Chef是面对IT专业人员的一款配置管理和自动化工具,它可以配置和管理你的基础设施(设备),无论它在本地还是在云上。它可以用于加速应用部署并协调多个系统管理员和开发人员的工作,这包括可支持大量的客户群的成百上千的服务器和程序。chef最有用的是让基础设施变成代码。一旦你掌握了Chef,你可以获得自动化管理你的云端基础设施或者终端用户的一流的网络IT支持。
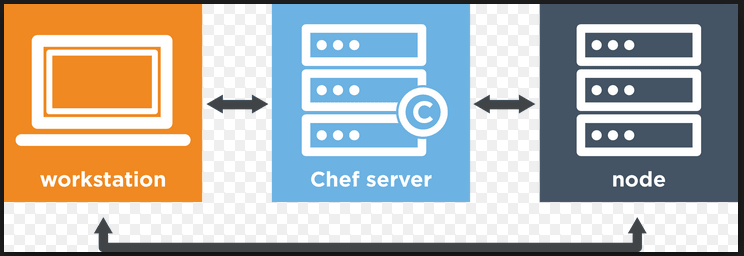
下面是我们将要在本篇中要设置和配置Chef的主要组件。
安装Chef的要求和版本
我们将在下面的基础环境下设置Chef配置管理系统。
| 管理和配置工具:Chef | |
|---|
| 基础操作系统 | Ubuntu 14.04.1 LTS (x86\_64) |
| Chef Server | Version 12.1.0 |
| Chef Manage | Version 1.17.0 |
| Chef Development Kit | Version 0.6.2 |
| 内存和CPU | 4 GB , 2.0+2.0 GHz |
Chef服务端的安装和配置
Chef服务端是核心组件,它存储配置以及其他和工作站交互的配置数据。让我们在他们的官网https://www.chef.io下载最新的安装文件。
我使用下面的命令来下载和安装它。
1) 下载Chef服务端
root@ubuntu-14-chef:/tmp# wget https://web-dl.packagecloud.io/chef/stable/packages/ubuntu/trusty/chef-server-core_12.1.0-1_amd64.deb
2) 安装Chef服务端
root@ubuntu-14-chef:/tmp# dpkg -i chef-server-core_12.1.0-1_amd64.deb
3) 重新配置Chef服务端
现在运行下面的命令来启动所有的chef服务端服务,这一步也许会花费一些时间,因为它需要由许多不同一起工作的服务组成一个可正常运作的系统。
root@ubuntu-14-chef:/tmp# chef-server-ctl reconfigure
chef服务端启动命令'chef-server-ctl reconfigure'需要运行两次,这样就会在安装后看到这样的输出。
Chef Client finished, 342/350 resources updated in 113.71139964 seconds
opscode Reconfigured!
4) 重启系统
安装完成后重启系统使系统能最好的工作,不然我们或许会在创建用户的时候看到下面的SSL连接错误。
ERROR: Errno::ECONNRESET: Connection reset by peer - SSL_connect
5) 创建新的管理员
运行下面的命令来创建一个新的管理员账户及其配置。创建过程中,用户的RSA私钥会自动生成,它需要保存到一个安全的地方。--file选项会保存RSA私钥到指定的路径下。
root@ubuntu-14-chef:/tmp# chef-server-ctl user-create kashi kashi kashi [email protected] kashi123 --filename /root/kashi.pem
Chef服务端的管理设置
Chef Manage是一个针对企业级Chef用户的管理控制台,它提供了可视化的web用户界面,可以管理节点、数据包、规则、环境、Cookbook 和基于角色的访问控制(RBAC)。
1) 下载Chef Manage
从官网复制链接并下载chef manage的安装包。
root@ubuntu-14-chef:~# wget https://web-dl.packagecloud.io/chef/stable/packages/ubuntu/trusty/opscode-manage_1.17.0-1_amd64.deb
2) 安装Chef Manage
使用下面的命令在root的家目录下安装它。
root@ubuntu-14-chef:~# chef-server-ctl install opscode-manage --path /root
3) 重启Chef Manage和服务端
安装完成后我们需要运行下面的命令来重启chef manage和服务端。
root@ubuntu-14-chef:~# opscode-manage-ctl reconfigure
root@ubuntu-14-chef:~# chef-server-ctl reconfigure
Chef Manage网页控制台
我们可以使用localhost或它的域名来访问网页控制台,并用已经创建的管理员登录

1) Chef Manage创建新的组织
你或许被要求创建新的组织,或者也可以接受其他组织的邀请。如下所示,使用缩写和全名来创建一个新的组织。

2) 用命令行创建新的组织
我们同样也可以运行下面的命令来创建新的组织。
root@ubuntu-14-chef:~# chef-server-ctl org-create linux Linoxide Linux Org. --association_user kashi --filename linux.pem
设置工作站
我们已经完成安装chef服务端,现在我们可以开始创建任何recipes(基础配置元素)、cookbooks(基础配置集)、attributes(节点属性),以及做一些其他修改。
1) 在Chef服务端上创建新的用户和组织
为了设置工作站,我们需要用命令行创建一个新的用户和组织。
root@ubuntu-14-chef:~# chef-server-ctl user-create bloger Bloger Kashif [email protected] bloger123 --filename bloger.pem
root@ubuntu-14-chef:~# chef-server-ctl org-create blogs Linoxide Blogs Inc. --association_user bloger --filename blogs.pem
2) 下载工作站入门套件
在工作站的网页控制台中下载并保存入门套件,它用于与服务端协同工作

3) 下载套件后,点击"Proceed"

用于工作站的Chef开发套件设置
Chef开发套件是一款包含开发chef所需的所有工具的软件包。它捆绑了由Chef开发的带Chef客户端的工具。
1) 下载 Chef DK
我们可以从它的官网链接中下载开发包,并选择操作系统来下载chef开发包。

复制链接并用wget下载
root@ubuntu-15-WKS:~# wget https://opscode-omnibus-packages.s3.amazonaws.com/ubuntu/12.04/x86_64/chefdk_0.6.2-1_amd64.deb
2) Chef开发套件安装
使用dpkg命令安装开发套件
root@ubuntu-15-WKS:~# dpkg -i chefdk_0.6.2-1_amd64.deb
3) Chef DK 验证
使用下面的命令验证客户端是否已经正确安装。
root@ubuntu-15-WKS:~# chef verify
Running verification for component 'berkshelf'
Running verification for component 'test-kitchen'
Running verification for component 'chef-client'
Running verification for component 'chef-dk'
Running verification for component 'chefspec'
Running verification for component 'rubocop'
Running verification for component 'fauxhai'
Running verification for component 'knife-spork'
Running verification for component 'kitchen-vagrant'
Running verification for component 'package installation'
Running verification for component 'openssl'
..............
---------------------------------------------
Verification of component 'rubocop' succeeded.
Verification of component 'knife-spork' succeeded.
Verification of component 'openssl' succeeded.
Verification of component 'berkshelf' succeeded.
Verification of component 'chef-dk' succeeded.
Verification of component 'fauxhai' succeeded.
Verification of component 'test-kitchen' succeeded.
Verification of component 'kitchen-vagrant' succeeded.
Verification of component 'chef-client' succeeded.
Verification of component 'chefspec' succeeded.
Verification of component 'package installation' succeeded.
4) 连接Chef服务端
我们将创建 ~/.chef目录,并从chef服务端复制两个用户和组织的pem文件到该目录下。
root@ubuntu-14-chef:~# scp bloger.pem blogs.pem kashi.pem linux.pem [email protected]:/.chef/
[email protected]'s password:
bloger.pem 100% 1674 1.6KB/s 00:00
blogs.pem 100% 1674 1.6KB/s 00:00
kashi.pem 100% 1678 1.6KB/s 00:00
linux.pem 100% 1678 1.6KB/s 00:00
5) 编辑配置来管理chef环境 **
现在使用下面的内容创建"~/.chef/knife.rb"。
root@ubuntu-15-WKS:/.chef# vim knife.rb
current_dir = File.dirname(__FILE__)
log_level :info
log_location STDOUT
node_name "kashi"
client_key "#{current_dir}/kashi.pem"
validation_client_name "kashi-linux"
validation_key "#{current_dir}/linux.pem"
chef_server_url "https://172.25.10.173/organizations/linux"
cache_type 'BasicFile'
cache_options( :path => "#{ENV['HOME']}/.chef/checksums" )
cookbook_path ["#{current_dir}/../cookbooks"]
创建knife.rb中指定的“~/cookbooks”文件夹。
root@ubuntu-15-WKS:/# mkdir cookbooks
6) 测试Knife配置
运行“knife user list”和“knife client list”来验证knife是否工作。
root@ubuntu-15-WKS:/.chef# knife user list
第一次运行的时候可能会看到下面的错误,这是因为工作站上还没有chef服务端的SSL证书。
ERROR: SSL Validation failure connecting to host: 172.25.10.173 - SSL_connect returned=1 errno=0 state=SSLv3 read server certificate B: certificate verify failed
ERROR: Could not establish a secure connection to the server.
Use `knife ssl check` to troubleshoot your SSL configuration.
If your Chef Server uses a self-signed certificate, you can use
`knife ssl fetch` to make knife trust the server's certificates.
要解决上面的命令的错误,运行下面的命令来获取ssl证书,并重新运行knife user和client list,这时候应该就可以了。
root@ubuntu-15-WKS:/.chef# knife ssl fetch
WARNING: Certificates from 172.25.10.173 will be fetched and placed in your trusted_cert
directory (/.chef/trusted_certs).
knife没有办法验证这些是否是有效的证书。你应该在下载时验证这些证书的真实性。
在/.chef/trusted\_certs/ubuntu-14-chef\_test\_com.crt下面添加ubuntu-14-chef.test.com的证书。
在上面的命令取得ssl证书后,接着运行下面的命令。
root@ubuntu-15-WKS:/.chef#knife client list
kashi-linux
配置与chef服务端交互的新节点
节点是执行所有基础设施自动化的chef客户端。因此,在配置完chef-server和knife工作站后,通过配置与chef-server交互的新节点,来将新的服务端添加到我们的chef环境下。
我们使用下面的命令来添加与chef服务端协同工作的新节点。
root@ubuntu-15-WKS:~# knife bootstrap 172.25.10.170 --ssh-user root --ssh-password kashi123 --node-name mydns
Doing old-style registration with the validation key at /.chef/linux.pem...
Delete your validation key in order to use your user credentials instead
Connecting to 172.25.10.170
172.25.10.170 Installing Chef Client...
172.25.10.170 --2015-07-04 22:21:16-- https://www.opscode.com/chef/install.sh
172.25.10.170 Resolving www.opscode.com (www.opscode.com)... 184.106.28.91
172.25.10.170 Connecting to www.opscode.com (www.opscode.com)|184.106.28.91|:443... connected.
172.25.10.170 HTTP request sent, awaiting response... 200 OK
172.25.10.170 Length: 18736 (18K) [application/x-sh]
172.25.10.170 Saving to: ‘STDOUT’
172.25.10.170
100%[======================================>] 18,736 --.-K/s in 0s
172.25.10.170
172.25.10.170 2015-07-04 22:21:17 (200 MB/s) - written to stdout [18736/18736]
172.25.10.170
172.25.10.170 Downloading Chef 12 for ubuntu...
172.25.10.170 downloading https://www.opscode.com/chef/metadata?v=12&prerelease=false&nightlies=false&p=ubuntu&pv=14.04&m=x86_64
172.25.10.170 to file /tmp/install.sh.26024/metadata.txt
172.25.10.170 trying wget...
之后我们可以在knife节点列表下看到创建的新节点,它也会在新节点下创建新的客户端。
root@ubuntu-15-WKS:~# knife node list
mydns
类似地我们只要通过给上面的knife命令提供ssh证书,就可以在chef设施上创建多个节点。
总结
本篇我们学习了chef管理工具,并通过安装和配置设置基本了解了它的组件。我希望你在学习安装和配置Chef服务端以及它的工作站和客户端节点中获得乐趣。
via: http://linoxide.com/ubuntu-how-to/install-configure-chef-ubuntu-14-04-15-04/
作者:Kashif Siddique 译者:geekpi 校对:wxy
本文由 LCTT 原创翻译,Linux中国 荣誉推出