GitLab 是一个基于 git 的仓库管理程序,也是一个方便软件开发的强大完整应用。
GitLab 拥有一个“用户新人友好”的界面,通过图形界面和命令行界面,使你的工作更加具有效率。GitLab 不仅仅对开发者是一个有用的工具,它甚至可以被集成到你的整个团队中,使得每一个人获得一个独自唯一的平台。
GitLab 工作流逻辑符合使用者思维,使得整个平台变得更加易用。相信我,使用一次,你就离不开它了!

GitLab 工作流
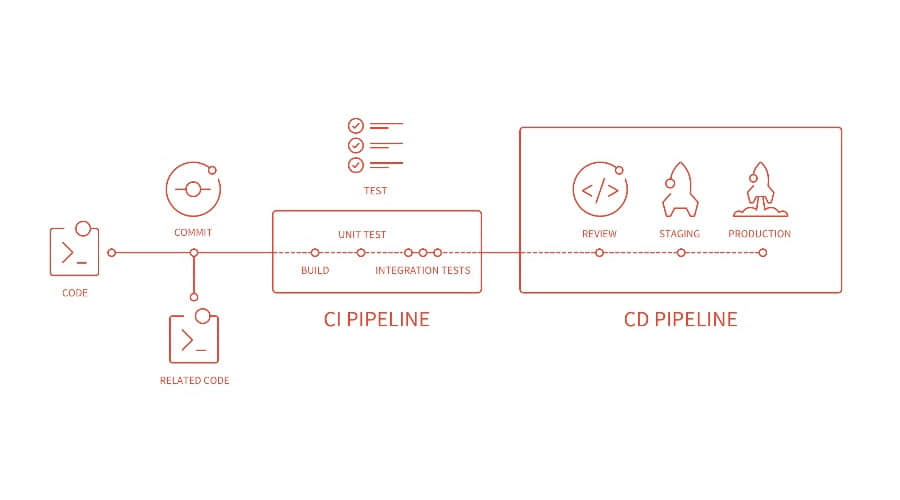
GitLab 工作流 是在软件开发过程中,在使用 GitLab 作为代码托管平台时,可以采取的动作的一个逻辑序列。
GitLab 工作流遵循了 GitLab Flow 策略,这是由一系列由基于 Git 的方法和策略组成的,这些方法为版本的管理,例如分支策略、Git最佳实践等等提供了保障。
通过 GitLab 工作流,可以很方便的提升团队的工作效率以及凝聚力。这种提升,从引入一个新的项目开始,一直到发布这个项目,成为一个产品都有所体现。这就是我们所说的“如何通过最快的速度把一个点子在 10 步之内变成一个产品”。

软件开发阶段
一般情况下,软件开发经过 10 个主要阶段;GitLab 为这 10 个阶段依次提供了解决方案:
- IDEA: 每一个从点子开始的项目,通常来源于一次闲聊。在这个阶段,GitLab 集成了 Mattermost。
- ISSUE: 最有效的讨论一个点子的方法,就是为这个点子建立一个工单讨论。你的团队和你的合作伙伴可以在 工单追踪器 中帮助你去提升这个点子
- PLAN: 一旦讨论得到一致的同意,就是开始编码的时候了。但是等等!首先,我们需要优先考虑组织我们的工作流。对于此,我们可以使用 工单看板 。
- CODE: 现在,当一切准备就绪,我们可以开始写代码了。
- COMMIT: 当我们为我们的初步成果欢呼的时候,我们就可以在版本控制下,提交代码到功能分支了。
- TEST: 通过 GitLab CI,我们可以运行脚本来构建和测试我们的应用。
- REVIEW: 一旦脚本成功运行,我们测试和构建成功,我们就可以进行 代码复审 以及批准。
- STAGING:: 现在是时候将我们的代码部署到演示环境来检查一下,看看是否一切就像我们预估的那样顺畅——或者我们可能仍然需要修改。
- PRODUCTION: 当一切都如预期,就是部署到生产环境的时候了!
- FEEDBACK: 现在是时候返回去看我们项目中需要提升的部分了。我们使用 周期分析 来对当前项目中关键的部分进行的反馈。
简单浏览这些步骤,我们可以发现,提供强大的工具来支持这些步骤是十分重要的。在接下来的部分,我们为 GitLab 的可用工具提供一个简单的概览。
GitLab 工单追踪器
GitLab 有一个强大的工单追溯系统,在使用过程中,允许你和你的团队,以及你的合作者分享和讨论建议。

工单是 GitLab 工作流的第一个重要重要特性。以工单的讨论为开始; 跟踪新点子的改变是一个最好的方式。
这十分有利于:
- 讨论点子
- 提交功能建议
- 提问题
- 提交错误和故障
- 获取支持
- 精细化新代码的引入
每一个在 GitLab 上部署的项目都有一个工单追踪器。找到你的项目中的 Issues > New issue 来创建一个新的工单。建立一个标题来总结要被讨论的主题,并且使用 Markdown 来形容它。看看下面的“专业技巧”来加强你的工单描述。
GitLab 工单追踪器提供了一个额外的实用功能,使得步骤变得更佳易于管理和考虑。下面的部分仔细描述了它。

秘密工单
无论何时,如果你仅仅想要在团队中讨论这个工单,你可以使该工单成为秘密的。即使你的项目是公开的,你的工单也会被保密起来。当一个不是本项目成员的人,就算是 报告人级别,想要访问工单的地址时,浏览器也会返回一个 404 错误。
截止日期
每一个工单允许你填写一个截止日期。有些团队工作时间表安排紧凑,以某种方式去设置一个截止日期来解决问题,是有必要的。这些都可以通过截止日期这一功能实现。
当你对一个多任务项目有截止日期的时候——比如说,一个新的发布活动、项目的启动,或者按阶段追踪任务——你可以使用里程碑。
受托者
要让某人处理某个工单,可以将其分配给他。你可以任意修改被分配者,直到满足你的需求。这个功能的想法是,一个受托者本身对这个工单负责,直到其将这个工单重新赋予其他人。
这也可以用于按受托者筛选工单。
标签
GitLab 标签也是 GitLab 流的一个重要组成部分。你可以使用它们来分类你的工单,在工作流中定位,以及通过优先级标签来安装优先级组织它们。
标签使得你与GitLab 工单看板协同工作,加快工程进度以及组织你的工作流。
新功能: 你可以创建组标签。它可以使得在每一个项目组中使用相同的标签。
工单权重
你可以添加个工单权重使得一个工单重要性表现的更为清晰。01 - 03 表示工单不是特别重要,07 - 09 表示十分重要,04 - 06 表示程度适中。此外,你可以与你的团队自行定义工单重要性的指标。
注:该功能仅可用于 GitLab 企业版和 GitLab.com 上。
GitLab 工单看板
在项目中,GitLab 工单看板是一个用于计划以及组织你的工单,使之符合你的项目工作流的工具。
看板包含了与其相关的相应标签,每一个列表包含了相关的被标记的工单,并且以卡片的形式展示出来。
这些卡片可以在列表之间移动,被移动的卡片,其标签将会依据你移动的位置相应更新到列表上。

新功能: 你也可以通过点击列表上方的“+”按钮在看板右边创建工单。当你这么做的时候,这个工单将会自动添加与列表相关的标签。
新功能: 我们最近推出了 每一个 GitLab 项目拥有多个工单看板的功能(仅存在于 GitLab 企业版);这是为不同的工作流组织你的工单的好方法。

通过 GitLab 进行代码复审
在工单追踪器中,讨论了新的提议之后,就是在代码上做工作的时候了。你在本地书写代码,一旦你完成了你的第一个版本,提交你的代码并且推送到你的 GitLab 仓库。你基于 Git 的管理策略可以在 GitLab 流中被提升。
第一次提交
在你的第一次提交信息中,你可以添加涉及到工单号在其中。通过这样做你可以将两个阶段的开发工作流链接起来:工单本身以及关于这个工单的第一次提交。
这样做,如果你提交的代码和工单属于同一个项目,你可以简单的添加 #xxx 到提交信息中(LCTT 译注:git commit message),xxx是一个工单号。如果它们不在一个项目中,你可以添加整个工单的整个URL(https://gitlab.com/<username>/<projectname>/issues/<xxx>)。
git commit -m "this is my commit message. Ref #xxx"
或者
git commit -m "this is my commit message. Related to https://gitlab.com/<username>/<projectname>/issues/<xxx>"
当然,你也可以替换 gitlab.com,以你自己的 GitLab 实例来替换这个 URL。
注: 链接工单和你的第一次提交是为了通过 GitLab 周期分析追踪你的进展。这将会衡量计划执行该工单所采取的时间,即创建工单与第一次提交的间隔时间。
合并请求
一旦将你的改动提交到功能分支,GitLab 将识别该修改,并且建议你提交一次 合并请求 (MR)。
每一次 MR 都会有一个标题(这个标题总结了这次的改动)并且一个用 Markdown 书写的描述。在描述中,你可以简单的描述该 MR 做了什么,提及任何工单以及 MR(在它们之间创建联系),并且,你也可以添加个关闭工单模式,当该 MR 被合并的时候,相关联的工单就会被关闭。
例如:
## 增加一个新页面
这个 MR 将会为这个项目创建一个包含该 app 概览的 `readme.md`。
Closes #xxx and https://gitlab.com/<username>/<projectname>/issues/<xxx>
预览:

cc/ @Mary @Jane @John
当你创建一个如上的带有描述的 MR,它将会:
- 当合并时,关闭包括工单
#xxx 以及 https://gitlab.com/<username>/<projectname>/issues/<xxx> - 展示一张图片
- 通过邮件提醒用户
@Mary、@Jane,以及给 @John
你可以分配这个 MR 给你自己,直到你完成你的工作,然后把它分配给其他人来做一次代码复审。如果有必要的话,这个 MR 可以被重新分配多次,直到你覆盖你所需要的所有复审。
它也可以被标记,并且添加一个里程碑来促进管理。
当你从图形界面而不是命令行添加或者修改一个文件并且提交一个新的分支时,也很容易创建一个新的 MR,仅仅需要标记一下复选框,“以这些改变开始一个新的合并请求”,然后,一旦你提交你的改动,GitLab 将会自动创建一个新的 MR。

注: 添加关闭工单样式到你的 MR 以便可以使用 GitLab 周期分析追踪你的项目进展,是十分重要的。它将会追踪“CODE”阶段,衡量第一次提交及创建一个相关的合并请求所间隔的时间。
新功能: 我们已经开发了审查应用,这是一个可以让你部署你的应用到一个动态的环境中的新功能,在此你可以按分支名字、每个合并请求来预览改变。参看这里的可用示例。
WIP MR
WIP MR 含义是 在工作过程中的合并请求,是一个我们在 GitLab 中避免 MR 在准备就绪前被合并的技术。只需要添加 WIP: 在 MR 的标题开头,它将不会被合并,除非你把 WIP: 删除。
当你改动已经准备好被合并,编辑工单来手动删除 WIP: ,或者使用就像如下 MR 描述下方的快捷方式。

新功能: WIP 模式可以通过斜线命令 /wip 快速添加到合并请求中。只需要在评论或者 MR 描述中输入它并提交即可。
复审
一旦你创建一个合并请求,就是你开始从你的团队以及合作方收取反馈的时候了。使用图形界面中的差异比较功能,你可以简单的添加行内注释,以及回复或者解决它们。
你也可以通过点击行号获取每一行代码的链接。
在图形界面中可以看到提交历史,通过提交历史,你可以追踪文件的每一次改变。你可以以行内差异或左右对比的方式浏览它们。

新功能: 如果你遇到合并冲突,可以快速地通过图形界面来解决,或者依据你的需要修改文件来修复冲突。

构建、测试以及发布
GitLab CI 是一个强大的内建工具,其作用是持续集成、持续发布以及持续分发,它可以按照你希望的运行一些脚本。它的可能性是无止尽的:你可以把它看做是自己运行的命令行。
它完全是通过一个名为 .gitlab-ci.yml 的 YAML 文件设置的,其放置在你的项目仓库中。使用 Web 界面简单的添加一个文件,命名为 .gitlab-ci.yml 来触发一个下拉菜单,为不同的应用选择各种 CI 模版。

Koding
Use GitLab's Koding integration to run your entire development environment in the cloud. This means that you can check out a project or just a merge request in a full-fledged IDE with the press of a button.
可以使用 GitLab 的 Koding 集成功能在云端运行你的整个云端开发环境。这意味着你可以轻轻一键即可在一个完整的 IDE 中检出以个项目,或者合并一个请求。
使用案例
GitLab CI 的使用案例:
我们已经准备一大堆 GitLab CI 样例工程作为您的指南。看看它们吧!
反馈:周期分析
当你遵循 GitLab 工作流进行工作,你的团队从点子到产品,在每一个过程的关键部分,你将会在下列时间获得一个 GitLab 周期分析的反馈:
- Issue: 从创建一个工单,到分配这个工单给一个里程碑或者添加工单到你的工单看板的时间。
- Plan: 从给工单分配一个里程碑或者把它添加到工单看板,到推送第一次提交的时间。
- Code: 从第一次提交到提出该合并请求的时间。
- Test: CI 为了相关合并请求而运行整个过程的时间。
- Review: 从创建一个合并请求到合并它的时间。
- Staging: 从合并到发布成为产品的时间。
- Production(Total): 从创建工单到把代码发布成产品的时间。
加强
工单以及合并请求模版
工单以及合并请求模版允许你为你的项目去定义一个特定内容的工单模版和合并请求的描述字段。
你可以以 Markdown 形式书写它们,并且把它们加入仓库的默认分支。当创建工单或者合并请求时,可以通过下拉菜单访问它们。
它们节省了您在描述工单和合并请求的时间,并标准化了需要持续跟踪的重要信息。它确保了你需要的一切都在你的掌控之中。
你可以创建许多模版,用于不同的用途。例如,你可以有一个提供功能建议的工单模版,或者一个 bug 汇报的工单模版。在 GitLab CE project 中寻找真实的例子吧!

里程碑
里程碑 是 GitLab 中基于共同的目标、详细的日期追踪你队伍工作的最好工具。
不同情况下的目的是不同的,但是大致是相同的:你有为了达到特定的目标的工单的集合以及正在编码的合并请求。
这个目标基本上可以是任何东西——用来结合团队的工作,在一个截止日期前完成一些事情。例如,发布一个新的版本,启动一个新的产品,在某个日期前完成,或者按季度收尾一些项目。

专业技巧
工单和 MR
在工单和 MR 的描述中:
- 输入
# 来触发一个已有工单的下拉列表 - 输入
! 来触发一个已有 MR 的下拉列表 - 输入
/ 来触发斜线命令 - 输入
: 来出发 emoji 表情 (也支持行中评论)
- 通过按钮“附加文件”来添加图片(jpg、png、gif) 和视频到行内评论
- 通过 GitLab Webhooks 自动应用标签
- 构成引用: 使用语法
>>> 来开始或者结束一个引用
>>>
Quoted text
Another paragraph
>>>
- [ ] Task 1
- [ ] Task 2
- [ ] Task 3
订阅
你是否发现你有一个工单或者 MR 想要追踪?展开你的右边的导航,点击订阅,你就可以在随时收到一个评论的提醒。要是你想要一次订阅多个工单和 MR?使用批量订阅。
添加代办
除了一直留意工单和 MR,如果你想要对它预先做点什么,或者不管什么时候你想要在 GitLab 代办列表中添加点什么,点击你右边的导航,并且点击添加代办。
寻找你的工单和 MR
当你寻找一个在很久以前由你开启的工单或 MR——它们可能数以十计、百计、甚至千计——所以你很难找到它们。打开你左边的导航,并且点击工单或者合并请求,你就会看到那些分配给你的。同时,在那里或者任何工单追踪器里,你可以通过作者、分配者、里程碑、标签以及重要性来过滤工单,也可以通过搜索所有不同状态的工单,例如开启的、合并的,关闭的等等。
移动工单
一个工单在一个错误的项目中结束了?不用担心,点击Edit,然后移动工单到正确的项目。
代码片段
你经常在不同的项目以及文件中使用一些相同的代码段和模版吗?创建一个代码段并且使它在你需要的时候可用。打开左边导航栏,点击Snipptes。所有你的片段都会在那里。你可以把它们设置成公开的,内部的(仅为 GitLab 注册用户提供),或者私有的。

GitLab 工作流用户案例概要
作为总结,让我们把所有东西聚在一起理顺一下。不必担心,这十分简单。
让我们假设:你工作于一个专注于软件开发的公司。你创建了一个新的工单,这个工单是为了开发一个新功能,实施于你的一个应用中。
标签策略
为了这个应用,你已经创建了几个标签,“讨论”、“后端”、“前端”、“正在进行”、“展示”、“就绪”、“文档”、“营销”以及“产品”。所有都已经在工单看板有它们自己的列表。你的当前的工单已经有了标签“讨论”。
在工单追踪器中的讨论达成一致之后,你的后端团队开始在工单上工作,所以他们把这个工单的标签从“讨论”移动到“后端”。第一个开发者开始写代码,并且把这个工单分配给自己,增加标签“正在进行”。
编码 & 提交
在他的第一次提交的信息中,他提及了他的工单编号。在工作后,他把他的提交推送到一个功能分支,并且创建一个新的合并请求,在 MR 描述中,包含工单关闭模式。他的团队复审了他的代码并且保证所有的测试和建立都已经通过。
使用工单看板
一旦后端团队完成了他们的工作,他们就删除“正在进行”标签,并且把工单从“后端”移动到“前端”看板。所以,前端团队接到通知,这个工单已经为他们准备好了。
发布到演示
当一个前端开发者开始在该工单上工作,他(她)增加一个标签“正在进行”,并且把这个工单重新分配给自己。当工作完成,该实现将会被发布到一个演示环境。标签“正在进行”就会被删除,然后在工单看板里,工单卡被移动到“演示”列表中。
团队合作
最后,当新功能成功实现,你的团队把它移动到“就绪”列表。
然后,就是你的技术文档编写团队的时间了,他们为新功能书写文档。一旦某个人完成书写,他添加标签“文档”。同时,你的市场团队开始启动并推荐该功能,所以某个人添加“市场”。当技术文档书写完毕,书写者删除标签“文档”。一旦市场团队完成他们的工作,他们将工单从“市场”移动到“生产”。
部署到生产环境
最后,你将会成为那个为新版本负责的人,合并“合并请求”并且将新功能部署到生产环境,然后工单的状态转变为关闭。
反馈
通过周期分析,你和你的团队节省了如何从点子到产品的时间,并且开启另一个工单,来讨论如何将这个过程进一步提升。
总结
GitLab 工作流通过一个单一平台帮助你的团队加速从点子到生产的改变:
- 它是有效的:因为你可以获取你想要的结果
- 它是高效的:因为你可以用最小的努力和成本达到最大的生产力
- 它是高产的:因为你可以非常有效的计划和行动
- 它是简单的:因为你不需要安装不同的工具去完成你的目的,仅仅需要 GitLab
- 它是快速的:因为你不需要在多个平台间跳转来完成你的工作
每一个月的 22 号都会有一个新的 GitLab 版本释出,让它在集成软件开发解决方案上变得越来越好,让团队可以在一个单一的、唯一的界面下一起工作。
在 GitLab,每个人都可以奉献!多亏了我们强大的社区,我们获得了我们想要的。并且多亏了他们,我们才能一直为你提供更好的产品。
还有什么问题和反馈吗?请留言,或者在推特上@我们@GitLab!
via: https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/
作者:Marcia Ramos 译者:svtter 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出