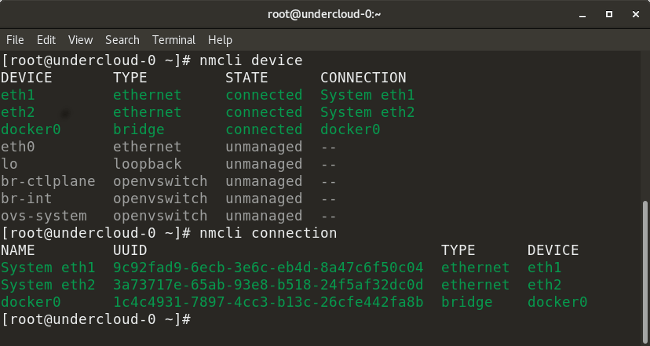
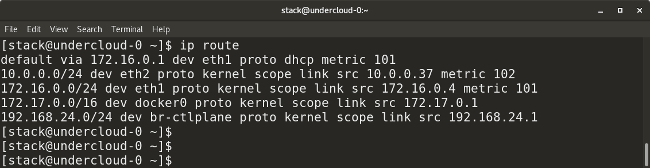
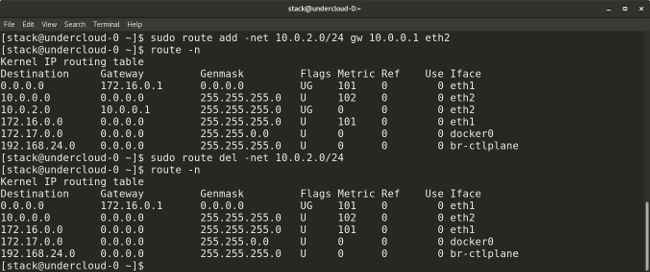
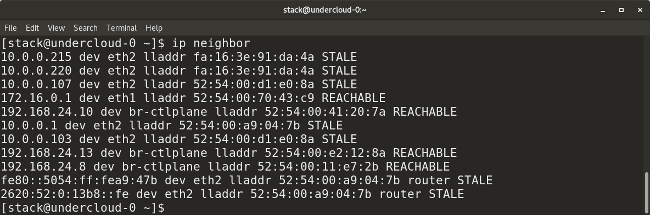
了解 Ansible 的功能,这是一个无代理的、可扩展的配置管理系统。
网络自动化
随着 IT 行业的技术变化,从服务器虚拟化到公有云和私有云,以及自服务能力、容器化应用、平台即服务(PaaS)交付,而一直以来落后的一个领域就是网络。
在过去的五年多,网络行业似乎有很多新的趋势出现,它们中的很多被归入到 软件定义网络 (SDN)。
注意:
SDN 是新出现的一种构建、管理、操作和部署网络的方法。SDN 最初的定义是出于将控制层和数据层(包转发)物理分离的需要,并且,解耦合的控制层必须管理好各自的设备。
如今,在 SDN 旗下已经有许多技术,包括 基于控制器的网络 、网络设备 API、网络自动化、 白盒交换机 、策略网络化、 网络功能虚拟化 (NFV)等等。
出于这篇报告的目的,我们参考 SDN 的解决方案作为我们的解决方案,其中包括一个网络控制器作为解决方案的一部分,并且提升了该网络的可管理性,但并不需要从数据层解耦控制层。
这些趋势的之一是,网络设备的 API 作为管理和操作这些设备的一种方法而出现,真正地提供了机器对机器的通讯。当需要自动化和构建网络应用时 API 简化了开发过程,在数据如何建模时提供了更多结构。例如,当启用 API 的设备以 JSON/XML 返回数据时,它是结构化的,并且比返回原生文本信息 —— 需要手工去解析的仅支持命令行的设备更易于使用。
在 API 之前,用于配置和管理网络设备的两个主要机制是命令行接口(CLI)和简单网络管理协议(SNMP)。让我们来了解一下它们,CLI 是一个设备的人机界面,而 SNMP 并不是为设备提供的实时编程接口。
幸运的是,因为很多供应商争相为设备增加 API,有时候 只是因为 它被放到需求建议书(RFP)中,这就带来了一个非常好的副作用 —— 支持网络自动化。当真正的 API 发布时,访问设备内数据的过程,以及管理配置,就会被极大简化,因此,我们将在本报告中对此进行评估。虽然使用许多传统方法也可以实现自动化,比如,CLI/SNMP。
注意:
随着未来几个月或几年(LCTT 译注:本文发表于 2016 年)的网络设备更新,供应商的 API 无疑应该被做为采购网络设备(虚拟和物理)的关键决策标准而测试和使用。如果供应商提供一些库或集成到自动化工具中,或者如果被用于一个开放的标准或协议,用户应该知道数据是如何通过设备建模的,API 使用的传输类型是什么。
总而言之,网络自动化,像大多数类型的自动化一样,是为了更快地工作。工作的更快是好事,减少部署和配置改变的时间并不总是许多 IT 组织需要去解决的问题。
包括速度在内,我们现在看看这些各种类型的 IT 组织逐渐采用网络自动化的几种原因。你应该注意到,同样的原则也适用于其它类型的自动化。
简化架构
今天,每个网络都是一片独特的“雪花”,并且,网络工程师们为能够通过一次性的网络改变来解决传输和应用问题而感到自豪,而这最终导致网络不仅难以维护和管理,而且也很难去实现自动化。
网络自动化和管理需要从一开始就包含到新的架构和设计中去部署,而不是作为一个二级或三级项目。哪个特性可以跨不同的供应商工作?哪个扩展可以跨不同的平台工作?当使用具体的网络设备平台时,API 类型或者自动化工程是什么?当这些问题在设计过程之前得到答案,最终的架构将变成简单的、可重复的、并且易于维护 和 自动化的,在整个网络中将很少启用供应商专用的扩展。
确定的结果
在一个企业组织中, 改变审查会议 会评估面临的网络变化、它们对外部系统的影响、以及回滚计划。在人们通过 CLI 来执行这些 面临的变化 的世界上,输入错误的命令造成的影响是灾难性的。想像一下,一个有 3 位、4 位、5位,或者 50 位工程师的团队。每位工程师应对 面临的变化 都有他们自己的独特的方法。并且,在管理这些变化的期间,一个人使用 CLI 或者 GUI 的能力并不会消除和减少出现错误的机率。
使用经过验证的和测试过的网络自动化可以帮助实现更多的可预测行为,并且使执行团队更有可能实现确实性的结果,首次在保证任务没有人为错误的情况下正确完成的道路上更进一步。
业务灵活性
不用说,网络自动化不仅为部署变化提供了速度和灵活性,而且使得根据业务需要去从网络设备中检索数据的速度变得更快。自从服务器虚拟化到来以后,服务器和虚拟化使得管理员有能力在瞬间去部署一个新的应用程序。而且,随着应用程序可以更快地部署,随之浮现的问题是为什么还需要花费如此长的时间配置一个 VLAN(虚拟局域网)、路由器、FW ACL(防火墙的访问控制列表)或者负载均衡策略呢?
通过了解在一个组织内最常见的工作流和 为什么 真正需要改变网络,部署如 Ansible 这样的现代的自动化工具将使这些变得非常简单。
这一章介绍了一些关于为什么应该去考虑网络自动化的高级知识点。在下一节,我们将带你去了解 Ansible 是什么,并且继续深入了解各种不同规模的 IT 组织的网络自动化的不同类型。
什么是 Ansible?
Ansible 是存在于开源世界里的一种最新的 IT 自动化和配置管理平台。它经常被拿来与其它工具如 Puppet、Chef 和 SaltStack 去比较。Ansible 作为一个由 Michael DeHaan 创建的开源项目出现于 2012 年,Michael DeHaan 也创建了 Cobbler 和 cocreated Func,它们在开源社区都非常流行。在 Ansible 开源项目创建之后不足 18 个月时间, Ansilbe 公司成立,并收到了六百万美金 A 轮投资。该公司成为 Ansible 开源项目排名第一的贡献者和支持者,并一直保持着。在 2015 年 10 月,Red Hat 收购了 Ansible 公司。
但是,Ansible 到底是什么?
Ansible 是一个无需代理和可扩展的超级简单的自动化平台。
让我们更深入地了解它的细节,并且看一看那些使 Ansible 在行业内获得广泛认可的属性。
简单
Ansible 的其中一个吸引人的属性是,使用它你 不 需要特定的编程技能。所有的指令,或者说任务都是自动化的,以一个标准的、任何人都可以理解的人类可读的数据格式的文档化。在 30 分钟之内完成安装和自动化任务的情况并不罕见!
例如,下列来自一个 Ansible 剧本 的任务用于去确保在一个 VLAN 存在于一个 Cisco Nexus 交换机中:
- nxos_vlan: vlan_id=100 name=web_vlan
你无需熟悉或写任何代码就可以明确地看出它将要做什么!
注意:
这个报告的下半部分涉到 Ansible 术语( 剧本 、 剧集 、 任务 、 模块 等等)的细节。在我们使用 Ansible 进行网络自动化时,提及这些关键概念时我们会有一些简短的示例。
无代理
如果你看过市面上的其它工具,比如 Puppet 和 Chef,你会发现,一般情况下,它们要求每个实现自动化的设备必须安装特定的软件。这种情况在 Ansible 上 并不需要,这就是为什么 Ansible 是实现网络自动化的最佳选择的主要原因。
这很好理解,那些 IT 自动化工具,包括 Puppet、Chef、CFEngine、SaltStack、和 Ansible,它们最初构建是为管理和自动化配置 Linux 主机,以跟得上部署的应用程序增长的步伐。因为 Linux 系统是被配置成自动化的,要安装代理并不是一个技术难题。如果有的话,它也只会延误安装过程,因为,现在有 N 多个(你希望去实现自动化的)主机需要在它们上面部署软件。
再加上,当使用代理时,它们需要的 DNS 和 NTP 配置更加复杂。这些都是大多数环境中已经配置好的服务,但是,当你希望快速地获取一些东西或者只是简单地想去测试一下它能做什么的时候,它将极大地耽误整个设置和安装的过程。
由于本报告只是为介绍利用 Ansible 实现网络自动化,我们希望指出,Ansible 作为一个无代理平台,对于网络管理员来说,其比对系统管理员更具有吸引力。这是为什么呢?
正如前面所说的那样,对网络管理员来说,它是非常有吸引力的,Linux 操作系统是开源的,并且,任何东西都可以安装在它上面。对于网络来说,却并非如此,虽然它正在逐渐改变。如果我们更广泛地部署网络操作系统,如 Cisco IOS,它就是这样的一个例子,并且问一个问题, “第三方软件能否部署在基于 IOS (LCTT 译注:此处的 IOS,指的是思科的网络操作系统 IOS)的平台上吗?”毫无疑问,它的回答是 NO。
在过去的二十多年里,几乎所有的网络操作系统都是闭源的,并且,垂直整合到底层的网络硬件中。没有供应商的支持,在一个网络设备中(路由器、交换机、负载均衡、防火墙、等等)载入一个代理并不那么轻松。有一个像 Ansible 这样的自动化平台,从头开始去构建一个无代理、可扩展的自动化平台,就像是它专门为网络行业订制的一样。我们最终将开始减少并消除与网络的人工交互。
可扩展
Ansible 的可扩展性也非常的好。从开源、代码开始在网络行业中发挥重要的作用时起,有一个可扩展的平台是必需的。这意味着如果供应商或社区不提供一个特定的特性或功能,开源社区、终端用户、消费者、顾问,或者任何的人能够 扩展 Ansible 来启用一个给定的功能集。过去,网络供应商或者工具供应商通过一个 hook 去提供新的插件和集成。想像一下,使用一个像 Ansible 这样的自动化平台,并且,你选择的网络供应商发布了你 真正 需要的一个自动化的新特性。从理论上说,网络供应商或者 Ansible 可以发行一个新的插件去实现自动化这个独特的特性,这是一件非常好的事情,从你的内部工程师到你的增值分销商(VAR)或者你的顾问中的任何一个人,都可以去提供这种集成。
正如前面所说的那样,Ansible 实际上是极具扩展性的,Ansible 最初就是为自动化应用程序和系统构建的。这是因为,Ansible 的可扩展性来自于其集成性是为网络供应商编写的,包括但不限于 Cisco、Arista、Juniper、F5、HP、A10、Cumulus 和 Palo Alto Networks。
对于网络自动化,为什么要使用 Ansible?
我们已经简单了解除了 Ansible 是什么,以及一些网络自动化的好处,但是,对于网络自动化,我们为什么要使用 Ansible?
大家很清楚,使得 Ansible 成为如此伟大的一个自动化应用部署平台的许多原因已经被大家所提及了。但是,我们现在要深入一些,更多地关注于网络,并且继续总结一些更需要注意的其它关键点。
无代理
在实现网络自动化的时候,无代理架构的重要性并不是重点强调的,特别是当它适用于现有的自动化设备时。如果,我们看一下当前网络中已经安装的各种设备时,从 DMZ 和园区,到分支机构和数据中心,最大份额的设备 并不 具有最新 API 的设备。从自动化的角度来看,API 可以使做一些事情变得很简单,像 Ansible 这样的无代理平台有可能去自动化和管理那些 老旧(传统) 的设备。例如,基于 CLI 的设备,它的工具可以被用于任何网络环境中。
注意:
如果仅支持 CLI 的设备已经集成进 Ansible,它的机制就像是,怎么在设备上通过协议如 telnet、SSH 和 SNMP 去进行只读访问和读写操作。
作为一个独立的网络设备,像路由器、交换机、和防火墙正在持续去增加 API 的支持,SDN 解决方案也正在出现。SDN 解决方案的其中一个常见主题是,它们都提供一个单点集成和策略管理,通常是以一个 SDN 控制器的形式出现。这对于 Cisco ACI、VMware NSX、Big Switch Big Cloud Fabric 和 Juniper Contrail,以及其它的 SDN 提供者,比如 Nuage、Plexxi、Plumgrid、Midokura 和 Viptela,是一个真实的解决方案。这甚至包含开源的控制器,比如 OpenDaylight。
所有的这些解决方案都简化了网络管理,就像它们可以让一个管理员开始从“box-by-box”管理(LCTT 译者注:指的是单个设备挨个去操作的意思)迁移到网络范围的管理。这是在正确方向上迈出的很大的一步,这些解决方案并不能消除在变更期间中人类犯错的机率。例如,比起配置 N 个交换机,你可能需要去配置一个单个的 GUI,它需要很长的时间才能实现所需要的配置改变 —— 它甚至可能更复杂,毕竟,相对于一个 CLI,他们更喜欢 GUI!另外,你可能有不同类型的 SDN 解决方案部署在每个应用程序、网络、区域或者数据中心。
在需要自动化的网络中,对于配置管理、监视和数据收集,当行业开始向基于控制器的网络架构中迁移时,这些需求并不会消失。
大量的软件定义网络中都部署有控制器,几乎所有的控制器都 提供 一个最新的 REST API。并且,因为 Ansible 是一个无代理架构,它实现自动化是非常简单的,而不仅仅是对那些没有 API 的传统设备,但也有通过 REST API 的软件定义网络解决方案,在所有的终端上不需要有额外的软件(LCTT 译注:指的是代理)。最终的结果是,使用 Ansible,无论有或没有 API,可以使任何类型的设备都能够自动化。
自由开源软件(FOSS)
Ansible 是一个开源软件,它的全部代码在 GitHub 上都是公开可访问的,使用 Ansible 是完全免费的。它可以在几分钟内完成安装并为网络工程师提供有用的价值。Ansible 这个开源项目,或者 Ansible 公司,在它们交付软件之前,你不会遇到任何一个销售代表。那是显而易见的事实,因为它是一个真正的开源项目,但是,作为开源的、社区驱动的软件项目在网络行业中的使用是非常少的,但是,也在逐渐增加,我们想明确指出这一点。
同样需要指出的一点是,Ansible, Inc. 也是一个公司,它也需要去赚钱,对吗?虽然 Ansible 是开源的,它也有一个叫 Ansible Tower 的企业产品,它增加了一些特性,比如,基于规则的访问控制(RBAC)、报告、 web UI、REST API、多租户等等,(相比 Ansible)它更适合于企业去部署。并且,更重要的是,Ansible Tower 甚至可以最多在 10 台设备上 免费 使用,至少,你可以去体验一下,它是否会为你的组织带来好处,而无需花费一分钱,并且,也不需要与无数的销售代表去打交道。
可扩展性
我们在前面说过,Ansible 主要是为部署 Linux 应用程序而构建的自动化平台,虽然从早期开始已经扩展到 Windows。需要指出的是,Ansible 开源项目并没有“自动化网络基础设施”的目标。事实上是,Ansible 社区更明白如何在底层的 Ansible 架构上更具灵活性和可扩展性,对于他们的自动化需要(包括网络)更容易成为一个 扩展 的 Ansible。在过去的两年中,部署有许多的 Ansible 集成,许多是有行业独立人士进行的,比如,Matt Oswalt、Jason Edelman、Kirk Byers、Elisa Jasinska、David Barroso、Michael Ben-Ami、Patrick Ogenstad 和 Gabriele Gerbino,也有网络系统供应商的领导者,比如,Arista、Juniper、Cumulus、Cisco、F5、和 Palo Alto Networks。
集成到已存在的 DevOps 工作流中
Ansible 在 IT 组织中被用于应用程序部署。它被用于需要管理部署、监视和管理各种类型的应用程序的运维团队中。通过将 Ansible 集成到网络基础设施中,当新应用程序到来或迁移后,它扩展了可能的范围。而不是去等待一个新的顶架交换机(LCTT 译注:TOR,一种数据中心设备接入的方式)的到来、去添加一个 VLAN、或者去检查接口的速度/双工,所有的这些以网络为中心的任务都可以被自动化,并且可以集成到 IT 组织内已经存在的工作流中。
幂等性
术语 幂等性 (读作 item-potency)经常用于软件开发的领域中,尤其是当使用 REST API 工作的时候,以及在 DevOps 自动化和配置管理框架的领域中,包括 Ansible。Ansible 的其中一个信念是,所有的 Ansible 模块(集成的)应该是幂等的。那么,对于一个模块来说,幂等是什么意思呢?毕竟,对大多数网络工程师来说,这是一个新的术语。
答案很简单。幂等性的本质是允许定义的任务,运行一次或者上千次都不会在目标系统上产生不利影响,仅仅是一种一次性的改变。换句话说,如果有一个要做的改变去使系统进入到它期望的状态,这种改变完成之后,并且,如果这个设备已经达到这种状态,就不会再发生改变。这不像大多数传统的定制脚本和拷贝、黏贴到那些终端窗口中的 CLI 命令。当相同的命令或者脚本在同一个系统上重复运行,(有时候)会出现错误。即使是粘贴一组命令到一个路由器中,也可能会遇到一些使你的其余的配置失效的错误。好玩吧?
另外的例子是,如果你有一个配置 10 个 VLAN 的文件文件或者脚本,那么 每次 运行这个脚本,相同的命令命令会被输入 10 次。如果使用一个幂等的 Ansible 模块,首先会从网络设备中采集已存在的配置,并且,每个新的 VLAN 被配置后会再次检查当前配置。仅仅当这个新的 VLAN 需要被添加(或者,比如说改变 VLAN 名字)是一个变更,命令才会真实地推送到设备。
当一个技术越来越复杂,幂等性的价值就越高,在你修改的时候,你并不能注意到 已存在 的网络设备的状态,而仅仅是从一个网络配置和策略角度去尝试达到 期望的 状态。
网络范围的和临时(Ad Hoc)的改变
用配置管理工具解决的其中一个问题是,配置“飘移”(当设备的期望配置逐渐漂移,或者改变,随着时间的推移,手动改变和/或在一个环境中使用了多个不同的工具),事实上,这也是像 Puppet 和 Chef 所使用的地方。代理商 电联 到前端服务器,验证它的配置,并且,如果需要变更,则改变它。这个方法是非常简单的。如果有故障了,需要去排除怎么办?你通常需要跳过管理系统,直接连到设备,找到并修复它,然后,马上离开,对不对?果然,在下次当代理电连回来,这个修复问题的改变被覆盖了(基于主/前端服务器是怎么配置的)。在高度自动化的环境中,一次性的改变应该被限制,但是,仍然允许使用它们(LCTT 译注:指的是一次性改变)的工具是非常有价值的。正如你想到的,其中一个这样的工具是 Ansible。
因为 Ansible 是无代理的,这里并没有一个默认的推送或者拉取去防止配置漂移。自动化任务被定义在 Ansible <ruby剧本playbook中,当使用 Ansible 时,它让用户去运行剧本。如果剧本在一个给定的时间间隔内运行,并且你没有用 Ansible Tower,你肯定知道任务的执行频率;如果你只是在终端提示符下使用一个原生的 Ansible 命令行,那么该剧本就运行一次,并且仅运行一次。
缺省运行一次的剧本对网络工程师是很具有吸引力的,让人欣慰的是,在设备上手动进行的改变不会自动被覆盖。另外,当需要的时候,一个剧本所运行的设备范围很容易被改变,即使是对一个单个设备进行自动化的单次变更,Ansible 仍然可以用,设备的 范围 由一个被称为 Ansible 清单 的文件决定;这个清单可以是一台设备或者是一千台设备。
下面展示的一个清单文件示例,它定义了两组共六台设备:
[core-switches]
dc-core-1
dc-core-2
[leaf-switches]
leaf1
leaf2
leaf3
leaf4
为了自动化所有的主机,你的剧本中的 剧集 定义的一个片段看起来应该是这样的:
hosts: all
并且,要只自动化一个叶子节点交换机,它看起来应该像这样:
hosts: leaf1
这是一个核心交换机:
hosts: core-switches
注意
正如前面所说的那样,这个报告的后面部分将详细介绍剧本、剧集、和清单。
因为能够很容易地对一台设备或者 N 台设备进行自动化,所以在需要对这些设备进行一次性变更时,Ansible 成为了最佳的选择。在网络范围内的变更它也做的很好:可以是关闭给定类型的所有接口、配置接口描述、或者是在一个跨企业园区布线的网络中添加 VLAN。
使用 Ansible 实现网络任务自动化
这个报告从两个方面逐渐深入地讲解一些技术。第一个方面是围绕 Ansible 架构和它的细节,第二个方面是,从一个网络的角度,讲解使用 Ansible 可以完成什么类型的自动化。在这一章中我们将带你去详细了解第二方面的内容。
自动化一般被认为是速度快,但是,考虑到一些任务并不要求速度,这就是为什么一些 IT 团队没有认识到自动化的价值所在。VLAN 配置是一个非常好的例子,因为,你可能会想,“创建一个 VLAN 到底有多快?一般情况下每天添加多少个 VLAN?我真的需要自动化吗?”
在这一节中,我们专注于另外几种有意义的自动化任务,比如,设备准备、数据收集、报告和遵从情况。但是,需要注意的是,正如我们前面所说的,自动化为你、你的团队、以及你的精确的更可预测的结果和更多的确定性,提供了更快的速度和敏捷性。
设备准备
为网络自动化开始使用 Ansible 的最容易也是最快的方法是,为设备的最初投入使用创建设备配置文件,并且将配置文件推送到网络设备中。
如果我们去完成这个过程,它将分解为两步,第一步是创建一个配置文件,第二步是推送这个配置到设备中。
首先,我们需要去从供应商配置文件的底层专用语法(CLI)中解耦 输入。这意味着我们需要对配置参数中分离出文件和值,比如,VLAN、域信息、接口、路由、和其它的内容等等,然后,当然是一个配置的模块文件。在这个示例中,这里有一个标准模板,它可以用于所有设备的初始部署。Ansible 将帮助提供配置模板中需要的输入和值之间的部分。几秒钟之内,Ansible 可以生成数百个可靠的和可预测的配置文件。
让我们快速的看一个示例,它使用当前的配置,并且分解它到一个模板和单独的一个(作为一个输入源的)变量文件中。
这是一个配置文件片断的示例:
hostname leaf1
ip domain-name ntc.com
!
vlan 10
name web
!
vlan 20
name app
!
vlan 30
name db
!
vlan 40
name test
!
vlan 50
name misc
如果我们提取输入值,这个文件将被转换成一个模板。
注意:
Ansible 使用基于 Python 的 Jinja2 模板化语言,因此,这个被命名为 leaf.j2 的文件是一个 Jinja2 模板。
注意,下列的示例中,双大括号({{}}) 代表一个变量。
模板看起来像这些,并且给它命名为 leaf.j2:
!
hostname {{ inventory_hostname }}
ip domain-name {{ domain_name }}
!
!
{% for vlan in vlans %}
vlan {{ vlan.id }}
name {{ vlan.name }}
{% endfor %}
!
因为双大括号代表变量,并且,我们看到这些值并不在模板中,所以它们需要将值保存在一个地方。值被保存在一个变量文件中。正如前面所说的,一个相应的变量文件看起来应该是这样的:
---
hostname: leaf1
domain_name: ntc.com
vlans:
- { id: 10, name: web }
- { id: 20, name: app }
- { id: 30, name: db }
- { id: 40, name: test }
- { id: 50, name: misc }
这意味着,如果管理 VLAN 的团队希望在网络设备中添加一个 VLAN,很简单,他们只需要在变量文件中改变它,然后,使用 Ansible 中一个叫 template 的模块,去重新生成一个新的配置文件。这整个过程也是幂等的;仅仅是在模板或者值发生改变时,它才会去生成一个新的配置文件。
一旦配置文件生成,它需要去 推送 到网络设备。推送配置文件到网络设备使用一个叫做 napalm_install_config的开源的 Ansible 模块。
接下来的示例是一个 构建并推送 一个配置文件到网络设备的简单剧本。同样地,该剧本使用一个名叫 template 的模块去构建配置文件,然后使用一个名叫 napalm_install_config 的模块去推送它们,并且激活它作为设备上运行的新的配置文件。
虽然没有详细解释示例中的每一行,但是,你仍然可以看明白它们实际上做了什么。
注意:
下面的剧本介绍了新的概念,比如,内置变量 inventory_hostname。这些概念包含在 Ansible 术语和入门 中。
---
- name: BUILD AND PUSH NETWORK CONFIGURATION FILES
hosts: leaves
connection: local
gather_facts: no
tasks:
- name: BUILD CONFIGS
template:
src=templates/leaf.j2
dest=configs/{{inventory_hostname }}.conf
- name: PUSH CONFIGS
napalm_install_config:
hostname={{ inventory_hostname }}
username={{ un }}
password={{ pwd }}
dev_os={{ os }}
config_file=configs/{{ inventory_hostname }}.conf
commit_changes=1
replace_config=0
这个两步的过程是一个使用 Ansible 进行网络自动化入门的简单方法。通过模板简化了你的配置,构建配置文件,然后,推送它们到网络设备 — 因此,被称为 BUILD 和 PUSH 方法。
注意:
像这样的更详细的例子,请查看 Ansible 网络集成。
数据收集和监视
监视工具一般使用 SNMP —— 这些工具拉取某些管理信息库(MIB),然后给监视工具返回数据。基于返回的数据,它可能多于也可能少于你真正所需要的数据。如果接口基于返回的数据统计你正在拉取的内容,你可能会返回在 show interface 命令中显示的计数器。如果你仅需要 interface resets 并且,希望去看到与重置相关的邻接 CDP/LLDP 的接口,那该怎么做呢?当然,这也可以使用当前的技术;可以运行多个显示命令去手动解析输出信息,或者,使用基于 SNMP 的工具,在 GUI 中切换不同的选项卡(Tab)找到真正你所需要的数据。Ansible 怎么能帮助我们去完成这些工作呢?
由于 Ansible 是完全开源并且是可扩展的,它可以精确地去收集和监视所需要的计数器或者值。这可能需要一些预先的定制工作,但是,最终这些工作是非常有价值的。因为采集的数据是你所需要的,而不是供应商提供给你的。Ansible 也提供了执行某些条件任务的直观方法,这意味着基于正在返回的数据,你可以执行子任务,它可以收集更多的数据或者产生一个配置改变。
网络设备有 许多 统计和隐藏在里面的临时数据,而 Ansible 可以帮你提取它们。
你甚至可以在 Ansible 中使用前面提到的 SNMP 的模块,模块的名字叫 snmp_device_version。这是在社区中存在的另一个开源模块:
- name: GET SNMP DATA
snmp_device_version:
host=spine
community=public
version=2c
运行前面的任务返回非常多的关于设备的信息,并且添加一些级别的发现能力到 Ansible中。例如,那个任务返回下列的数据:
{"ansible_facts": {"ansible_device_os": "nxos", "ansible_device_vendor": "cisco", "ansible_device_version": "7.0(3)I2(1)"}, "changed": false}
你现在可以决定某些事情,而不需要事先知道是什么类型的设备。你所需要知道的仅仅是设备的只读通讯字符串。
迁移
从一个平台迁移到另外一个平台,可能是从同一个供应商或者是从不同的供应商,迁移从来都不是件容易的事。供应商可能提供一个脚本或者一个工具去帮助你迁移。Ansible 可以被用于去为所有类型的网络设备构建配置模板,然后,操作系统用这个方法去为所有的供应商生成一个配置文件,然后作为一个(通用数据模型的)输入设置。当然,如果有供应商专用的扩展,它也是会被用到的。这种灵活性不仅对迁移有帮助,而且也可以用于 灾难恢复 (DR),它在生产系统中不同的交换机型号之间和灾备数据中心中是经常使用的,即使是在不同的供应商的设备上。
配置管理
正如前面所说的,配置管理是最常用的自动化类型。Ansible 可以很容易地做到创建 角色 去简化基于任务的自动化。从更高的层面来看,角色是指针对一个特定设备组的可重用的自动化任务的逻辑分组。关于角色的另一种说法是,认为角色就是相关的 工作流 。首先,在开始自动化添加值之前,需要理解工作流和过程。不论是开始一个小的自动化任务还是扩展它,理解工作流和过程都是非常重要的。
例如,一组自动化地配置路由器和交换机的任务是非常常见的,并且它们也是一个很好的起点。但是,配置在哪台网络设备上?配置的 IP 地址是什么?或许需要一个 IP 地址管理方案?一旦用一个给定的功能分配了 IP 地址并且已经部署,DNS 也更新了吗?DHCP 的范围需要创建吗?
你可以看到工作流是怎么从一个小的任务开始,然后逐渐扩展到跨不同的 IT 系统?因为工作流持续扩展,所以,角色也一样(持续扩展)。
遵从性
和其它形式的自动化工具一样,用任何形式的自动化工具产生配置改变都被视为风险。手工去产生改变可能看上去风险更大,正如你看到的和亲身经历过的那样,Ansible 有能力去做自动数据收集、监视、和配置构建,这些都是“只读的”和“低风险”的动作。其中一个 低风险 使用案例是,使用收集的数据进行配置遵从性检查和配置验证。部署的配置是否满足安全要求?是否配置了所需的网络?协议 XYZ 禁用了吗?因为每个模块、或者用 Ansible 返回数据的整合,它只是非常简单地 声明 那些事是 TRUE 还是 FALSE。然后接着基于 它 是 TRUE 或者是 FALSE, 接着由你决定应该发生什么 —— 或许它只是被记录下来,或者,也可能执行一个复杂操作。
报告
我们现在知道,Ansible 也可以用于去收集数据和执行遵从性检查。Ansible 可以根据你想要做的事情去从设备中返回和收集数据。或许返回的数据成为其它的任务的输入,或者你想去用它创建一个报告。从模板中生成报告,并将真实的数据插入到模板中,创建和使用报告模板的过程与创建配置模板的过程是相同的。
从一个报告的角度看,这些模板或许是纯文本文件,就像是在 GitHub 上看到的 markdown 文件、放置在 Web 服务器上的 HTML 文件,等等。用户有权去创建一个她希望的报告类型,插入她所需要的真实数据到报告中。
创建报告的用处很多,不仅是为行政管理,也为了运营工程师,因为它们通常有双方都需要的不同指标。
Ansible 怎么工作
从一个网络自动化的角度理解了 Ansible 能做什么之后,我们现在看一下 Ansible 是怎么工作的。你将学习到从一个 Ansible 管理主机到一个被自动化的节点的全部通讯流。首先,我们回顾一下,Ansible 是怎么 开箱即用 的,然后,我们看一下 Ansible 怎么去做到的,具体说就是,当网络设备自动化时,Ansible 模块是怎么去工作的。
开箱即用
到目前为止,你已经明白了,Ansible 是一个自动化平台。实际上,它是一个安装在一台单个服务器上或者企业中任何一位管理员的笔记本中的轻量级的自动化平台。当然,(安装在哪里?)这是由你来决定的。在基于 Linux 的机器上,使用一些实用程序(比如 pip、apt、和 yum)安装 Ansible 是非常容易的。
注意:
在本报告的其余部分,安装 Ansible 的机器被称为 控制主机 。
控制主机将执行定义在 Ansible 的 剧本 (不用担心,稍后我们将讲到剧本和其它的 Ansible 术语)中的所有自动化任务。现在,我们只需要知道,一个剧本是简单的一组自动化任务和在给定数量的主机上执行的指令。
当一个剧本创建之后,你还需要去定义它要自动化的主机。映射一个剧本和要自动化运行的主机,是通过一个被称为 Ansible 清单 的文件。这是一个前面展示的示例,但是,这里是同一个清单文件的另外两个组:cisco 和 arista:
[cisco]
nyc1.acme.com
nyc2.acme.com
[arista]
sfo1.acme.com
sfo2.acme.com
注意:
你也可以在清单文件中使用 IP 地址,而不是主机名。对于这样的示例,主机名将是通过 DNS 可解析的。
正如你所看到的,Ansible 清单文件是一个文本文件,它列出了主机和主机组。然后,你可以在剧本中引用一个具体的主机或者组,以此去决定对给定的 剧集 和剧本在哪台主机上进行自动化。下面展示了两个示例。
展示的第一个示例它看上去像是,你想去自动化 cisco 组中所有的主机,而展示的第二个示例只对 nyc1.acme.com 主机进行自动化:
---
- name: TEST PLAYBOOK
hosts: cisco
tasks:
- TASKS YOU WANT TO AUTOMATE
---
- name: TEST PLAYBOOK
hosts: nyc1.acme.com
tasks:
- TASKS YOU WANT TO AUTOMATE
现在,我们已经理解了基本的清单文件,我们可以看一下(在控制主机上的)Ansible 是怎么与 开箱即用 的设备通讯的,和在 Linux 终端上自动化的任务。这里需要明白一个重要的观点就是,需要去自动化的网络设备通常是不一样的。(LCTT 译注:指的是设备的类型、品牌、型号等等)
Ansible 对基于 Linux 的系统去开箱即用自动化工作有两个要求。它们是 SSH 和 Python。
首先,终端必须支持 SSH 传输,因为 Ansible 使用 SSH 去连接到每个目标节点。因为 Ansible 支持一个可拔插的连接架构,也有各种类型的插件去实现不同类型的 SSH。
第二个要求是,Ansible 并不要求在目标节点上预先存在一个 代理,Ansible 并不要求一个软件代理,它仅需要一个内置的 Python 执行引擎。这个执行引擎用于去执行从 Ansible 管理主机发送到被自动化的目标节点的 Python 代码。
如果我们详细解释这个开箱即用工作流,它将分解成如下的步骤:
- 当执行一个 Ansible 剧集时,控制主机使用 SSH 连接到基于 Linux 的目标节点。
- 对于每个任务,也就是说,Ansible 模块将在这个剧集中被执行,通过 SSH 发送 Python 代码并直接在远程系统中执行。
- 在远程系统上运行的每个 Ansible 模块将返回 JSON 数据到控制主机。这些数据包含有信息,比如,配置改变、任务成功/失败、以及其它模块特定的数据。
- JSON 数据返回给 Ansible,然后被用于去生成报告,或者被用作接下来模块的输入。
- 在剧集中为每个任务重复第 3 步。
- 在剧本中为每个剧集重复第 1 步。
是不是意味着每个网络设备都可以被 Ansible 开箱即用?因为它们也都支持 SSH,确实,网络设备都支持 SSH,但是,第一个和第二要求的组合限制了网络设备可能的功能。
刚开始时,大多数网络设备并不支持 Python,因此,使用默认的 Ansible 连接机制是无法进行的。换句话说,在过去的几年里,供应商在几个不同的设备平台上增加了 Python 支持。但是,这些平台中的大多数仍然缺乏必要的集成,以允许 Ansible 去直接通过 SSH 访问一个 Linux shell,并以适当的权限去拷贝所需的代码、创建临时目录和文件、以及在设备中执行代码。尽管 Ansible 中所有的这些部分都可以在基于 Linux 的网络设备上使用 SSH/Python 在本地运行,它仍然需要网络设备供应商去更进一步开放他们的系统。
注意:
值的注意的是,Arista 确实也提供了原生的集成,因为它可以无需 SSH 用户,直接进入到一个 Linux shell 中访问 Python 引擎,它可以允许 Ansible 去使用其默认连接机制。因为我们调用了 Arista,我们也需要着重强调与 Ansible 默认连接机制一起工作的 Cumulus。这是因为 Cumulus Linux 是原生 Linux,并且它并不需要为 Cumulus Linux 操作系统使用供应商 API。
Ansible 网络集成
前面的节讲到过 Ansible 默认的工作方式。我们看一下,在开始一个 剧集 之后,Ansible 是怎么去设置一个到设备的连接、通过拷贝 Python 代码到设备、运行代码、和返回结果给 Ansible 控制主机来执行任务。
在这一节中,我们将看一看,当使用 Ansible 进行自动化网络设备时都做了什么。正如前面讲过的,Ansible 是一个可拔插的连接架构。对于 大多数 的网络集成, connection 参数设置为 local。在剧本中大多数的连接类型都设置为 local,如下面的示例所展示的:
---
- name: TEST PLAYBOOK
hosts: cisco
connection: local
tasks:
- TASKS YOU WANT TO AUTOMATE
注意在剧集中是怎么定义的,这个示例增加 connection 参数去和前面节中的示例进行比较。
这告诉 Ansible 不要通过 SSH 去连接到目标设备,而是连接到本地机器运行这个剧本。基本上,这是把连接职责委托给剧本中 任务 节中使用的真实的 Ansible 模块。每个模块类型的委托权利允许这个模块在必要时以各种形式去连接到设备。这可能是 Juniper 和 HP Comware7 的 NETCONF、Arista 的 eAPI、Cisco Nexus 的 NX-API、或者甚至是基于传统系统的 SNMP,它们没有可编程的 API。
注意:
网络集成在 Ansible 中是以 Ansible 模块的形式带来的。尽管我们持续使用术语来吊你的胃口,比如,剧本、剧集、任务、和讲到的关键概念模块,这些术语中的每一个都会在 Ansible 术语和入门 和 动手实践使用 Ansible 去进行网络自动化 中详细解释。
让我们看一看另外一个剧本的示例:
---
- name: TEST PLAYBOOK
hosts: cisco
connection: local
tasks:
- nxos_vlan: vlan_id=10 name=WEB_VLAN
你注意到了吗,这个剧本现在包含一个任务,并且这个任务使用了 nxos_vlan 模块。nxos_vlan 模块是一个 Python 文件,并且,在这个文件中它是使用 NX-API 连接到 Cisco 的 NX-OS 设备。可是,这个连接可能是使用其它设备 API 设置的,这就是为什么供应商和用户像我们这样能够去建立自己的集成的原因。集成(模块)通常是以 每特性 为基础完成的,虽然,你已经看到了像 napalm_install_config 这样的模块,它们也可以被用来 推送 一个完整的配置文件。
主要区别之一是使用的默认连接机制,Ansible 启动一个持久的 SSH 连接到设备,并且对于一个给定的剧集而已该连接将持续存在。当在一个模块中发生连接设置和拆除时,与许多使用 connection=local 的网络模块一样,对发生在剧集级别上的 每个 任务,Ansible 将登入/登出设备。
而在传统的 Ansible 形式下,每个网络模块返回 JSON 数据。仅有的区别是相对于目标节点,数据的推取发生在本地的 Ansible 控制主机上。相对于 每供应商 和模块类型,数据返回到剧本,但是作为一个示例,许多的 Cisco NX-OS 模块返回已存在的状态、建议状态、和最终状态,以及发送到设备的命令(如果有的话)。
作为使用 Ansible 进行网络自动化的开始,最重要的是,为 Ansible 的连接设备/拆除过程,记着去设置连接参数为 local,并且将它留在模块中。这就是为什么模块支持不同类型的供应商平台,它将与设备使用不同的方式进行通讯。
Ansible 术语和入门
这一章我们将介绍许多 Ansible 的术语和报告中前面部分出现过的关键概念。比如, 清单文件 、 剧本 、 剧集 、 任务 和 模块 。我们也会去回顾一些其它的概念,这些术语和概念对我们学习使用 Ansible 去进行网络自动化非常有帮助。
在这一节中,我们将引用如下的一个简单的清单文件和剧本的示例,它们将在后面的章节中持续出现。
清单示例 :
# sample inventory file
# filename inventory
[all:vars]
user=admin
pwd=admin
[tor]
rack1-tor1 vendor=nxos
rack1-tor2 vendor=nxos
rack2-tor1 vendor=arista
rack2-tor2 vendor=arista
[core]
core1
core2
剧本示例 :
---
# sample playbook
# filename site.yml
- name: PLAY 1 - Top of Rack (TOR) Switches
hosts: tor
connection: local
tasks:
- name: ENSURE VLAN 10 EXISTS ON CISCO TOR SWITCHES
nxos_vlan:
vlan_id=10
name=WEB_VLAN
host={{ inventory_hostname }}
username=admin
password=admin
when: vendor == "nxos"
- name: ENSURE VLAN 10 EXISTS ON ARISTA TOR SWITCHES
eos_vlan:
vlanid=10
name=WEB_VLAN
host={{ inventory_hostname }}
username={{ user }}
password={{ pwd }}
when: vendor == "arista"
- name: PLAY 2 - Core (TOR) Switches
hosts: core
connection: local
tasks:
- name: ENSURE VLANS EXIST IN CORE
nxos_vlan:
vlan_id={{ item }}
host={{ inventory_hostname }}
username={{ user }}
password={{ pwd }}
with_items:
- 10
- 20
- 30
- 40
- 50
清单文件
使用一个清单文件,比如前面提到的那个,允许我们去为自动化任务指定主机、和使用每个剧集顶部节中(如果存在)的参数 hosts 所引用的主机/组指定的主机组。
它也可能在一个清单文件中存储变量。如这个示例中展示的那样。如果变量在同一行视为一台主机,它是一个具体主机变量。如果变量定义在方括号中([ ]),比如,[all:vars],它的意思是指变量在组中的范围 all,它是一个默认组,包含了清单文件中的 所有 主机。
注意:
清单文件是使用 Ansible 开始自动化的快速方法,但是,你应该已经有一个真实的网络设备源,比如一个网络管理工具或者 CMDB,它可以去创建和使用一个动态的清单脚本,而不是一个静态的清单文件。
剧本
剧本是去运行自动化网络设备的顶级对象。在我们的示例中,它是 site.yml 文件,如前面的示例所展示的。一个剧本使用 YAML 去定义一组自动化任务,并且,每个剧本由一个或多个剧集组成。这类似于一个橄榄球的剧本。就像在橄榄球赛中,团队有剧集组成的剧本,Ansible 的剧本也是由剧集组成的。
注意:
YAML 是一种被所有编程语言支持的数据格式。YAML 本身就是 JSON 的超集,并且,YAML 文件非常易于识别,因为它总是三个破折号(连字符)开始,比如,---。
剧集
一个 Ansible 剧本可以存在一个或多个剧集。在前面的示例中,它在剧本中有两个剧集。每个剧集开始的地方都有一个 头部,它定义了具体的参数。
示例中两个剧集都定义了下面的参数:
name
文件 PLAY 1 - Top of Rack (TOR) Switches 是任意内容的,它在剧本运行的时候,去改善剧本运行和报告期间的可读性。这是一个可选参数。
hosts
正如前面讲过的,这是在特定的剧集中要去进行自动化的主机或主机组。这是一个必需参数。
connection
正如前面讲过的,这是剧集连接机制的类型。这是个可选参数,但是,对于网络自动化剧集,一般设置为 local。
每个剧集都是由一个或多个任务组成。
任务
任务是以声明的方式去表示自动化的内容,而不用担心底层的语法或者操作是怎么执行的。
在我们的示例中,第一个剧集有两个任务。每个任务确保存在 10 个 VLAN。第一个任务是为 Cisco Nexus 设备的,而第二个任务是为 Arista 设备的:
tasks:
- name: ENSURE VLAN 10 EXISTS ON CISCO TOR SWITCHES
nxos_vlan:
vlan_id=10
name=WEB_VLAN
host={{ inventory_hostname }}
username=admin
password=admin
when: vendor == "nxos"
任务也可以使用 name 参数,就像剧集一样。和剧集一样,文本内容是任意的,并且当剧本运行时显示,去改善剧本运行和报告期间的可读性。它对每个任务都是可选参数。
示例任务中的下一行是以 nxos_vlan 开始的。它告诉我们这个任务将运行一个叫 nxos_vlan 的 Ansible 模块。
现在,我们将进入到模块中。
模块
在 Ansible 中理解模块的概念是至关重要的。虽然任何编辑语言都可以用来写 Ansible 模块,只要它们能够返回 JSON 键/值对即可,但是,几乎所有的模块都是用 Python 写的。在我们示例中,我们看到有两个模块被运行: nxos_vlan 和 eos_vlan。这两个模块都是 Python 文件;而事实上,在你不能看到剧本的时候,真实的文件名分别是 eos_vlan.py 和 nxos_vlan.py。
让我们看一下前面的示例中第一个剧集中的第一个任务:
- name: ENSURE VLAN 10 EXISTS ON CISCO TOR SWITCHES
nxos_vlan:
vlan_id=10
name=WEB_VLAN
host={{ inventory_hostname }}
username=admin
password=admin
when: vendor == "nxos"
这个任务运行 nxos_vlan,它是一个自动配置 VLAN 的模块。为了使用这个模块,包含它,你需要为设备指定期望的状态或者配置策略。这个示例中的状态是:VLAN 10 将被配置一个名字 WEB_VLAN,并且,它将被自动配置到每个交换机上。我们可以看到,使用 vlan_id 和 name 参数很容易做到。模块中还有三个其它的参数,它们分别是:host、username、和 password:
host
这是将要被自动化的主机名(或者 IP 地址)。因为,我们希望去自动化的设备已经被定义在清单文件中,我们可以使用内置的 Ansible 变量 inventory_hostname。这个变量等价于清单文件中的内容。例如,在第一个循环中,在清单文件中的主机是 rack1-tor1,然后,在第二个循环中,它是 rack1-tor2。这些名字是进入到模块的,并且包含在模块中的,在每个名字到 IP 地址的解析中,都发生一个 DNS 查询。然后与这个设备进行通讯。
username
用于登入到交换机的用户名。
password
用于登入到交换机的密码。
示例中最后的片断部分使用了一个 when 语句。这是在一个剧集中使用的 Ansible 的执行条件任务。正如我们所了解的,在这个剧集的 tor 组中有多个设备和设备类型。使用 when 基于任意标准去提供更多的选择。这里我们仅自动化 Cisco 设备,因为,我们在这个任务中使用了 nxos_vlan 模块,在下一个任务中,我们仅自动化 Arista 设备,因为,我们使用了 eos_vlan 模块。
注意:
这并不是区分设备的唯一方法。这里仅是演示如何使用 when,并且可以在清单文件中定义变量。
在清单文件中定义变量是一个很好的开端,但是,如果你继续使用 Ansible,你将会为了扩展性、版本控制、对给定文件的改变最小化而去使用基于 YAML 的变量。这也将简化和改善清单文件和每个使用的变量的可读性。在设备准备的构建/推送方法中讲过一个变量文件的示例。
在最后的示例中,关于任务有几点需要去搞清楚:
- 剧集 1 任务 1 展示了硬编码了
username 和 password 作为参数进入到具体的模块中(nxos_vlan)。 - 剧集 1 任务 1 和 剧集 2 在模块中使用了变量,而不是硬编码它们。这掩饰了
username 和 password 参数,但是,需要值得注意的是,(在这个示例中)这些变量是从清单文件中提取出现的。 - 剧集 1 中为进入到模块中的参数使用了一个 水平的 的 key=value 语法,虽然剧集 2 使用了垂直的 key=value 语法。它们都工作的非常好。你也可以使用垂直的 YAML “key: value” 语法。
- 最后的任务也介绍了在 Ansible 中怎么去使用一个循环。它通过使用
with_items 来完成,并且它类似于一个 for 循环。那个特定的任务是循环进入五个 VLAN 中去确保在交换机中它们都存在。注意:它也可能被保存在一个外部的 YAML 变量文件中。还需要注意的一点是,不使用 with_items 的替代方案是,每个 VLAN 都有一个任务 —— 如果这样做,它就失去了弹性!
动手实践使用 Ansible 去进行网络自动化
在前面的章节中,提供了 Ansible 术语的一个概述。它已经覆盖了大多数具体的 Ansible 术语,比如剧本、剧集、任务、模块和清单文件。这一节将继续提供示例去讲解使用 Ansible 实现网络自动化,而且将提供在不同类型的设备中自动化工作的模块的更多细节。示例中的将要进行自动化设备由多个供应商提供,包括 Cisco、Arista、Cumulus、和 Juniper。
在本节中的示例,假设的前提条件如下:
- Ansible 已经安装。
- 在设备中(NX-API、eAPI、NETCONF)适合的 APIs 已经启用。
- 用户在系统上有通过 API 去产生改变的适当权限。
- 所有的 Ansible 模块已经在系统中存在,并且也在库的路径变量中。
注意:
可以在 ansible.cfg 文件中设置模块和库路径。在你运行一个剧本时,你也可以使用 -M 标志从命令行中去改变它。
在本节中示例使用的清单如下。(删除了密码,IP 地址也发生了变化)。在这个示例中,(和前面的示例一样)某些主机名并不是完全合格域名(FQDN)。
清单文件
[cumulus]
cvx ansible_ssh_host=1.2.3.4 ansible_ssh_pass=PASSWORD
[arista]
veos1
[cisco]
nx1 hostip=5.6.7.8 un=USERNAME pwd=PASSWORD
[juniper]
vsrx hostip=9.10.11.12 un=USERNAME pwd=PASSWORD
注意:
正如你所知道的,Ansible 支持将密码存储在一个加密文件中的功能。如果你想学习关于这个特性的更多内容,请查看在 Ansible 网站上的文档中的 Ansible Vault 部分。
这个清单文件有四个组,每个组定义了一台单个的主机。让我们详细回顾一下每一节:
Cumulus
主机 cvx 是一个 Cumulus Linux (CL) 交换机,并且它是 cumulus 组中的唯一设备。记住,CL 是原生 Linux,因此,这意味着它是使用默认连接机制(SSH)连到到需要自动化的 CL 交换机。因为 cvx 在 DNS 或者 /etc/hosts 文件中没有定义,我们将让 Ansible 知道不要在清单文件中定义主机名,而是在 ansible_ssh_host 中定义的名字/IP。登陆到 CL 交换机的用户名被定义在 playbook 中,但是,你可以看到密码使用变量 ansible_ssh_pass 定义在清单文件中。
Arista
被称为 veos1 的是一台运行 EOS 的 Arista 交换机。它是在 arista 组中唯一的主机。正如你在 Arista 中看到的,在清单文件中并没有其它的参数存在。这是因为 Arista 为它们的设备使用了一个特定的配置文件。在我们的示例中它的名字为 .eapi.conf,它存在在 home 目录中。下面是正确使用配置文件的这个功能的示例:
[connection:veos1]
host: 2.4.3.4
username: unadmin
password: pwadmin
这个文件包含了定义在配置文件中的 Ansible 连接到设备(和 Arista 的被称为 pyeapi 的 Python 库)所需要的全部信息。
Cisco
和 Cumulus 和 Arista 一样,这里仅有一台主机(nx1)存在于 cisco 组中。这是一台 NX-OS-based Cisco Nexus 交换机。注意在这里为 nx1 定义了三个变量。它们包括 un 和 pwd,这是为了在 playbook 中访问和为了进入到 Cisco 模块去连接到设备。另外,这里有一个称为 hostip 的参数,它是必需的,因为,nx1 没有在 DNS 中或者是 /etc/hosts 配置文件中定义。
注意:
如果自动化一个原生的 Linux 设备,我们可以将这个参数命名为任何东西。ansible_ssh_host 被用于到如我们看到的那个 Cumulus 示例(如果在清单文件中的定义不能被解析)。在这个示例中,我们将一直使用 ansible_ssh_host,但是,它并不是必需的,因为我们将这个变量作为一个参数进入到 Cisco 模块,而 ansible_ssh_host 是在使用默认的 SSH 连接机制时自动检查的。
Juniper
和前面的三个组和主机一样,在 juniper 组中有一个单个的主机 vsrx。它在清单文件中的设置与 Cisco 相同,因为两者在 playbook 中使用了相同的方式。
剧本
接下来的剧本有四个不同的剧集。每个剧集是基于特定的供应商类型的设备组的自动化构建的。注意,那是在一个单个的剧本中执行这些任务的唯一的方法。这里还有其它的方法,它可以使用条件(when 语句)或者创建 Ansible 角色(它在这个报告中没有介绍)。
这里有一个剧本的示例:
---
- name: PLAY 1 - CISCO NXOS
hosts: cisco
connection: local
tasks:
- name: ENSURE VLAN 100 exists on Cisco Nexus switches
nxos_vlan:
vlan_id=100
name=web_vlan
host={{ hostip }}
username={{ un }}
password={{ pwd }}
- name: PLAY 2 - ARISTA EOS
hosts: arista
connection: local
tasks:
- name: ENSURE VLAN 100 exists on Arista switches
eos_vlan:
vlanid=100
name=web_vlan
connection={{ inventory_hostname }}
- name: PLAY 3 - CUMULUS
remote_user: cumulus
sudo: true
hosts: cumulus
tasks:
- name: ENSURE 100.10.10.1 is configured on swp1
cl_interface: name=swp1 ipv4=100.10.10.1/24
- name: restart networking without disruption
shell: ifreload -a
- name: PLAY 4 - JUNIPER SRX changes
hosts: juniper
connection: local
tasks:
- name: INSTALL JUNOS CONFIG
junos_install_config:
host={{ hostip }}
file=srx_demo.conf
user={{ un }}
passwd={{ pwd }}
logfile=deploysite.log
overwrite=yes
diffs_file=junpr.diff
你将注意到,前面的两个剧集是非常类似的,我们已经在最初的 Cisco 和 Arista 示例中讲过了。唯一的区别是每个要自动化的组(cisco and arista) 定义了它们自己的剧集,我们在前面介绍使用 when 条件时比较过。
这里有一个不正确的或者是错误的方式去做这些。这取决于你预先知道的信息是什么和适合你的环境和使用的最佳案例是什么,但我们的目的是为了展示做同一件事的几种不同的方法。
第三个剧集是在 Cumulus Linux 交换机的 swp1 接口上进行自动化配置。在这个剧集中的第一个任务是去确认 swp1 是一个三层接口,并且它配置的 IP 地址是 100.10.10.1。因为 Cumulus Linux 是原生的 Linux,网络服务在改变后需要重启才能生效。这也可以使用 Ansible 的操作来达到这个目的(这已经超出了本报告讨论的范围),这里有一个被称为 service 的 Ansible 核心模块来做这些,但它会中断交换机上的网络;使用 ifreload 重新启动则不会中断。
本节到现在为止,我们已经讲解了专注于特定任务的 Ansible 模块,比如,配置接口和 VLAN。第四个剧集使用了另外的选项。我们将看到一个 pushes 模块,它是一个完整的配置文件并且立即激活它作为正在运行的新的配置。这里将使用 napalm_install_config 来展示前面的示例,但是,这个示例使用了一个 Juniper 专用的模块。
junos_install_config 模块接受几个参数,如下面的示例中所展示的。到现在为止,你应该理解了什么是 user、passwd、和 host。其它的参数定义如下:
file:
这是一个从 Ansible 控制主机拷贝到 Juniper 设备的配置文件。
logfile:
这是可选的,但是,如果你指定它,它会被用于存储运行这个模块时生成的信息。
overwrite:
当你设置为 yes/true 时,完整的配置将被发送的配置覆盖。(默认是 false)
diffs_file:
这是可选的,但是,如果你指定它,当应用配置时,它将存储生成的差异。当应用配置时将存储一个生成的差异。当正好更改了主机名,但是,仍然发送了一个完整的配置文件时会生成一个差异,如下的示例:
# filename: junpr.diff
[edit system]
- host-name vsrx;
+ host-name vsrx-demo;
上面已经介绍了剧本概述的细节。现在,让我们看看当剧本运行时发生了什么:
注意:
-i 标志是用于指定使用的清单文件。也可以设置环境变量 ANSIBLE_HOSTS,而不用每次运行剧本时都去使用一个 -i 标志。
ntc@ntc:~/ansible/multivendor$ ansible-playbook -i inventory demo.yml
PLAY [PLAY 1 - CISCO NXOS] *************************************************
TASK: [ENSURE VLAN 100 exists on Cisco Nexus switches] *********************
changed: [nx1]
PLAY [PLAY 2 - ARISTA EOS] *************************************************
TASK: [ENSURE VLAN 100 exists on Arista switches] **************************
changed: [veos1]
PLAY [PLAY 3 - CUMULUS] ****************************************************
GATHERING FACTS ************************************************************
ok: [cvx]
TASK: [ENSURE 100.10.10.1 is configured on swp1] ***************************
changed: [cvx]
TASK: [restart networking without disruption] ******************************
changed: [cvx]
PLAY [PLAY 4 - JUNIPER SRX changes] ****************************************
TASK: [INSTALL JUNOS CONFIG] ***********************************************
changed: [vsrx]
PLAY RECAP ***************************************************************
to retry, use: --limit @/home/ansible/demo.retry
cvx : ok=3 changed=2 unreachable=0 failed=0
nx1 : ok=1 changed=1 unreachable=0 failed=0
veos1 : ok=1 changed=1 unreachable=0 failed=0
vsrx : ok=1 changed=1 unreachable=0 failed=0
你可以看到每个任务成功完成;如果你是在终端上运行,你将看到用琥珀色显示的每个改变的任务。
让我们再次运行 playbook。通过再次运行,我们可以校验所有模块的 幂等性;当我们这样做的时候,我们看到设备上 没有 产生变化,并且所有的东西都是绿色的:
PLAY [PLAY 1 - CISCO NXOS] ***************************************************
TASK: [ENSURE VLAN 100 exists on Cisco Nexus switches] ***********************
ok: [nx1]
PLAY [PLAY 2 - ARISTA EOS] ***************************************************
TASK: [ENSURE VLAN 100 exists on Arista switches] ****************************
ok: [veos1]
PLAY [PLAY 3 - CUMULUS] ******************************************************
GATHERING FACTS **************************************************************
ok: [cvx]
TASK: [ENSURE 100.10.10.1 is configured on swp1] *****************************
ok: [cvx]
TASK: [restart networking without disruption] ********************************
skipping: [cvx]
PLAY [PLAY 4 - JUNIPER SRX changes] ******************************************
TASK: [INSTALL JUNOS CONFIG] *************************************************
ok: [vsrx]
PLAY RECAP ***************************************************************
cvx : ok=2 changed=0 unreachable=0 failed=0
nx1 : ok=1 changed=0 unreachable=0 failed=0
veos1 : ok=1 changed=0 unreachable=0 failed=0
vsrx : ok=1 changed=0 unreachable=0 failed=0
注意:这里有 0 个改变,但是,每次运行任务,正如期望的那样,它们都返回 “ok”。说明在这个剧本中的每个模块都是幂等的。
总结
Ansible 是一个超级简单的、无代理和可扩展的自动化平台。网络社区持续不断地围绕 Ansible 去重整它作为一个能够执行一些自动化网络任务的平台,比如,做配置管理、数据收集和报告,等等。你可以使用 Ansible 去推送完整的配置文件,配置具体的使用幂等模块的网络资源,比如,接口、VLAN,或者,简单地自动收集信息,比如,领居、序列号、启动时间、和接口状态,以及按你的需要定制一个报告。
因为它的架构,Ansible 被证明是一个在这里可用的、非常好的工具,它可以帮助你实现从传统的基于 CLI/SNMP 的网络设备到基于 API 驱动 的现代化网络设备的自动化。
在网络社区中,易于使用和无代理架构的 Ansible 的占比持续增加,它将使没有 APIs 的设备(CLI/SNMP)的自动化成为可能。包括独立的交换机、路由器、和 4-7 层的服务应用程序;甚至是提供了 RESTful API 的那些软件定义网络控制器。
当使用 Ansible 实现网络自动化时,不会落下任何设备。
作者简介:
Jason Edelman,CCIE 15394 & VCDX-NV 167,出生并成长于新泽西州的一位网络工程师。他是一位典型的 “CLI 爱好者” 和 “路由器小子”。在几年前,他决定更多地关注于软件、开发实践、以及怎么与网络工程融合。Jason 目前经营着一个小的咨询公司,公司名为:Network to Code(http://networktocode.com/ ),帮助供应商和终端用户利用新的工具和技术来减少他们的低效率操作…
via: https://www.oreilly.com/learning/network-automation-with-ansible
作者:Jason Edelman 译者:qhwdw 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出