在 Linux 中使用日志来排错
人们创建日志的主要原因是排错。通常你会诊断为什么问题发生在你的 Linux 系统或应用程序中。错误信息或一系列的事件可以给你提供找出根本原因的线索,说明问题是如何发生的,并指出如何解决它。这里有几个使用日志来解决的样例。

登录失败原因
如果你想检查你的系统是否安全,你可以在验证日志中检查登录失败的和登录成功但可疑的用户。当有人通过不正当或无效的凭据来登录时会出现认证失败,这通常发生在使用 SSH 进行远程登录或 su 到本地其他用户来进行访问权时。这些是由插入式验证模块(PAM)来记录的。在你的日志中会看到像 Failed password 和 user unknown 这样的字符串。而成功认证记录则会包括像 Accepted password 和 session opened 这样的字符串。
失败的例子:
pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=10.0.2.2
Failed password for invalid user hoover from 10.0.2.2 port 4791 ssh2
pam_unix(sshd:auth): check pass; user unknown
PAM service(sshd) ignoring max retries; 6 > 3
成功的例子:
Accepted password for hoover from 10.0.2.2 port 4792 ssh2
pam_unix(sshd:session): session opened for user hoover by (uid=0)
pam_unix(sshd:session): session closed for user hoover
你可以使用 grep 来查找哪些用户失败登录的次数最多。这些都是潜在的攻击者正在尝试和访问失败的账户。这是一个在 ubuntu 系统上的例子。
$ grep "invalid user" /var/log/auth.log | cut -d ' ' -f 10 | sort | uniq -c | sort -nr
23 oracle
18 postgres
17 nagios
10 zabbix
6 test
由于没有标准格式,所以你需要为每个应用程序的日志使用不同的命令。日志管理系统,可以自动分析日志,将它们有效的归类,帮助你提取关键字,如用户名。
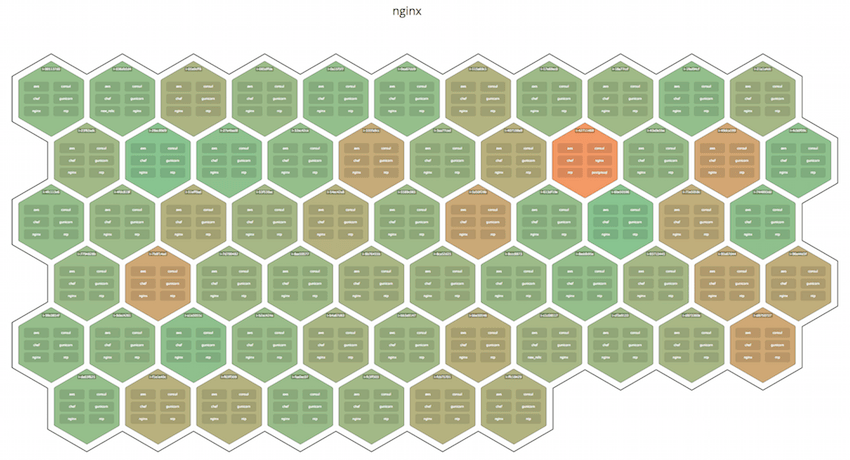
日志管理系统可以使用自动解析功能从 Linux 日志中提取用户名。这使你可以看到用户的信息,并能通过点击过滤。在下面这个例子中,我们可以看到,root 用户登录了 2700 次之多,因为我们筛选的日志仅显示 root 用户的尝试登录记录。

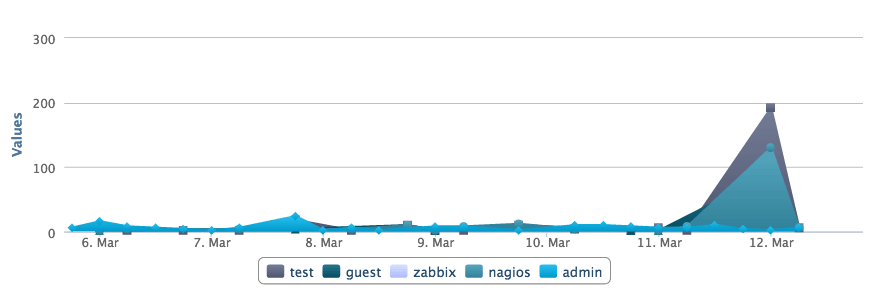
日志管理系统也可以让你以时间为做坐标轴的图表来查看,使你更容易发现异常。如果有人在几分钟内登录失败一次或两次,它可能是一个真正的用户而忘记了密码。但是,如果有几百个失败的登录并且使用的都是不同的用户名,它更可能是在试图攻击系统。在这里,你可以看到在3月12日,有人试图登录 Nagios 几百次。这显然不是一个合法的系统用户。
重启的原因
有时候,一台服务器由于系统崩溃或重启而宕机。你怎么知道它何时发生,是谁做的?
关机命令
如果有人手动运行 shutdown 命令,你可以在验证日志文件中看到它。在这里,你可以看到,有人从 IP 50.0.134.125 上作为 ubuntu 的用户远程登录了,然后关闭了系统。
Mar 19 18:36:41 ip-172-31-11-231 sshd[23437]: Accepted publickey for ubuntu from 50.0.134.125 port 52538 ssh
Mar 19 18:36:41 ip-172-31-11-231 23437]:sshd[ pam_unix(sshd:session): session opened for user ubuntu by (uid=0)
Mar 19 18:37:09 ip-172-31-11-231 sudo: ubuntu : TTY=pts/1 ; PWD=/home/ubuntu ; USER=root ; COMMAND=/sbin/shutdown -r now
内核初始化
如果你想看看服务器重新启动的所有原因(包括崩溃),你可以从内核初始化日志中寻找。你需要搜索内核类(kernel)和 cpu 初始化(Initializing)的信息。
Mar 19 18:39:30 ip-172-31-11-231 kernel: [ 0.000000] Initializing cgroup subsys cpuset
Mar 19 18:39:30 ip-172-31-11-231 kernel: [ 0.000000] Initializing cgroup subsys cpu
Mar 19 18:39:30 ip-172-31-11-231 kernel: [ 0.000000] Linux version 3.8.0-44-generic (buildd@tipua) (gcc version 4.6.3 (Ubuntu/Linaro 4.6.3-1ubuntu5) ) #66~precise1-Ubuntu SMP Tue Jul 15 04:01:04 UTC 2014 (Ubuntu 3.8.0-44.66~precise1-generic 3.8.13.25)
检测内存问题
有很多原因可能导致服务器崩溃,但一个常见的原因是内存用尽。
当你系统的内存不足时,进程会被杀死,通常会杀死使用最多资源的进程。当系统使用了所有内存,而新的或现有的进程试图使用更多的内存时就会出现错误。在你的日志文件查找像 Out of Memory 这样的字符串或类似 kill 这样的内核警告信息。这些信息表明系统故意杀死进程或应用程序,而不是允许进程崩溃。
例如:
[33238.178288] Out of memory: Kill process 6230 (firefox) score 53 or sacrifice child
[29923450.995084] select 5230 (docker), adj 0, size 708, to kill
你可以使用像 grep 这样的工具找到这些日志。这个例子是在 ubuntu 中:
$ grep “Out of memory” /var/log/syslog
[33238.178288] Out of memory: Kill process 6230 (firefox) score 53 or sacrifice child
请记住,grep 也要使用内存,所以只是运行 grep 也可能导致内存不足的错误。这是另一个你应该中央化存储日志的原因!
定时任务错误日志
cron 守护程序是一个调度器,可以在指定的日期和时间运行进程。如果进程运行失败或无法完成,那么 cron 的错误出现在你的日志文件中。具体取决于你的发行版,你可以在 /var/log/cron,/var/log/messages,和 /var/log/syslog 几个位置找到这个日志。cron 任务失败原因有很多。通常情况下,问题出在进程中而不是 cron 守护进程本身。
默认情况下,cron 任务的输出会通过 postfix 发送电子邮件。这是一个显示了该邮件已经发送的日志。不幸的是,你不能在这里看到邮件的内容。
Mar 13 16:35:01 PSQ110 postfix/pickup[15158]: C3EDC5800B4: uid=1001 from=<hoover>
Mar 13 16:35:01 PSQ110 postfix/cleanup[15727]: C3EDC5800B4: message-id=<20150310110501.C3EDC5800B4@PSQ110>
Mar 13 16:35:01 PSQ110 postfix/qmgr[15159]: C3EDC5800B4: from=<[email protected]>, size=607, nrcpt=1 (queue active)
Mar 13 16:35:05 PSQ110 postfix/smtp[15729]: C3EDC5800B4: to=<[email protected]>, relay=gmail-smtp-in.l.google.com[74.125.130.26]:25, delay=4.1, delays=0.26/0/2.2/1.7, dsn=2.0.0, status=sent (250 2.0.0 OK 1425985505 f16si501651pdj.5 - gsmtp)
你可以考虑将 cron 的标准输出记录到日志中,以帮助你定位问题。这是一个你怎样使用 logger 命令重定向 cron 标准输出到 syslog的例子。用你的脚本来代替 echo 命令,helloCron 可以设置为任何你想要的应用程序的名字。
*/5 * * * * echo ‘Hello World’ 2>&1 | /usr/bin/logger -t helloCron
它创建的日志条目:
Apr 28 22:20:01 ip-172-31-11-231 CRON[15296]: (ubuntu) CMD (echo 'Hello World!' 2>&1 | /usr/bin/logger -t helloCron)
Apr 28 22:20:01 ip-172-31-11-231 helloCron: Hello World!
每个 cron 任务将根据任务的具体类型以及如何输出数据来记录不同的日志。
希望在日志中有问题根源的线索,也可以根据需要添加额外的日志记录。
via: http://www.loggly.com/ultimate-guide/logging/troubleshooting-with-linux-logs/
作者:Jason Skowronski 作者:Amy Echeverri 作者:Sadequl Hussain 译者:strugglingyouth 校对:wxy