在我的上一篇文章里, 我介绍了 Linux 容器背后的技术的概念。我写了我知道的一切。容器对我来说也是比较新的概念。我写这篇文章的目的就是鼓励我真正的来学习这些东西。
我打算在使用中学习。首先实践,然后上手并记录下我是怎么走过来的。我假设这里肯定有很多像 "Hello World" 这种类型的知识帮助我快速的掌握基础。然后我能够更进一步,构建一个微服务容器或者其它东西。
我想,它应该不会有多难的。
但是我错了。
可能对某些人来说这很简单,因为他们在运维工作方面付出了大量的时间。但是对我来说实际上是很困难的,可以从我在Facebook 上的状态展示出来的挫折感就可以看出了。
但是还有一个好消息:我最终搞定了。而且它工作的还不错。所以我准备分享向你分享我如何制作我的第一个微服务容器。我的痛苦可能会节省你不少时间呢。
如果你曾经发现你也处于过这种境地,不要害怕:像我这样的人都能搞定,所以你也肯定行。
让我们开始吧。

一个缩略图微服务
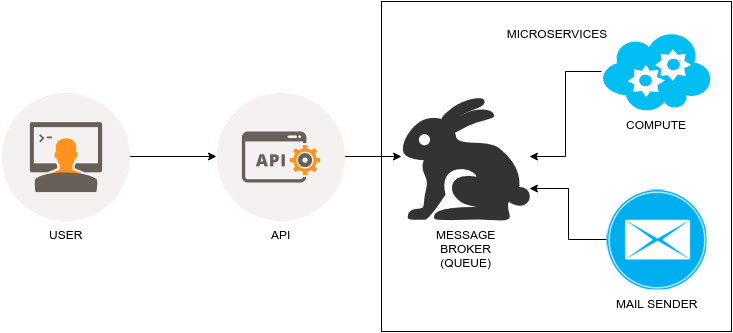
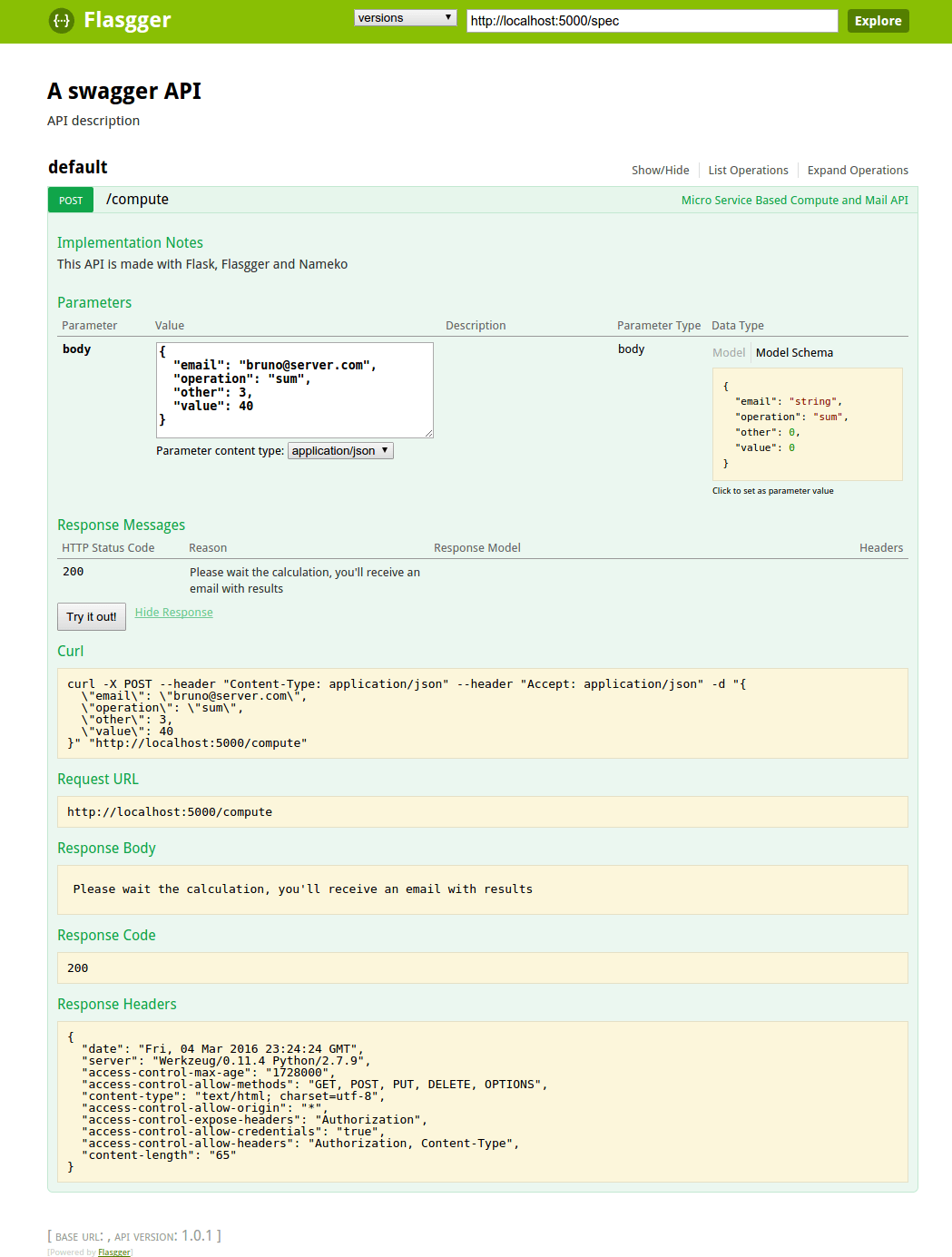
我设计的微服务在理论上很简单。以 JPG 或者 PNG 格式在 HTTP 终端发布一张数字照片,然后获得一个100像素宽的缩略图。
下面是它的流程:

我决定使用 NodeJS 作为我的开发语言,使用 ImageMagick 来转换缩略图。
我的服务的第一版的逻辑如下所示:

我下载了 Docker Toolbox,用它安装了 Docker 的快速启动终端(Docker Quickstart Terminal)。Docker 快速启动终端使得创建容器更简单了。终端会启动一个装好了 Docker 的 Linux 虚拟机,它允许你在一个终端里运行 Docker 命令。
虽然在我的例子里,我的操作系统是 Mac OS X。但是 Windows 下也有相同的工具。
我准备使用 Docker 快速启动终端里为我的微服务创建一个容器镜像,然后从这个镜像运行容器。
Docker 快速启动终端就运行在你使用的普通终端里,就像这样:

第一个小问题和第一个大问题
我用 NodeJS 和 ImageMagick 瞎搞了一通,然后让我的服务在本地运行起来了。
然后我创建了 Dockerfile,这是 Docker 用来构建容器的配置脚本。(我会在后面深入介绍构建过程和 Dockerfile)
这是我运行 Docker 快速启动终端的命令:
$ docker build -t thumbnailer:0.1
获得如下回应:
docker: "build" requires 1 argument.
呃。
我估摸着过了15分钟我才反应过来:我忘记了在末尾参数输入一个点.。
正确的指令应该是这样的:
$ docker build -t thumbnailer:0.1 .
但是这不是我遇到的最后一个问题。
我让这个镜像构建好了,然后我在 Docker 快速启动终端输入了 run 命令来启动容器,名字叫 thumbnailer:0.1:
$ docker run -d -p 3001:3000 thumbnailer:0.1
参数 -p 3001:3000 让 NodeJS 微服务在 Docker 内运行在端口3000,而绑定在宿主主机上的3001。
到目前看起来都很好,对吧?
错了。事情要马上变糟了。
我通过运行 docker-machine 命令为这个 Docker 快速启动终端里创建的虚拟机指定了 ip 地址:
$ docker-machine ip default
这句话返回了默认虚拟机的 IP 地址,它运行在 Docker 快速启动终端里。在我这里,这个 ip 地址是 192.168.99.100。
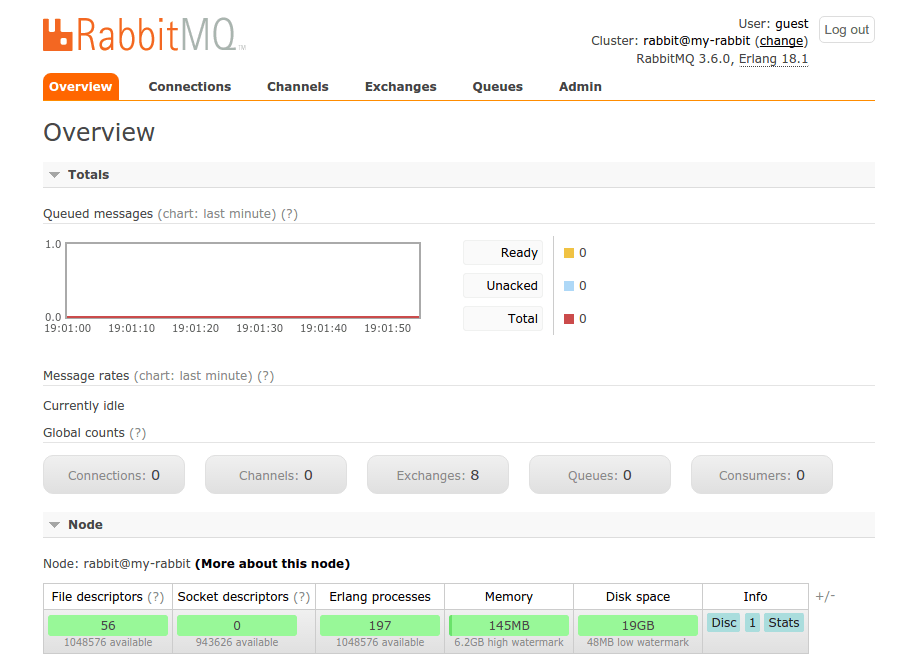
我浏览网页 http://192.168.99.100:3001/ ,然后找到了我创建的上传图片的网页:

我选择了一个文件,然后点击上传图片的按钮。
但是它并没有工作。
终端告诉我他无法找到我的微服务需要的 /upload 目录。
现在,你要知道,我已经在此耗费了将近一天的时间-从浪费时间到研究问题。我此时感到了一些挫折感。
然后灵光一闪。某人记起来微服务不应该自己做任何数据持久化的工作!保存数据应该是另一个服务的工作。
所以容器找不到目录 /upload 的原因到底是什么?这个问题的根本就是我的微服务在基础设计上就有问题。
让我们看看另一幅图:

我为什么要把文件保存到磁盘?微服务按理来说是很快的。为什么不能让我的全部工作都在内存里完成?使用内存缓冲可以解决“找不到目录”这个问题,而且可以提高我的应用的性能。
这就是我现在所做的。下面是我的计划:

这是我用 NodeJS 写的在内存运行、生成缩略图的代码:
// Bind to the packages
var express = require('express');
var router = express.Router();
var path = require('path'); // used for file path
var im = require("imagemagick");
// Simple get that allows you test that you can access the thumbnail process
router.get('/', function (req, res, next) {
res.status(200).send('Thumbnailer processor is up and running');
});
// This is the POST handler. It will take the uploaded file and make a thumbnail from the
// submitted byte array. I know, it's not rocket science, but it serves a purpose
router.post('/', function (req, res, next) {
req.pipe(req.busboy);
req.busboy.on('file', function (fieldname, file, filename) {
var ext = path.extname(filename)
// Make sure that only png and jpg is allowed
if(ext.toLowerCase() != '.jpg' && ext.toLowerCase() != '.png'){
res.status(406).send("Service accepts only jpg or png files");
}
var bytes = [];
// put the bytes from the request into a byte array
file.on('data', function(data) {
for (var i = 0; i < data.length; ++i) {
bytes.push(data[i]);
}
console.log('File [' + fieldname + '] got bytes ' + bytes.length + ' bytes');
});
// Once the request is finished pushing the file bytes into the array, put the bytes in
// a buffer and process that buffer with the imagemagick resize function
file.on('end', function() {
var buffer = new Buffer(bytes,'binary');
console.log('Bytes got ' + bytes.length + ' bytes');
//resize
im.resize({
srcData: buffer,
height: 100
}, function(err, stdout, stderr){
if (err){
throw err;
}
// get the extension without the period
var typ = path.extname(filename).replace('.','');
res.setHeader("content-type", "image/" + typ);
res.status(200);
// send the image back as a response
res.send(new Buffer(stdout,'binary'));
});
});
});
});
module.exports = router;
好了,一切回到了正轨,已经可以在我的本地机器正常工作了。我该去休息了。
但是,在我测试把这个微服务当作一个普通的 Node 应用运行在本地时...

它工作的很好。现在我要做的就是让它在容器里面工作。
第二天我起床后喝点咖啡,然后创建一个镜像——这次没有忘记那个"."!
$ docker build -t thumbnailer:01 .
我从缩略图项目的根目录开始构建。构建命令使用了根目录下的 Dockerfile。它是这样工作的:把 Dockerfile 放到你想构建镜像的地方,然后系统就默认使用这个 Dockerfile。
下面是我使用的Dockerfile 的内容:
FROM ubuntu:latest
MAINTAINER [email protected]
RUN apt-get update
RUN apt-get install -y nodejs nodejs-legacy npm
RUN apt-get install imagemagick libmagickcore-dev libmagickwand-dev
RUN apt-get clean
COPY ./package.json src/
RUN cd src && npm install
COPY . /src
WORKDIR src/
CMD npm start
这怎么可能出错呢?
第二个大问题
我运行了 build 命令,然后出了这个错:
Do you want to continue? [Y/n] Abort.
The command '/bin/sh -c apt-get install imagemagick libmagickcore-dev libmagickwand-dev' returned a non-zero code: 1
我猜测微服务出错了。我回到本地机器,从本机启动微服务,然后试着上传文件。
然后我从 NodeJS 获得了这个错误:
Error: spawn convert ENOENT
怎么回事?之前还是好好的啊!
我搜索了我能想到的所有的错误原因。差不多4个小时后,我想:为什么不重启一下机器呢?
重启了,你猜猜结果?错误消失了!(LCTT 译注:万能的“重启试试”)
继续。
将精灵关进瓶子里
跳回正题:我需要完成构建工作。
我使用 rm 命令删除了虚拟机里所有的容器。
$ docker rm -f $(docker ps -a -q)
-f 在这里的用处是强制删除运行中的镜像。
然后删除了全部 Docker 镜像,用的是命令 rmi:
$ docker rmi if $(docker images | tail -n +2 | awk '{print $3}')
我重新执行了重新构建镜像、安装容器、运行微服务的整个过程。然后过了一个充满自我怀疑和沮丧的一个小时,我告诉我自己:这个错误可能不是微服务的原因。
所以我重新看到了这个错误:
Do you want to continue? [Y/n] Abort.
The command '/bin/sh -c apt-get install imagemagick libmagickcore-dev libmagickwand-dev' returned a non-zero code: 1
这太打击我了:构建脚本好像需要有人从键盘输入 Y! 但是,这是一个非交互的 Dockerfile 脚本啊。这里并没有键盘。
回到 Dockerfile,脚本原来是这样的:
RUN apt-get update
RUN apt-get install -y nodejs nodejs-legacy npm
RUN apt-get install imagemagick libmagickcore-dev libmagickwand-dev
RUN apt-get clean
第二个apt-get 忘记了-y 标志,它用于自动应答提示所需要的“yes”。这才是错误的根本原因。
我在这条命令后面添加了-y :
RUN apt-get update
RUN apt-get install -y nodejs nodejs-legacy npm
RUN apt-get install -y imagemagick libmagickcore-dev libmagickwand-dev
RUN apt-get clean
猜一猜结果:经过将近两天的尝试和痛苦,容器终于正常工作了!整整两天啊!
我完成了构建工作:
$ docker build -t thumbnailer:0.1 .
启动了容器:
$ docker run -d -p 3001:3000 thumbnailer:0.1
获取了虚拟机的IP 地址:
$ docker-machine ip default
在我的浏览器里面输入 http://192.168.99.100:3001/ :
上传页面打开了。
我选择了一个图片,然后得到了这个:

工作了!
在容器里面工作了,我的第一次啊!
这让我学到了什么?
很久以前,我接受了这样一个道理:当你刚开始尝试某项技术时,即使是最简单的事情也会变得很困难。因此,我不会把自己当成最聪明的那个人,然而最近几天尝试容器的过程就是一个充满自我怀疑的旅程。
但是你想知道一些其它的事情吗?这篇文章是我在凌晨2点完成的,而每一个受折磨的时刻都值得了。为什么?因为这段时间你将自己全身心投入了喜欢的工作里。这件事很难,对于所有人来说都不是很容易就获得结果的。但是不要忘记:你在学习技术,运行世界的技术。
P.S. 了解一下Hello World 容器的两段视频,这里会有 Raziel Tabib’s 的精彩工作内容。
千万被忘记第二部分...
via: https://deis.com/blog/2015/beyond-hello-world-containers-hard-stuff
作者:Bob Reselman 译者:Ezio 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出