使用 GDB 查看程序的栈空间

昨天我和一些人在闲聊的时候,他们说他们并不真正了解栈是如何工作的,而且也不知道如何去查看栈空间。
这是一个快速教程,介绍如何使用 GDB 查看 C 程序的栈空间。我认为这对于 Rust 程序来说也是相似的。但我这里仍然使用 C 语言,因为我发现用它更简单,而且用 C 语言也更容易写出错误的程序。
我们的测试程序
这里是一个简单的 C 程序,声明了一些变量,从标准输入读取两个字符串。一个字符串在堆上,另一个字符串在栈上。
#include <stdio.h>
#include <stdlib.h>
int main() {
char stack_string[10] = "stack";
int x = 10;
char *heap_string;
heap_string = malloc(50);
printf("Enter a string for the stack: ");
gets(stack_string);
printf("Enter a string for the heap: ");
gets(heap_string);
printf("Stack string is: %s\n", stack_string);
printf("Heap string is: %s\n", heap_string);
printf("x is: %d\n", x);
}
这个程序使用了一个你可能从来不会使用的极为不安全的函数 gets 。但我是故意这样写的。当出现错误的时候,你就知道是为什么了。
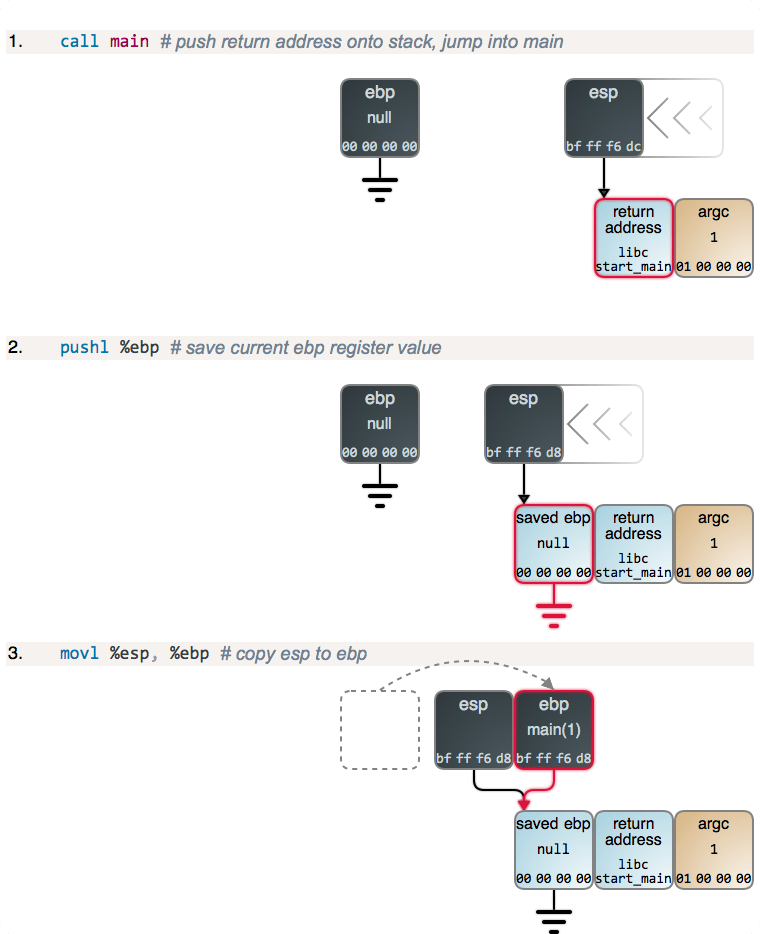
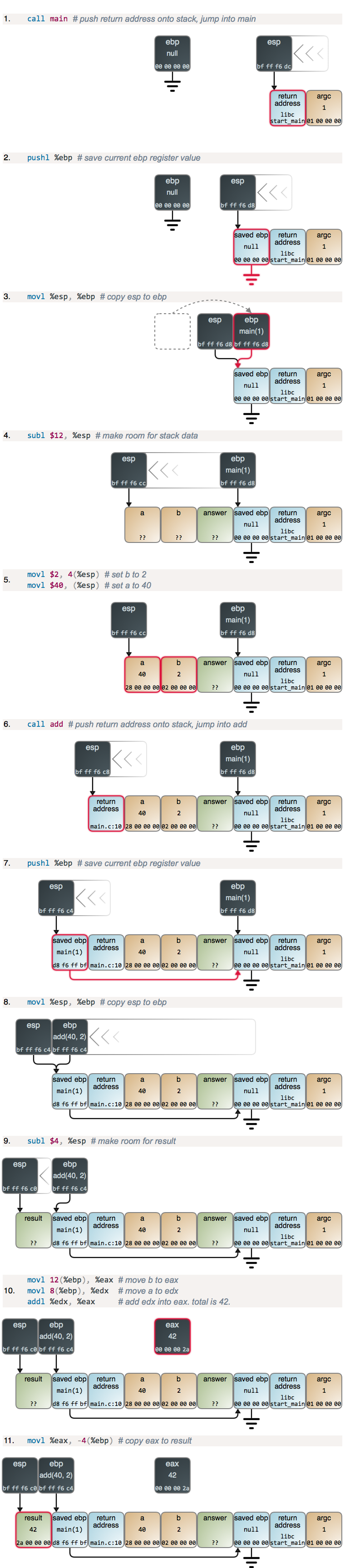
第 0 步:编译这个程序
我们使用 gcc -g -O0 test.c -o test 命令来编译这个程序。
-g 选项会在编译程序中将调式信息也编译进去。这将会使我们查看我们的变量更加容易。
-O0 选项告诉 gcc 不要进行优化,我要确保我们的 x 变量不会被优化掉。
第一步:启动 GDB
像这样启动 GDB:
$ gdb ./test
它打印出一些 GPL 信息,然后给出一个提示符。让我们在 main 函数这里设置一个断点:
(gdb) b main
然后我们就可以运行程序:
(gdb) b main
Starting program: /home/bork/work/homepage/test
Breakpoint 1, 0x000055555555516d in main ()
(gdb) run
Starting program: /home/bork/work/homepage/test
Breakpoint 1, main () at test.c:4
4 int main() {
好了,现在程序已经运行起来了。我们就可以开始查看栈空间了。
第二步:查看我们变量的地址
让我们从了解我们的变量开始。它们每个都在内存中有一个地址,我们可以像这样打印出来:
(gdb) p &x
$3 = (int *) 0x7fffffffe27c
(gdb) p &heap_string
$2 = (char **) 0x7fffffffe280
(gdb) p &stack_string
$4 = (char (*)[10]) 0x7fffffffe28e
因此,如果我们查看那些地址的堆栈,那我们应该能够看到所有的这些变量!
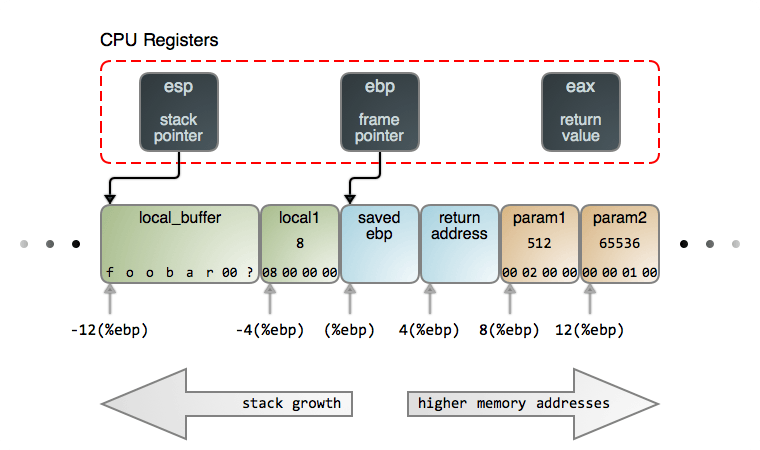
概念:栈指针
我们将需要使用栈指针,因此我将尽力对其进行快速解释。
有一个名为 ESP 的 x86 寄存器,称为“ 栈指针 ”。 基本上,它是当前函数的栈起始地址。 在 GDB 中,你可以使用 $sp 来访问它。 当你调用新函数或从函数返回时,栈指针的值会更改。
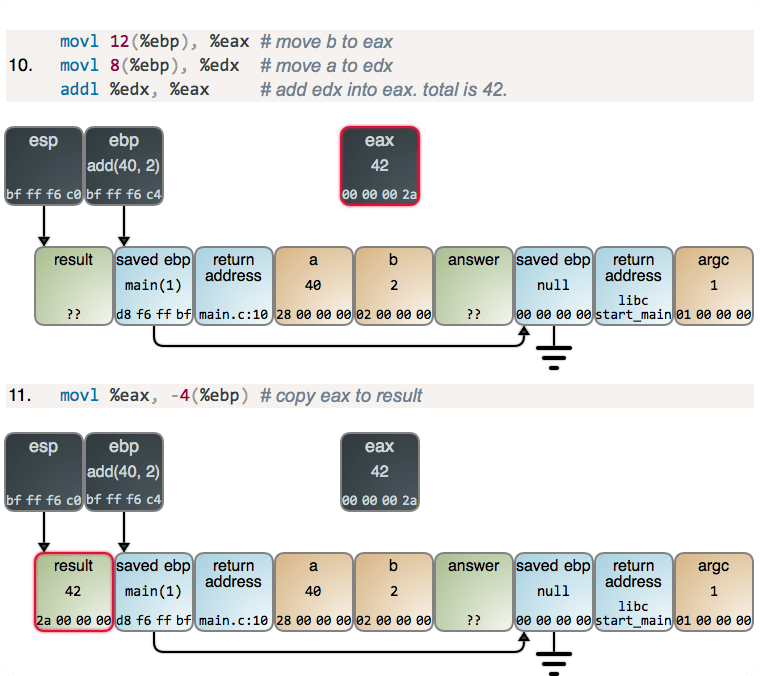
第三步:在 main 函数开始的时候,我们查看一下在栈上的变量
首先,让我们看一下 main 函数开始时的栈。 现在是我们的堆栈指针的值:
(gdb) p $sp
$7 = (void *) 0x7fffffffe270
因此,我们当前函数的栈起始地址是 0x7fffffffe270,酷极了。
现在,让我们使用 GDB 打印出当前函数堆栈开始后的前 40 个字(即 160 个字节)。 某些内存可能不是栈的一部分,因为我不太确定这里的堆栈有多大。 但是至少开始的地方是栈的一部分。

我已粗体显示了 stack_string,heap_string 和 x 变量的位置,并改变了颜色:
x是红色字体,并且起始地址是0x7fffffffe27cheap_string是蓝色字体,起始地址是0x7fffffffe280stack_string是紫色字体,起始地址是0x7fffffffe28e
你可能会在这里注意到的一件奇怪的事情是 x 的值是 0x5555,但是我们将 x 设置为 10! 那是因为直到我们的 main 函数运行之后才真正设置 x ,而我们现在才到了 main 最开始的地方。
第三步:运行到第十行代码后,再次查看一下我们的堆栈
让我们跳过几行,等待变量实际设置为其初始化值。 到第 10 行时,x 应该设置为 10。
首先我们需要设置另一个断点:
(gdb) b test.c:10
Breakpoint 2 at 0x5555555551a9: file test.c, line 11.
然后继续执行程序:
(gdb) continue
Continuing.
Breakpoint 2, main () at test.c:11
11 printf("Enter a string for the stack: ");
好的! 让我们再来看看堆栈里的内容! gdb 在这里格式化字节的方式略有不同,实际上我也不太关心这些(LCTT 译注:可以查看 GDB 手册中 x 命令,可以指定 c 来控制输出的格式)。 这里提醒一下你,我们的变量在栈上的位置:
x是红色字体,并且起始地址是0x7fffffffe27cheap_string是蓝色字体,起始地址是0x7fffffffe280stack_string是紫色字体,起始地址是0x7fffffffe28e

在继续往下看之前,这里有一些有趣的事情要讨论。
stack_string 在内存中是如何表示的
现在(第 10 行),stack_string 被设置为字符串stack。 让我们看看它在内存中的表示方式。
我们可以像这样打印出字符串中的字节(LCTT 译注:可以通过 c 选项直接显示为字符):
(gdb) x/10x stack_string
0x7fffffffe28e: 0x73 0x74 0x61 0x63 0x6b 0x00 0x00 0x00
0x7fffffffe296: 0x00 0x00
stack 是一个长度为 5 的字符串,相对应 5 个 ASCII 码- 0x73、0x74、0x61、0x63 和 0x6b。0x73 是字符 s 的 ASCII 码。 0x74 是 t 的 ASCII 码。等等...
同时我们也使用 x/1s 可以让 GDB 以字符串的方式显示:
(gdb) x/1s stack_string
0x7fffffffe28e: "stack"
heap_string 与 stack_string 有何不同
你已经注意到了 stack_string 和 heap_string 在栈上的表示非常不同:
stack_string是一段字符串内容(stack)heap_string是一个指针,指向内存中的某个位置
这里是 heap_string 变量在内存中的内容:
0xa0 0x92 0x55 0x55 0x55 0x55 0x00 0x00
这些字节实际上应该是从右向左读:因为 x86 是小端模式,因此,heap_string 中所存放的内存地址 0x5555555592a0
另一种方式查看 heap_string 中存放的内存地址就是使用 p 命令直接打印 :
(gdb) p heap_string
$6 = 0x5555555592a0 ""
整数 x 的字节表示
x 是一个 32 位的整数,可由 0x0a 0x00 0x00 0x00 来表示。
我们还是需要反向来读取这些字节(和我们读取 heap_string 需要反过来读是一样的),因此这个数表示的是 0x000000000a 或者是 0x0a,它是一个数字 10;
这就让我把把 x 设置成了 10。
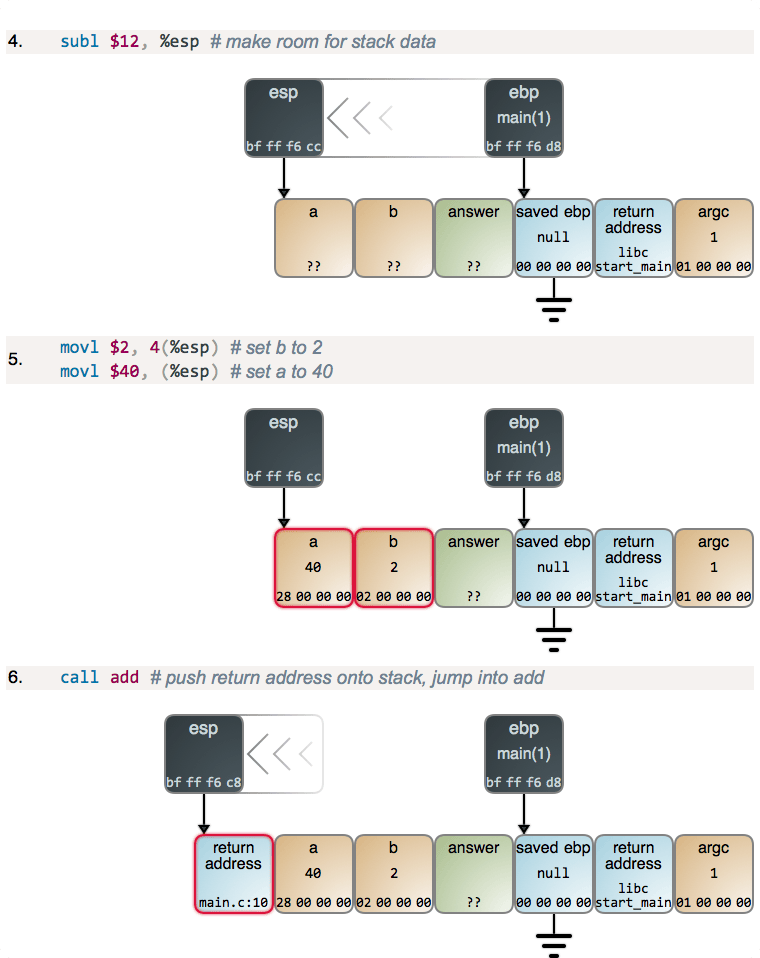
第四步:从标准输入读取
好了,现在我们已经初始化我们的变量,我们来看一下当这段程序运行的时候,栈空间会如何变化:
printf("Enter a string for the stack: ");
gets(stack_string);
printf("Enter a string for the heap: ");
gets(heap_string);
我们需要设置另外一个断点:
(gdb) b test.c:16
Breakpoint 3 at 0x555555555205: file test.c, line 16.
然后继续执行程序:
(gdb) continue
Continuing.
我们输入两个字符串,为栈上存储的变量输入 123456789012 并且为在堆上存储的变量输入 bananas;
让我们先来看一下 stack_string(这里有一个缓存区溢出)
(gdb) x/1s stack_string
0x7fffffffe28e: "123456789012"
这看起来相当正常,对吗?我们输入了 12345679012,然后现在它也被设置成了 12345679012(LCTT 译注:实测 gcc 8.3 环境下,会直接段错误)。
但是现在有一些很奇怪的事。这是我们程序的栈空间的内容。有一些紫色高亮的内容。

令人奇怪的是 stack_string 只支持 10 个字节。但是现在当我们输入了 13 个字符以后,发生了什么?
这是一个典型的缓冲区溢出,stack_string 将自己的数据写在了程序中的其他地方。在我们的案例中,这还没有造成问题,但它会使你的程序崩溃,或者更糟糕的是,使你面临非常糟糕的安全问题。
例如,假设 stack_string 在内存里的位置刚好在 heap_string 之前。那我们就可能覆盖 heap_string 所指向的地址。我并不确定 stack_string 之后的内存里有一些什么。但我们也许可以用它来做一些诡异的事情。
确实检测到了有缓存区溢出
当我故意写很多字符的时候:
./test
Enter a string for the stack: 01234567891324143
Enter a string for the heap: adsf
Stack string is: 01234567891324143
Heap string is: adsf
x is: 10
*** stack smashing detected ***: terminated
fish: Job 1, './test' terminated by signal SIGABRT (Abort)
这里我猜是 stack_string 已经到达了这个函数栈的底部,因此额外的字符将会被写在另一块内存中。
当你故意去使用这个安全漏洞时,它被称为“堆栈粉碎”,而且不知何故有东西在检测这种情况的发生。
我也觉得这很有趣,虽然程序被杀死了,但是当缓冲区溢出发生时它不会立即被杀死——在缓冲区溢出之后再运行几行代码,程序才会被杀死。 好奇怪!
这些就是关于缓存区溢出的所有内容。
现在我们来看一下 heap_string
我们仍然将 bananas 输入到 heap_string 变量中。让我们来看一下内存中的样子。
这是在我们读取了字符串以后,heap_string 在栈空间上的样子:

需要注意的是,这里的值是一个地址。并且这个地址并没有改变,但是我们来看一下指向的内存上的内容。
(gdb) x/10x 0x5555555592a0
0x5555555592a0: 0x62 0x61 0x6e 0x61 0x6e 0x61 0x73 0x00
0x5555555592a8: 0x00 0x00
看到了吗,这就是字符串 bananas 的字节表示。这些字节并不在栈空间上。他们存在于内存中的堆上。
堆和栈到底在哪里?
我们已经讨论过栈和堆是不同的内存区域,但是你怎么知道它们在内存中的位置呢?
每个进程都有一个名为 /proc/$PID/maps 的文件,它显示了每个进程的内存映射。 在这里你可以看到其中的栈和堆。
$ cat /proc/24963/maps
... lots of stuff omitted ...
555555559000-55555557a000 rw-p 00000000 00:00 0 [heap]
... lots of stuff omitted ...
7ffffffde000-7ffffffff000 rw-p 00000000 00:00 0 [stack]
需要注意的一件事是,这里堆地址以 0x5555 开头,栈地址以 0x7fffff 开头。 所以很容易区分栈上的地址和堆上的地址之间的区别。
像这样使用 gdb 真的很有帮助
这有点像旋风之旅,虽然我没有解释所有内容,但希望看到数据在内存中的实际情况可以使你更清楚地了解堆栈的实际情况。
我真的建议像这样来把玩一下 gdb —— 即使你不理解你在内存中看到的每一件事,我发现实际上像这样看到我程序内存中的数据会使抽象的概念,比如“栈”和“堆”和“指针”更容易理解。
更多练习
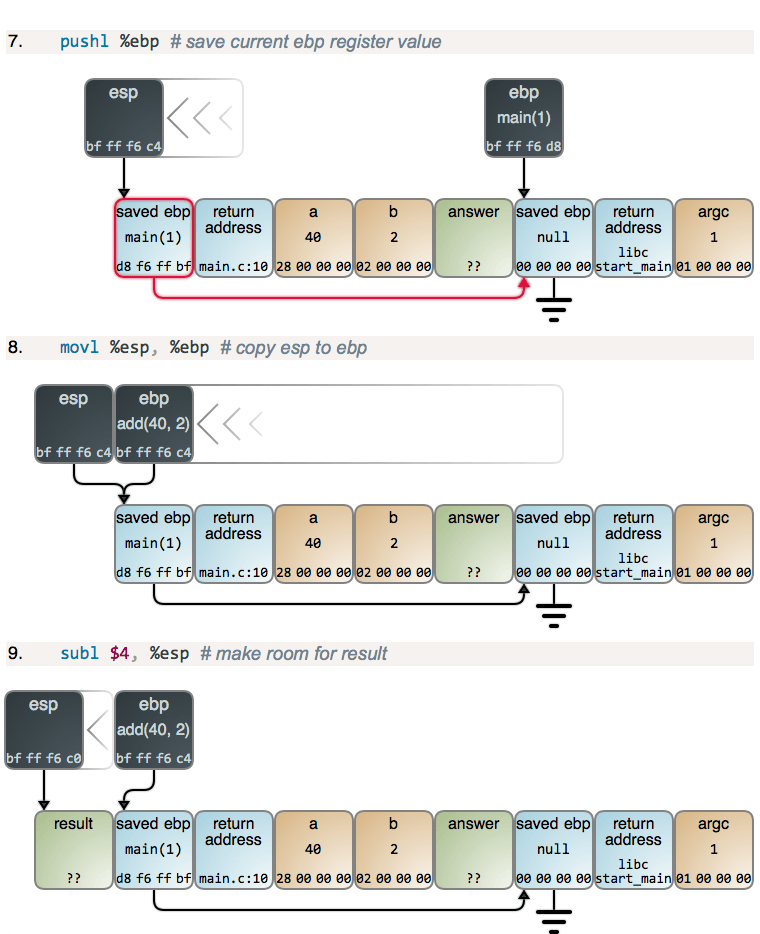
一些关于思考栈的后续练习的想法(没有特定的顺序):
- 尝试将另一个函数添加到
test.c并在该函数的开头创建一个断点,看看是否可以从main中找到堆栈! 他们说当你调用一个函数时“堆栈会变小”,你能在 gdb 中看到这种情况吗? - 从函数返回一个指向栈上字符串的指针,看看哪里出了问题。 为什么返回指向栈上字符串的指针是不好的?
- 尝试在 C 中引起堆栈溢出,并尝试通过在 gdb 中查看堆栈溢出来准确理解会发生什么!
- 查看 Rust 程序中的堆栈并尝试找到变量!
- 在 噩梦课程 中尝试一些缓冲区溢出挑战。每个问题的答案写在 README 文件中,因此如果你不想被宠坏,请避免先去看答案。 所有这些挑战的想法是给你一个二进制文件,你需要弄清楚如何导致缓冲区溢出以使其打印出
flag字符串。
via: https://jvns.ca/blog/2021/05/17/how-to-look-at-the-stack-in-gdb/
作者:Julia Evans 选题:lujun9972 译者:amwps290 校对:wxy




{kind=link}