使用vmstat和iostat命令进行Linux性能监控
这是我们正在进行的Linux命令和性能监控系列的一部分。vmstat和iostat两个命令都适用于所有主要的类unix系统(Linux/unix/FreeBSD/Solaris)。
如果vmstat和iostat命令在你的系统中不可用,请安装sysstat软件包。vmstat,sar和iostat命令都包含在sysstat(系统监控工具)软件包中。iostat命令生成CPU和所有设备的统计信息。你可以从这个连接中下载源代码包编译安装sysstat,但是我们建议通过YUM命令进行安装。

在Linux系统中安装sysstat
#yum -y install sysstat
- vmstat - 内存,进程和分页等的简要信息。
- iostat - CPU统计信息,设备和分区的输入/输出统计信息。
Linux下vmstat命令的6个范例
1. 列出活动和非活动的内存
如下范例中输出6列。vmstat的man页面中解析的每一列的意义。最重要的是内存中的free属性和交换分区中的si和so属性。
[root@tecmint ~]# vmstat -a
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free inact active si so bi bo in cs us sy id wa st
1 0 0 810420 97380 70628 0 0 115 4 89 79 1 6 90 3 0
- Free – 空闲的内存空间
- si – 每秒从磁盘中交换进内存的数据量(以KB为单位)。
- so – 每秒从内存中交换出磁盘的数据量(以KB为单位)。
注意:如果你不带参数的执行vmstat命令,它会输出自系统启动以来的总结报告。
2. 每X秒执行vmstat,共执行N次
下面命令将会每2秒中执行一次vmstat,执行6次后自动停止执行。
[root@tecmint ~]# vmstat 2 6
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 810420 22064 101368 0 0 56 3 50 57 0 3 95 2 0
0 0 0 810412 22064 101368 0 0 0 0 16 35 0 0 100 0 0
0 0 0 810412 22064 101368 0 0 0 0 14 35 0 0 100 0 0
0 0 0 810412 22064 101368 0 0 0 0 17 38 0 0 100 0 0
0 0 0 810412 22064 101368 0 0 0 0 17 35 0 0 100 0 0
0 0 0 810412 22064 101368 0 0 0 0 18 36 0 1 100 0 0
3. 带时间戳的vmstat命令
带-t参数执行vmstat命令,该命令将会在每一行输出后都带一个时间戳,如下所示。
[tecmint@tecmint ~]$ vmstat -t 1 5
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------ ---timestamp---
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 632028 24992 192244 0 0 70 5 55 78 1 3 95 1 0 2012-09-02 14:57:18 IST
1 0 0 632028 24992 192244 0 0 0 0 171 514 1 5 94 0 0 2012-09-02 14:57:19 IST
1 0 0 631904 24992 192244 0 0 0 0 195 600 0 5 95 0 0 2012-09-02 14:57:20 IST
0 0 0 631780 24992 192244 0 0 0 0 156 524 0 5 95 0 0 2012-09-02 14:57:21 IST
1 0 0 631656 24992 192244 0 0 0 0 189 592 0 5 95 0 0 2012-09-02 14:57:22 IST
4. 统计各种计数器
vmstat命令的-s参数,将输出各种事件计数器和内存的统计信息。
[tecmint@tecmint ~]$ vmstat -s
1030800 total memory
524656 used memory
277784 active memory
185920 inactive memory
506144 free memory
26864 buffer memory
310104 swap cache
2064376 total swap
0 used swap
2064376 free swap
4539 non-nice user cpu ticks
0 nice user cpu ticks
11569 system cpu ticks
329608 idle cpu ticks
5012 IO-wait cpu ticks
79 IRQ cpu ticks
74 softirq cpu ticks
0 stolen cpu ticks
336038 pages paged in
67945 pages paged out
0 pages swapped in
0 pages swapped out
258526 interrupts
392439 CPU context switches
1346574857 boot time
2309 forks
5. 磁盘统计信息
vmstat的-d参数将会输出所有磁盘的统计信息。
[tecmint@tecmint ~]$ vmstat -d
disk- ------------reads------------ ------------writes----------- -----IO------
total merged sectors ms total merged sectors ms cur sec
ram0 0 0 0 0 0 0 0 0 0 0
ram1 0 0 0 0 0 0 0 0 0 0
ram2 0 0 0 0 0 0 0 0 0 0
ram3 0 0 0 0 0 0 0 0 0 0
ram4 0 0 0 0 0 0 0 0 0 0
ram5 0 0 0 0 0 0 0 0 0 0
ram6 0 0 0 0 0 0 0 0 0 0
ram7 0 0 0 0 0 0 0 0 0 0
ram8 0 0 0 0 0 0 0 0 0 0
ram9 0 0 0 0 0 0 0 0 0 0
ram10 0 0 0 0 0 0 0 0 0 0
ram11 0 0 0 0 0 0 0 0 0 0
ram12 0 0 0 0 0 0 0 0 0 0
ram13 0 0 0 0 0 0 0 0 0 0
ram14 0 0 0 0 0 0 0 0 0 0
ram15 0 0 0 0 0 0 0 0 0 0
loop0 0 0 0 0 0 0 0 0 0 0
loop1 0 0 0 0 0 0 0 0 0 0
loop2 0 0 0 0 0 0 0 0 0 0
loop3 0 0 0 0 0 0 0 0 0 0
loop4 0 0 0 0 0 0 0 0 0 0
loop5 0 0 0 0 0 0 0 0 0 0
loop6 0 0 0 0 0 0 0 0 0 0
loop7 0 0 0 0 0 0 0 0 0 0
sr0 0 0 0 0 0 0 0 0 0 0
sda 7712 5145 668732 409619 3282 28884 257402 644566 0 126
dm-0 11578 0 659242 1113017 32163 0 257384 8460026 0 126
dm-1 324 0 2592 3845 0 0 0 0 0 2
6. 以MB为单位输出统计信息
vmstat的-S和-M参数(大写和MB)将会以MB为单位输出。vmstat默认以KB为单位输出统计信息。
[root@tecmint ~]# vmstat -S M 1 5
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 346 53 476 0 0 95 8 42 55 0 2 96 2 0
0 0 0 346 53 476 0 0 0 0 12 15 0 0 100 0 0
0 0 0 346 53 476 0 0 0 0 32 62 0 0 100 0 0
0 0 0 346 53 476 0 0 0 0 15 13 0 0 100 0 0
0 0 0 346 53 476 0 0 0 0 34 61 0 1 99 0 0
linux下的Iostat命令的6个范例
1. 输出CPU和输入/输出(I/O)的统计信息
不带参数的iostat命令将会输出CPU和每个分区的输出/输出的统计信息,如下所示。
[root@tecmint ~]# iostat
Linux 2.6.32-279.el6.i686 (tecmint.com) 09/03/2012 _i686_ (1 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.12 0.01 1.54 2.08 0.00 96.24
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 3.59 161.02 13.48 1086002 90882
dm-0 5.76 159.71 13.47 1077154 90864
dm-1 0.05 0.38 0.00 2576 0
2. 只输出CPU的统计信息
iostat命令的-c参数仅输出CPU的统计信息,如下所示。
[root@tecmint ~]# iostat -c
Linux 2.6.32-279.el6.i686 (tecmint.com) 09/03/2012 _i686_ (1 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.12 0.01 1.47 1.98 0.00 96.42
3. 只输出磁盘的输入/输出统计信息
iostat命令的-d参数仅输出磁盘的所有分区的输入/输出的统计信息,如下所示。
[root@tecmint ~]# iostat -d
Linux 2.6.32-279.el6.i686 (tecmint.com) 09/03/2012 _i686_ (1 CPU)
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 3.35 149.81 12.66 1086002 91746
dm-0 5.37 148.59 12.65 1077154 91728
dm-1 0.04 0.36 0.00 2576 0
4. 只输出某个磁盘的输入/输出统计信息
在默认情况下iostat命令会输出所有分区的统计信息,但是若在iostat命令后加上-p参数和磁盘设备名,该命令将会仅输出列出的磁盘的输入/输出统计信息,如下所示。
[root@tecmint ~]# iostat -p sda
Linux 2.6.32-279.el6.i686 (tecmint.com) 09/03/2012 _i686_ (1 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.11 0.01 1.44 1.92 0.00 96.52
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 3.32 148.52 12.55 1086002 91770
sda1 0.07 0.56 0.00 4120 18
sda2 3.22 147.79 12.55 1080650 91752
5. 输出逻辑卷管理(LVM)的统计信息
iostat命令的-N(大写)参数将会输出LVM(LCTT译注:LVM)是linux环境下对磁盘分区进行管理的一种机制,是磁盘分区和文件系统间的一个逻辑层)的统计信息,如下所示。
[root@tecmint ~]# iostat -N
Linux 2.6.32-279.el6.i686 (tecmint.com) 09/03/2012 _i686_ (1 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.11 0.01 1.39 1.85 0.00 96.64
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 3.20 142.84 12.16 1086002 92466
vg_tecmint-lv_root 5.13 141.68 12.16 1077154 92448
vg_tecmint-lv_swap 0.04 0.34 0.00 2576 0
6. iostat版本信息
iostat的-V(大写)参数将会输出iostat的版本信息,如下所示。
[root@tecmint ~]# iostat -V
sysstat version 9.0.4
(C) Sebastien Godard (sysstat orange.fr)
注意:vmstat和iostat的输出中包含多列的数据和标志,限于篇幅无法在本文中进行详细的解析。如果你想知道更多的信息,请查看vmstat和iostat的man帮助手册。如果你觉得本文对你有价值,请在下面的评论框中与你的朋友分享。
via: http://www.tecmint.com/linux-performance-monitoring-with-vmstat-and-iostat-commands/
作者:Ravi Saive 译者:cvsher 校对:wxy

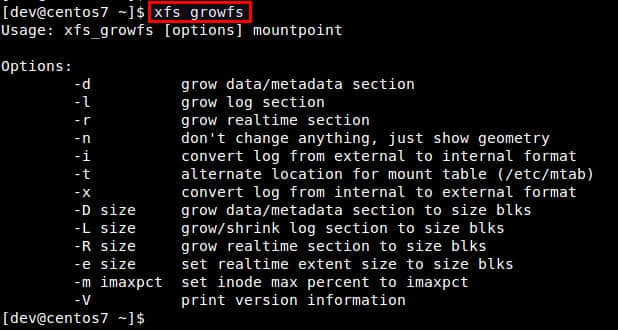
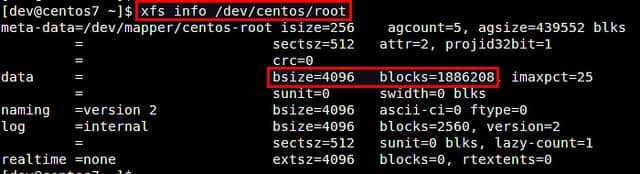
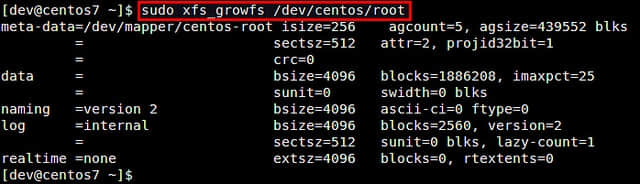
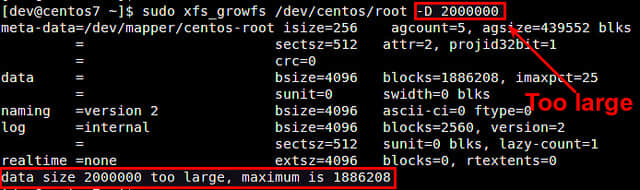









 扩展逻辑卷
扩展逻辑卷














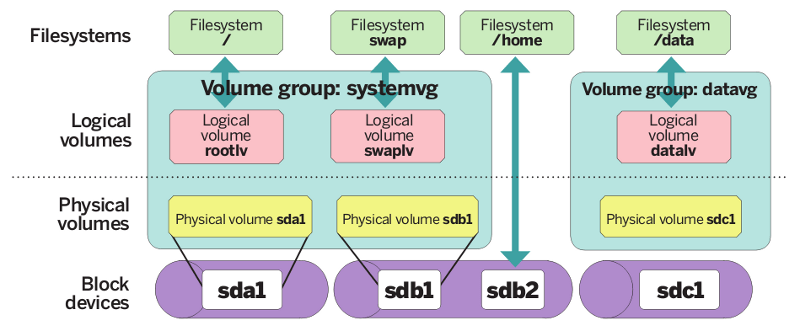 在Linux中创建LVM存储
在Linux中创建LVM存储 检查物理卷
检查物理卷 验证添加的磁盘
验证添加的磁盘 卷组显示
卷组显示 检查磁盘空间
检查磁盘空间 创建新的物理分区
创建新的物理分区 验证分区表
验证分区表 创建物理卷
创建物理卷 创建卷组
创建卷组 验证卷组
验证卷组 检查卷组信息
检查卷组信息 列出新卷组
列出新卷组 列出当前卷组
列出当前卷组 检查空闲空间
检查空闲空间 创建新逻辑卷
创建新逻辑卷 计算磁盘空间
计算磁盘空间 列出创建的逻辑卷
列出创建的逻辑卷 验证创建的逻辑卷
验证创建的逻辑卷 创建Ext4文件系统
创建Ext4文件系统 挂载逻辑卷
挂载逻辑卷 获取mtab挂载条目*
获取mtab挂载条目* 打开fstab文件
打开fstab文件 添加自动挂载条目
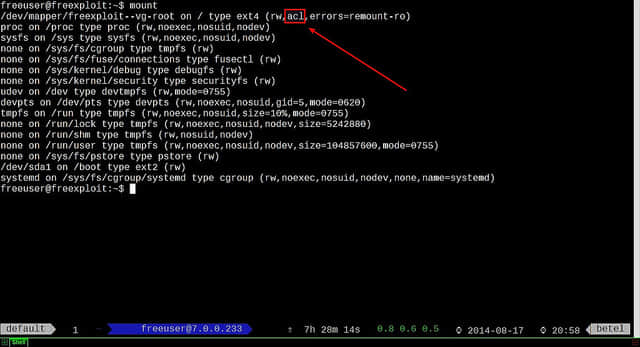
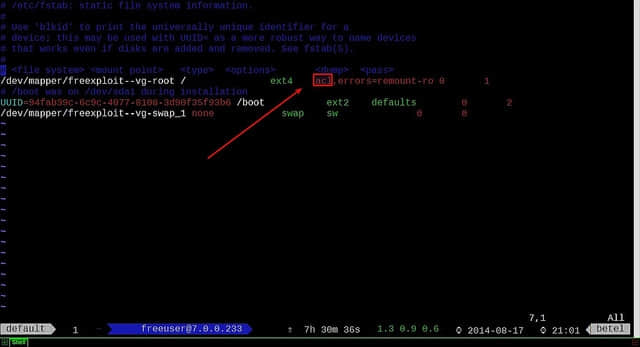
添加自动挂载条目 验证fstab条目
验证fstab条目