
[TL;DR] 这是系列的第二篇文章,这系列讲述了我的公司如何把基础服务从PaaS迁移到Docker上
- 第一篇文章: 我谈到了接触Docker之前的经历;
- 第三篇文章: 我展示如何使创建镜像的过程自动化以及如何用Docker部署一个Rails应用。
为什么需要搭建一个私有的registry呢?嗯,对于新手来说,Docker Hub(一个Docker公共仓库)只允许你拥有一个免费的私有版本库(repo)。其他的公司也开始提供类似服务,但是价格可不便宜。另外,如果你需要用Docker部署一个用于生产环境的应用,恐怕你不希望将这些镜像放在公开的Docker Hub上吧!
这篇文章提供了一个非常务实的方法来处理搭建私有Docker registry时出现的各种错综复杂的情况。我们将会使用一个运行于DigitalOcean(之后简称为DO)的非常小巧的512MB VPS 实例。并且我会假定你已经了解了Docker的基本概念,因为我必须集中精力在复杂的事情上!
本地搭建
首先你需要安装boot2docker以及docker CLI。如果你已经搭建好了基本的Docker环境,你可以直接跳过这一步。
从终端运行以下命令(我假设你使用OS X,使用 HomeBrew 来安装相关软件,你可以根据你的环境使用不同的包管理软件来安装):
brew install boot2docker docker
如果一切顺利(想要了解搭建docker环境的完整指南,请参阅 http://boot2docker.io/) ,你现在就能够通过如下命令启动一个 Docker 运行于其中的虚拟机:
boot2docker up
按照屏幕显示的说明,复制粘贴book2docker在终端输出的命令。如果你现在运行docker ps命令,终端将有以下显示。
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
好了,Docker已经准备就绪,这就够了,我们回过头去搭建registry。
创建服务器
登录进你的DO账号,选择一个预安装了Docker的镜像文件,创建一个新的Drople。(本文写成时选择的是 Image > Applications > Docker 1.4.1 on 14.04)
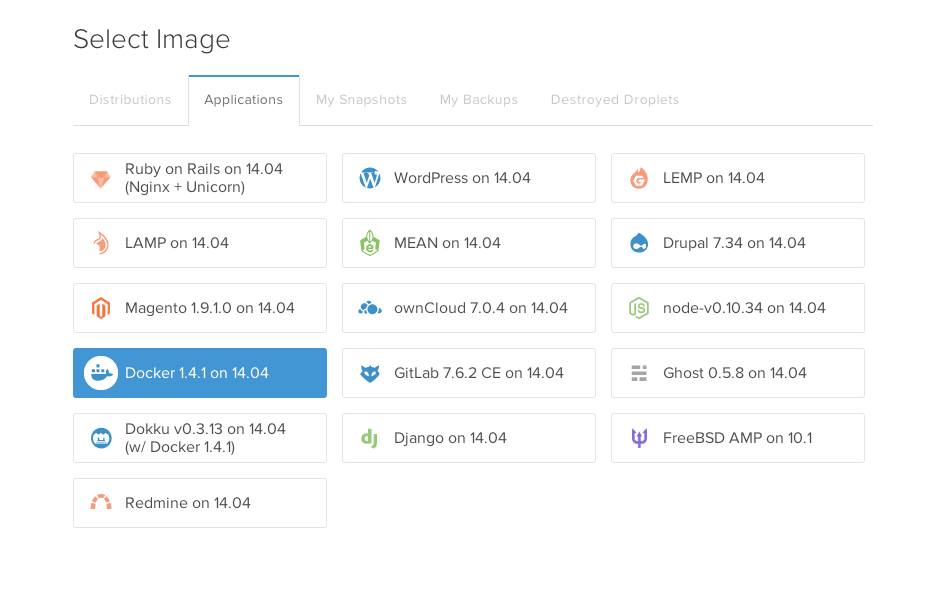
你将会以邮件的方式收到一个根用户凭证。登录进去,然后运行docker ps命令来查看系统状态。
搭建AWS S3
我们现在将使用Amazo Simple Storage Service(S3)作为我们registry/repository的存储层。我们将需要创建一个桶(bucket)以及用户凭证(user credentials)来允许我们的docker容器访问它。
登录到我们的AWS账号(如果没有,就申请一个http://aws.amazon.com/),在控制台选择S3(Simpole Storage Service)。

点击 Create Bucket,为你的桶输入一个名字(把它记下来,我们一会需要用到它),然后点击Create。
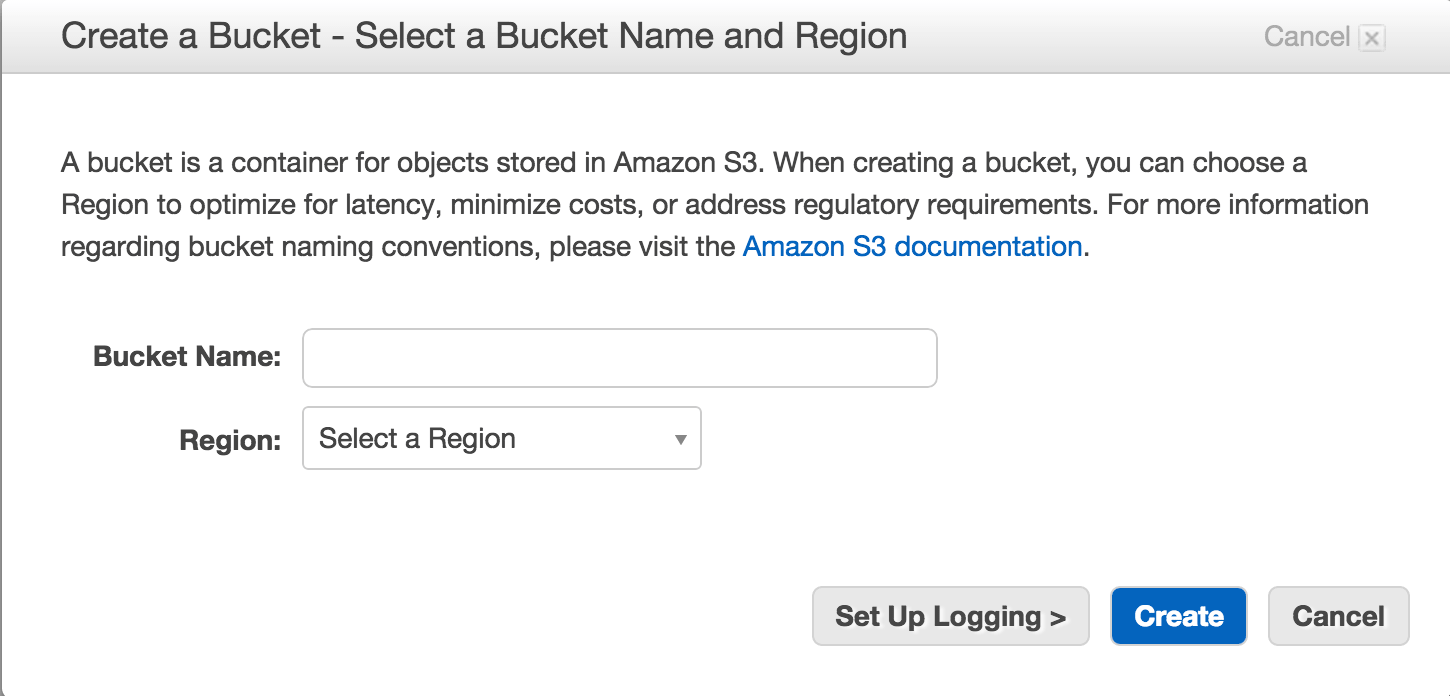
OK!我们已经搭建好存储部分了。
设置AWS访问凭证
我们现在将要创建一个新的用户。退回到AWS控制台然后选择IAM(Identity & Access Management)。
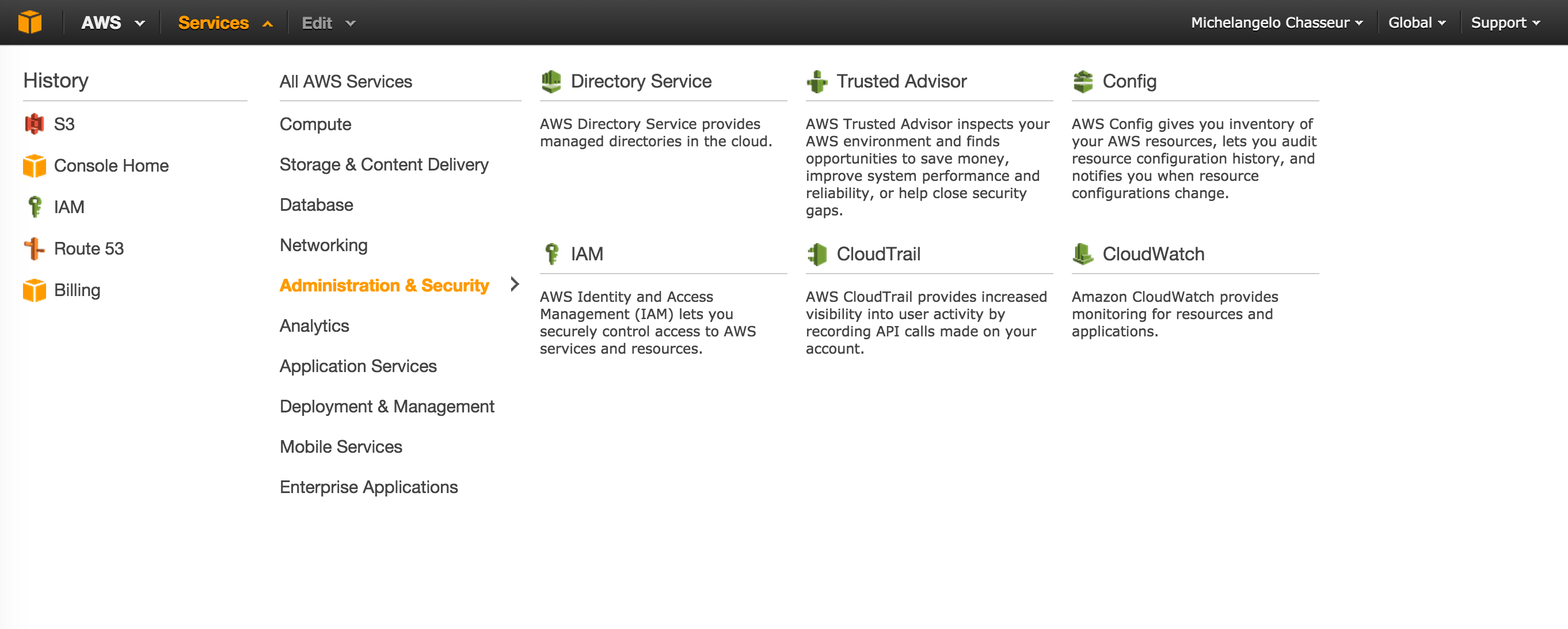
在dashboard的左边,点击Users。然后选择 Create New Users。
如图所示:

输入一个用户名(例如 docker-registry)然后点击Create。写下(或者下载csv文件)你的Access Key以及Secret Access Key。回到你的用户列表然后选择你刚刚创建的用户。
在Permission section下面,点击Attach User Policy。之后在下一屏,选择Custom Policy。
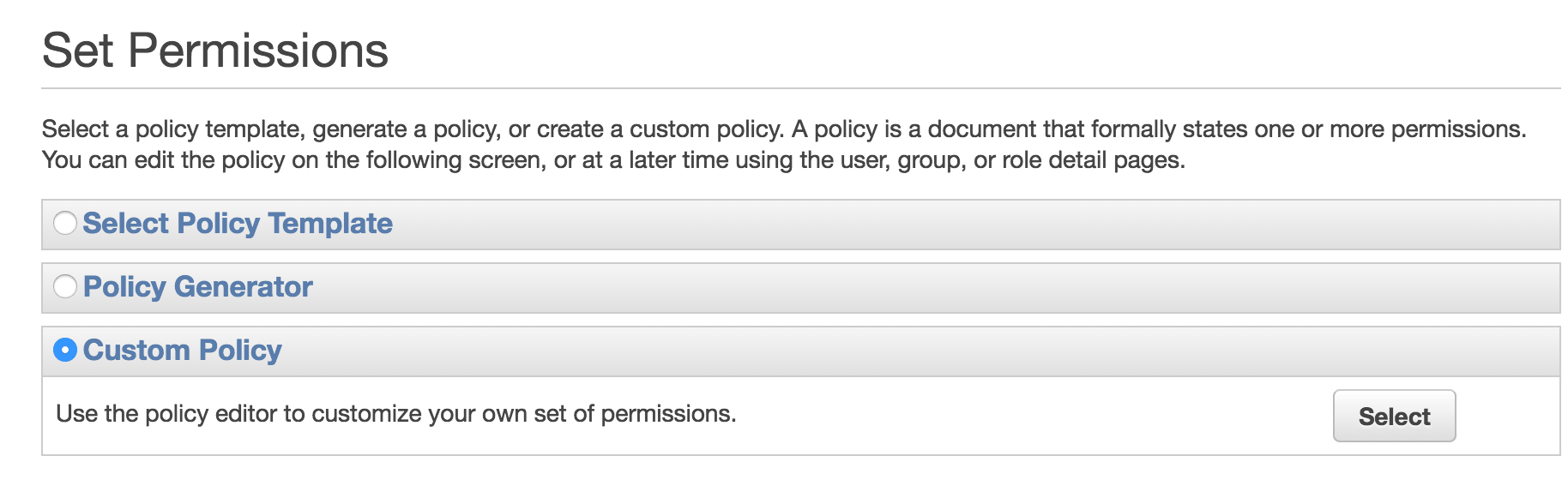
custom policy的内容如下:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "SomeStatement",
"Effect": "Allow",
"Action": [
"s3:*"
],
"Resource": [
"arn:aws:s3:::docker-registry-bucket-name/*",
"arn:aws:s3:::docker-registry-bucket-name"
]
}
]
}
这个配置将允许用户(也就是regitstry)来对桶上的内容进行操作(读/写)(确保使用你之前创建AWS S3时使用的桶名)。总结一下:当你想把你的Docker镜像从你的本机推送到仓库中时,服务器就会将他们上传到S3。
安装registry
现在回过头来看我们的DO服务器,SSH登录其上。我们将要使用一个官方Docker registry镜像。
输入如下命令,开启registry。
docker run \
-e SETTINGS_FLAVOR=s3 \
-e AWS_BUCKET=bucket-name \
-e STORAGE_PATH=/registry \
-e AWS_KEY=your_aws_key \
-e AWS_SECRET=your_aws_secret \
-e SEARCH_BACKEND=sqlalchemy \
-p 5000:5000 \
--name registry \
-d \
registry
Docker将会从Docker Hub上拉取所需的文件系统分层(fs layers)并启动守护容器(daemonised container)。
测试registry
如果上述操作奏效,你可以通过ping命令,或者查找它的内容来测试registry(虽然这个时候容器还是空的)。
我们的registry非常基础,而且没有提供任何“验明正身”的方式。因为添加身份验证可不是一件轻松事(至少我认为没有一种部署方法是简单的,像是为了证明你努力过似的),我觉得“查询/拉取/推送”仓库内容的最简单方法就是通过SSH通道的未加密连接(通过HTTP)。
打开SSH通道的操作非常简单:
ssh -N -L 5000:localhost:5000 root@your_registry.com
这条命令建立了一条从registry服务器(前面执行docker run命令的时候我们见过它)的5000号端口到本机的5000号端口之间的 SSH 管道连接。
如果你现在用浏览器访问 http://localhost:5000/v1/_ping,将会看到下面这个非常简短的回复。
{}
这个意味着registry工作正常。你还可以通过登录 http://localhost:5000/v1/search 来查看registry内容,内容相似:
{
"num_results": 2,
"query": "",
"results": [
{
"description": "",
"name": "username/first-repo"
},
{
"description": "",
"name": "username/second-repo"
}
]
}
创建一个镜像
我们现在创建一个非常简单的Docker镜像,来检验我们新弄好的registry。在我们的本机上,用如下内容创建一个Dockerfile(这里只有一点代码,在下一篇文章里我将会展示给你如何将一个Rails应用绑定进Docker容器中。):
# ruby 2.2.0 的基础镜像
FROM ruby:2.2.0
MAINTAINER Michelangelo Chasseur <[email protected]>
并创建它:
docker build -t localhost:5000/username/repo-name .
localhost:5000这个部分非常重要:Docker镜像名的最前面一个部分将告知docker push命令我们将要把我们的镜像推送到哪里。在我们这个例子当中,因为我们要通过SSH管道连接远程的私有registry,localhost:5000精确地指向了我们的registry。
如果一切顺利,当命令执行完成返回后,你可以输入docker images命令来列出新近创建的镜像。执行它看看会出现什么现象?
推送到仓库
接下来是更好玩的部分。实现我所描述的东西着实花了我一点时间,所以如果你第一次读的话就耐心一点吧,跟着我一起操作。我知道接下来的东西会非常复杂(如果你不自动化这个过程就一定会这样),但是我保证到最后你一定都能明白。在下一篇文章里我将会使用到一大波shell脚本和Rake任务,通过它们实现自动化并且用简单的命令实现部署Rails应用。
你在终端上运行的docker命令实际上都是使用boot2docker虚拟机来运行容器及各种东西。所以当你执行像docker push some_repo这样的命令时,是boot2docker虚拟机在与registry交互,而不是我们自己的机器。
接下来是一个非常重要的点:为了将Docker镜像推送到远端的私有仓库,SSH管道需要在boot2docker虚拟机上配置好,而不是在你的本地机器上配置。
有许多种方法实现它。我给你展示最简短的一种(可能不是最容易理解的,但是能够帮助你实现自动化)
在这之前,我们需要对 SSH 做最后一点工作。
设置 SSH
让我们把boot2docker 的 SSH key添加到远端服务器的“已知主机”里面。我们可以使用ssh-copy-id工具完成,通过下面的命令就可以安装上它了:
brew install ssh-copy-id
然后运行:
ssh-copy-id -i /Users/username/.ssh/id_boot2docker [email protected]
用你ssh key的真实路径代替/Users/username/.ssh/id_boot2docker。
这样做能够让我们免密码登录SSH。
现在我们来测试以下:
boot2docker ssh "ssh -o 'StrictHostKeyChecking no' -i /Users/michelangelo/.ssh/id_boot2docker -N -L 5000:localhost:5000 [email protected] &" &
分开阐述:
从其他服务器上拉取
你现在将可以通过下面的简单命令将你的镜像推送到远端仓库:
docker push localhost:5000/username/repo_name
在下一篇文章中,我们将会了解到如何自动化处理这些事务,并且真正地容器化一个Rails应用。请继续收听!
如有错误,请不吝指出。祝你Docker之路顺利!
via: http://cocoahunter.com/2015/01/23/docker-2/
作者:Michelangelo Chasseur 译者:DongShuaike 校对:wxy
本文由 LCTT 原创翻译,Linux中国 荣誉推出

















