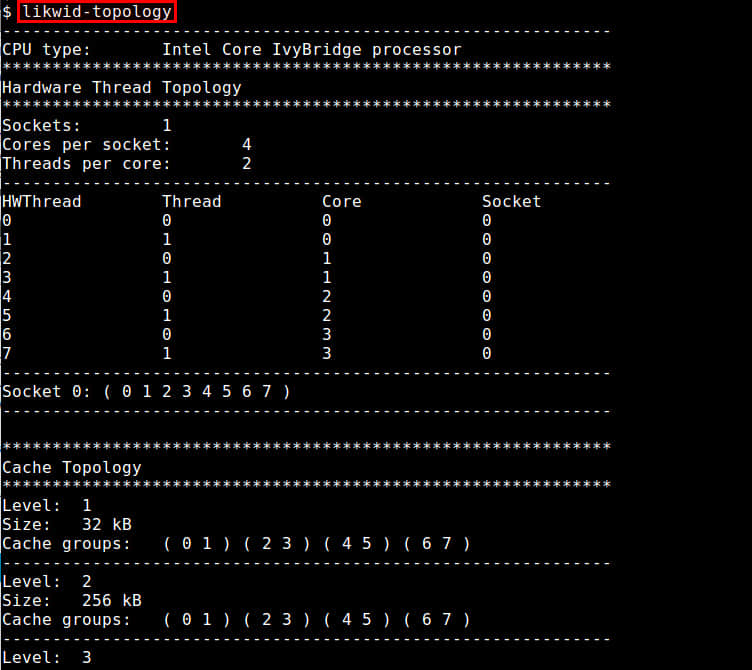
浅述内核中“挂起到空闲”的实现
简介
Linux 内核提供了多种睡眠状态,各个状态通过设置系统中的不同部件进入低耗电模式来节约能源。目前总共有四种睡眠状态,分别是: 挂起到空闲 、 加电待机 、 挂起到内存 和 挂起到磁盘 。这些状态分别对应 ACPI 的 4 种状态:S0,S1,S3 和 S4。 挂起到空闲 是纯软件实现的,用于将 CPU 维持在尽可能深的 idle 状态。 加电待机 则使设备处于低功耗状态,并且关闭所有非引导 CPU。 挂起到内存 就更进一步,关闭所有 CPU 并且设置 RAM 进入自刷新模式。 挂起到磁盘 则是最省功耗的模式,关闭尽可能多的系统,包括关闭内存。然后内存中的内容会被写到硬盘,待唤醒计算机的时候将硬盘中的内容重新恢复到内存中。

这篇博文主要介绍 挂起到空闲 的实现。如上所说,它主要通过软件实现。一般平台的挂起过程包括冻结用户空间并将外围设备调至低耗电模式。但是,系统并不是直接关闭和热插拔掉 CPU,而是静静地强制将 CPU 进入 空闲 状态。随着外围设备进入了低耗电模式,除了唤醒相关的中断外不应有其他中断产生。唤醒中断包括那些设置用于唤醒系统的计时器(比如 RTC,普通计时器等)、或者电源开关、USB 和其它外围设备等。
在冻结过程中,当系统进入空闲状态时会调用一个特殊的 cpu 空闲函数。这个 enter_freeze() 函数可以和调用使 cpu 空闲的 enter() 函数一样简单,也可以复杂得多。该函数复杂的程度由将 SoC 置为低耗电模式的条件和方法决定。
先决条件
platform_suspend_ops
一般情况,为了支持 S2I,系统必须实现 platform_suspend_ops 并提供最低限度的挂起支持。这意味着至少要完成 platform_suspend_ops 中的 valid() 函数。如果 挂起到空闲 和 挂起到内存 都要支持,valid 函数中应使用 suspend_valid_only_mem。
不过,最近内核增加了对 S2I 的自动支持。Sudeep Holla 提出了一个变更,可以让系统不需要满足 platform_suspend_ops 条件也能提供 S2I 支持。这个补丁已经被接收并将合并在 4.9 版本中,该补丁可从这里获取: https://lkml.org/lkml/2016/8/19/474。
如果定义了 suspend_ops,那么可以通过查看 /sys/power/state 文件得知系统具体支持哪些挂起状态。如下操作:
# cat /sys/power/state
freeze mem
这个示例的结果显示该平台支持 S0( 挂起到空闲 )和 S3( 挂起到内存 )。按 Sudeep 的变更,那些没有实现 platform_suspend_ops 的平台将只显示 freeze 状态。
唤醒中断
一旦系统处于某种睡眠状态,系统必须要接收某个唤醒事件才能恢复系统。这些唤醒事件一般由系统的设备产生。因此一定要确保这些设备驱动使用唤醒中断,并且将自身配置为接收唤醒中断后产生唤醒事件。如果没有正确识别唤醒设备,系统收到中断后会继续保持睡眠状态而不会恢复。
一旦设备正确实现了唤醒接口的调用,就可用来生成唤醒事件。请确保 DT 文件正确配置了唤醒源。下面是一个配置唤醒源示例,该文件来自(arch/arm/boot/dst/am335x-evm.dts):
gpio_keys: volume_keys@0 {
compatible = “gpio-keys”;
#address-cells = <1>;
#size-cells = <0>;
autorepeat;
switch@9 {
label = “volume-up”;
linux,code = <115>;
gpios = <&gpio0 2 GPIO_ACTIVE_LOW>;
wakeup-source;
};
switch@10 {
label = “volume-down”;
linux,code = <114>;
gpios = <&gpio0 3 GPIO_ACTIVE_LOW>;
wakeup-source;
};
};如上所示,有两个 gpio 键被配置为唤醒源,在系统挂起期间,其中任何一个键被按下都会产生一个唤醒事件。
可替代 DT 文件配置的另一个唤醒源配置就是设备驱动,如果设备驱动自身在代码里面配置了唤醒支持,那么就会使用该默认唤醒配置。
实施
冻结功能
如果系统希望能够充分使用 挂起到空闲 ,那么应该在 CPU 空闲驱动代码中定义 enter_freeze() 函数。enter_freeze() 与 enter() 的函数原型略有不同。因此,不能将 enter() 同时指定给 enter 和 enter_freeze。至少,系统会直接调用 enter()。如果没有定义 enter_freeze(),系统会挂起,但是不会触发那些只有当 enter_freeze() 定义了才会触发的函数,比如 tick_freeze() 和 stop_critical_timing() 都不会发生。这会导致计时器中断唤醒系统,但不会导致系统恢复,因为系统处理完中断后会继续挂起。
在挂起过程中,中断越少越好(最好一个也没有)。
下图显示了能耗和时间的对比。图中的两个尖刺分别是挂起和恢复。挂起前后的能耗尖刺是系统退出空闲态进行记录操作,进程调度,计时器处理等。因延迟的缘故,系统进入更深层次空闲状态需要花费一段时间。

能耗使用时序图
下图为 ftrace 抓取的 4 核 CPU 在系统挂起和恢复操作之前、之中和之后的活动。可以看到,在挂起期间,没有请求或者中断被处理。

Ftrace 抓取的挂起/恢复活动图
空闲状态
你必须确定哪个空闲状态支持冻结。在冻结期间,电源相关代码会决定用哪个空闲状态来实现冻结。这个过程是通过在每个空闲状态中查找谁定义了 enter_freeze() 来决定的。CPU 空闲驱动代码或者 SoC 挂起相关代码必须确定哪种空闲状态实现冻结操作,并通过给每个 CPU 的可应用空闲状态指定冻结功能来进行配置。
例如, Qualcomm 会在平台挂起代码的挂起初始化函数处定义 enter_freeze 函数。这个工作是在 CPU 空闲驱动已经初始化后进行,以便所有结构已经定义就位。
挂起/恢复相关驱动支持
你可能会在第一次成功挂起操作后碰到驱动相关的 bug。很多驱动开发者没有精力完全测试挂起和恢复相关的代码。你甚至可能会发现挂起操作并没有多少工作可做,因为 pm_runtime 已经做了你要做的挂起相关的一切工作。由于用户空间已经被冻结,设备此时已经处于休眠状态并且 pm_runtime 已经被禁止。
测试相关
测试 挂起到空闲 可以手动进行,也可以使用脚本/进程等实现自动挂起、自动睡眠,或者使用像 Android 中的 wakelock 来让系统挂起。如果手动测试,下面的操作会将系统冻结。
/ # echo freeze > /sys/power/state
[ 142.580832] PM: Syncing filesystems … done.
[ 142.583977] Freezing user space processes … (elapsed 0.001 seconds) done.
[ 142.591164] Double checking all user space processes after OOM killer disable… (elapsed 0.000 seconds)
[ 142.600444] Freezing remaining freezable tasks … (elapsed 0.001 seconds) done.
[ 142.608073] Suspending console(s) (use no_console_suspend to debug)
[ 142.708787] mmc1: Reset 0x1 never completed.
[ 142.710608] msm_otg 78d9000.phy: USB in low power mode
[ 142.711379] PM: suspend of devices complete after 102.883 msecs
[ 142.712162] PM: late suspend of devices complete after 0.773 msecs
[ 142.712607] PM: noirq suspend of devices complete after 0.438 msecs
< system suspended >
….
< wake irq triggered >
[ 147.700522] PM: noirq resume of devices complete after 0.216 msecs
[ 147.701004] PM: early resume of devices complete after 0.353 msecs
[ 147.701636] msm_otg 78d9000.phy: USB exited from low power mode
[ 147.704492] PM: resume of devices complete after 3.479 msecs
[ 147.835599] Restarting tasks … done.
/ #在上面的例子中,需要注意 MMC 驱动的操作占了 102.883ms 中的 100ms。有些设备驱动在挂起的时候有很多工作要做,比如将数据刷出到硬盘,或者其他耗时的操作等。
如果系统定义了 冻结 ,那么系统将尝试挂起操作,如果没有冻结功能,那么你会看到下面的提示:
/ # echo freeze > /sys/power/state
sh: write error: Invalid argument
/ #未来的发展
目前在 ARM 平台上的 挂起到空闲 有两方面的工作需要做。第一方面工作在前面 platform_suspend_ops 小节中提到过,是总允许接受冻结状态以及合并到 4.9 版本内核中的工作。另一方面工作是冻结功能的支持。
如果你希望设备有更好的响应及表现,那么应该继续完善冻结功能的实现。然而,由于很多 SoC 会使用 ARM 的 CPU 空闲驱动,这使得 ARM 的 CPU 空闲驱动完善它自己的通用冻结功能的工作更有意义了。而事实上,ARM 正在尝试添加此通用支持。如果 SoC 供应商希望实现他们自己的 CPU 空闲驱动或者需要在进入更深层次的冻结休眠状态时提供额外的支持,那么只有实现自己的冻结功能。
via: http://www.linaro.org/blog/suspend-to-idle/
作者:Andy Gross 译者:beyondworld 校对:jasminepeng