk/djstockmanager:1.0
...
这个时候, 我们已经构建了所有我们的微服务和相关的 Docker 镜像,也推送镜像到 Docker Hub 上。现在,我们去在 Kubernetes 中部署 productcatalogue 和 stockmanager 服务。
在 Kubernetes 中部署整个 Java 应用程序
与我们上面部署 shopfront 服务时类似的方式去处理它,我们现在可以在 Kubernetes 中部署剩下的两个微服务:
$ cd ..
$ cd kubernetes/
$ kubectl apply -f productcatalogue-service.yaml
service "productcatalogue" created
replicationcontroller "productcatalogue" created
$ kubectl apply -f stockmanager-service.yaml
service "stockmanager" created
replicationcontroller "stockmanager" created
$ kubectl get svc
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes 10.0.0.1 <none> 443/TCP 19h
productcatalogue 10.0.0.37 <nodes> 8020:31803/TCP 42s
shopfront 10.0.0.216 <nodes> 8010:31208/TCP 13m
stockmanager 10.0.0.149 <nodes> 8030:30723/TCP 16s
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
productcatalogue-79qn4 1/1 Running 0 55s
shopfront-0w1js 1/1 Running 0 13m
stockmanager-lmgj9 1/1 Running 0 29s
取决于你执行 “kubectl get pods” 命令的速度,你或许会看到所有都处于不再运行状态的豆荚。在转到这篇文章的下一节之前,我们要等着这个命令展示出所有豆荚都运行起来(或许,这个时候应该来杯咖啡!)
查看完整的应用程序
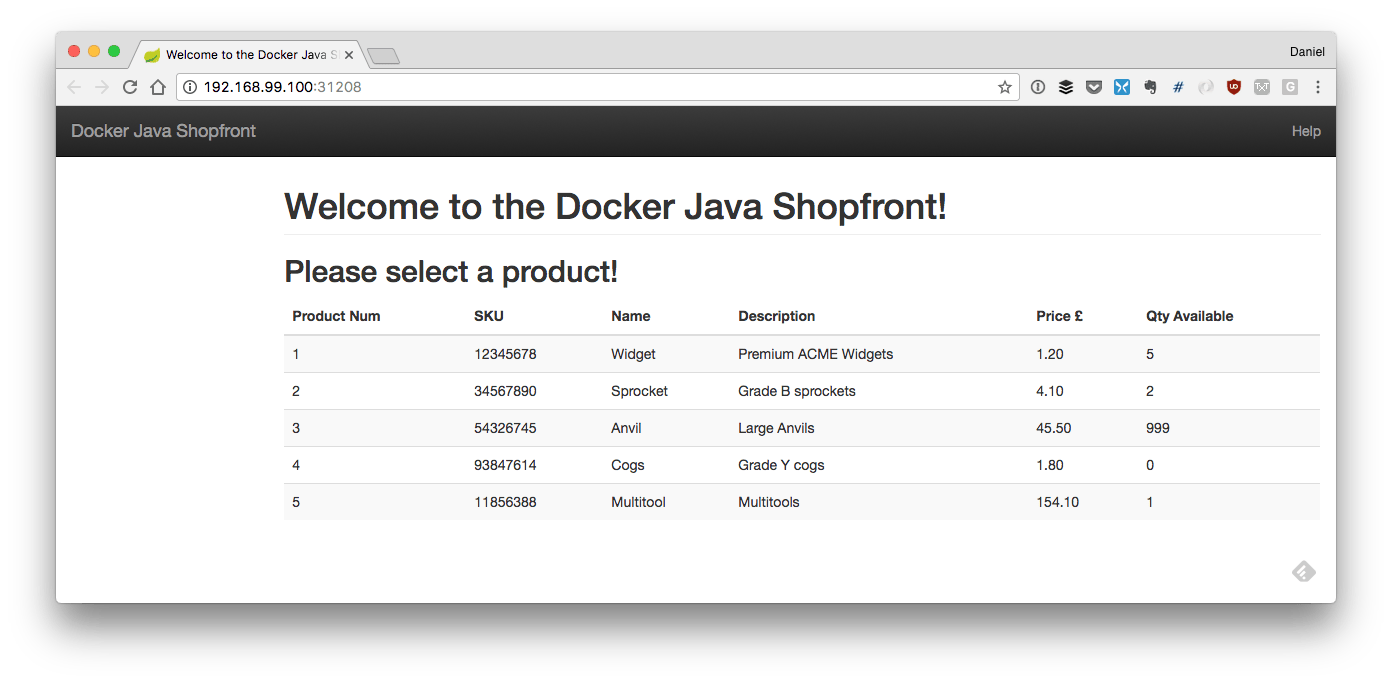
在所有的微服务部署完成并且所有相关的豆荚都正常运行后,我们现在将去通过 shopfront 服务的 GUI 去访问我们完整的应用程序。我们可以通过执行 minikube 命令在默认浏览器中打开这个服务:
$ minikube service shopfront
如果一切正常,你将在浏览器中看到如下的页面:
结论
在这篇文章中,我们已经完成了由三个 Java Spring Boot 和 Dropwizard 微服务组成的应用程序,并且将它部署到 Kubernetes 上。未来,我们需要考虑的事还很多,比如,调试服务(或许是通过工具,像 Telepresence 和 Sysdig),通过一个像 Jenkins 或 Spinnaker 这样的可持续交付的过程去测试和部署,并且观察我们的系统运行。
本文是与 NGINX 协作创建的。 查看我们的编辑独立性声明.
作者简介:
Daniel Bryant 是一名独立技术顾问,他是 SpectoLabs 的 CTO。他目前关注于通过识别价值流、创建构建过程、和实施有效的测试策略,从而在组织内部实现持续交付。Daniel 擅长并关注于“DevOps”工具、云/容器平台和微服务实现。他也贡献了几个开源项目,并定期为 InfoQ、 O’Reilly、和 Voxxed 撰稿...
via: https://www.oreilly.com/ideas/how-to-manage-docker-containers-in-kubernetes-with-java
作者:Daniel Bryant 译者:qhwdw 校对:wxy









