致如火如荼的云原生时代 —— Kubecon 2019 见闻录

6 月 24 ~ 26 日,Linux 基金会暨 CNCF 热推的 KubeCon + CloudNativeCon + OSS 2019 峰会于上海世博中心盛大揭幕。这是 Kubecon 大会在中国第二次举办,而距上一次在上海同一地点举办的 Kubecon 2018才仅过去半年,虽然调整会期有种种因素的考虑,但这么密集的再次举办也折射出云原生领域的发展速度——在本次大会上我们发现,各大云厂商和开源组织依然有很多值得分享的最新动态。

KubeCon + CloudNativeCon + OSS 2019 峰会于上海世博中心盛大揭幕
秉持 LC/CNCF 旗下会议一向的风格,这次大会在专业、丰富的各式讲演、专题分享之外,依旧是满场流动的人群、四处摆放的餐点,你甚至可以一整天泡在场馆,早中晚都吃在这里。嗯,要是有几个懒人沙发就更好了 :D
这次大会,我们 Linux 中国、异步社区、开源社和掘金等几个国内知名的开源社区也得到了大会主办方的鼎力支持,赠送给各家社区一块非常不错的独立展位。为此,我们也精心准备了各种礼物和展板,在社区的志愿者 ONLY、cycoe、XYenChi、TK 等人的帮助下,得以在这样的国际性大会上和大家进行了面对面交流。

Linux 中国的展台 ,感谢我们的社区志愿者!
由于我在这次展会期间有好多新老朋友要见面,也预约了几个专访,因此很多心仪的演讲都失之交臂,这应该是我本次参会最大的遗憾了吧。
大家都在说“云原生”,而它到底是什么?CNCF 执行董事 Dan Kohn 给出了官方的定义:

云原生定义 v1.0
这次大会上,CNCF 宣布蚂蚁金服成为其新的黄金会员。CNCF 执行董事 Dan Kohn 表示,“CNCF 非常欢迎蚂蚁金服的加入,蚂蚁金服大规模的使用 Kubernetes 集群来构建其金融服务,是一个在中国拥抱云原生热潮中很好的案例。”
而中国更是与 CNCF 结下了不解之缘,超过 10% 的 CNCF 会员来自中国,包括 16% 的铂金会员和 35% 的黄金会员。

中国与 CNCF 的不解之缘
中国已经是 Kubernetes 的第二大贡献者,在 Kubernetes 上做出了很大的贡献,在其它的 CNCF 的项目也是如此。
也是在这次大会上,蚂蚁金服的王旭做了有关安全容器的演讲。他是安全容器项目 runV的创始人,在 runV 和 Clear 容器项目合并为 Kata 容器之后,一直在继续领导该项目的发展。他同时宣布了 Kata 容器1.7 的发布。作为容器安全领域的两大解决方案之一,Kata 容器得到了社区的积极支持,并进一步和蚂蚁金服开源的 SOFAStack 相结合,目前已经完成了和 SOFAMesh 的集成。
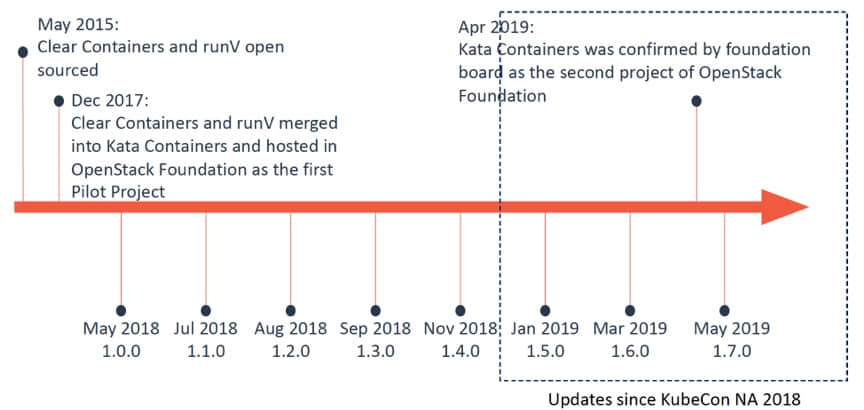
KubeCon NA 2018 之后 Kata 容器发布了 3 个版本
作为国内领先的云服务商,阿里云自然也出现在了这次大会上,并发布了若干重要产品/服务,其中包括国内首个“开放云原生应用中心 - Cloud Native App Hub”。开放云原生应用中心,是云原生“高速公路”上的托管和分发应用的集散地,同时也是国内开发者使用云原生应用的重要基础仓库。在 Kubernetes 生态中,“应用”是一组 YAML 格式的描述文件,而云原生应用中心,则为搜索、使用和分享这些应用描述文件提供了一个完全开源与开放的交互平台。

开放云原生应用中心 - Cloud Native App Hub
在当前的 Kubernetes 应用生态当中,Helm 是目前最被广泛使用的应用定义标准之一。所以在本次云原生应用中心的发布当中,对 Helm 格式应用的托管、搜索和分发能力成为了中心首次上线的能力。为了能够让中国的开发者更好的使用 Helm Hub 的能力,阿里云开发者中心与 Helm 社区达成了一系列技术合作,在开放云原生应用中心提供了国内首个 Helm Hub 北美官方站的同步镜像仓库与 Hub 站点。这使得中国的开发者终于可以随心所欲的搜索云原生应用,然后直接使用 helm install 命令将这些应用安装在全世界任何一个 Kubernetes 集群当中。
除了开放云原生应用中心之外,阿里云容器平台团队还正式宣布开源了重量级项目 OpenKruise。该项目源自于阿里巴巴经济体应用过去多年的大规模应用部署、发布与管理的最佳实践,源于容器平台团队对集团应用规模化运维,规模化建站的能力,源于阿里云Kubernetes服务数千客户的需求沉淀。Kruise 核心在于自动化,从不同维度解决了Kubernetes之上应用的自动化,包括,部署、升级、弹性扩缩容、Qos调节、健康检查、迁移修复等等。此次Kruise开源的内容主要在应用部署,升级方面,即一套增强版控制器组件用于应用的部署和级和运维。
目前,伴随着 5G 的到来,边缘计算也是一个热点,在本次大会上阿里云发布了托管版边缘集群 ACK@edge,致力于实现云-边-端一体化协同,通过非侵入增强方式,完美拓展云原生的边界。边缘云计算是基于云计算技术的核心和边缘计算的能力,构筑在边缘基础设施之上的云计算平台。形成边缘位置的计算、网络、存储、安全等能力全面的弹性云平台,并与中心云和物联网终端形成“云边端三体协同” 的端到端的技术架构,通过将网络转发、存储、 计算,智能化数据分析等工作放在边缘处理,降低响应时延、减轻云端压力、降低带宽成本,并提供全网调度、算力分发等云服务。
而此前华为云的开源智能边缘项目 KubeEdge 已经加入 CNCF 社区,成为 CNCF 在智能边缘领域的首个正式项目,这意味着云原生社区对智能边缘领域的关注与重视。
从本次大会的参会感受来看,特别明显的一点就是针对云原生生态的各种项目层出不穷。除了上面提及的 OpenKruise、Kata 容器之外,还有青云 QingCloud 也推出了自己的产品 KubeSphere(QKE),可以在 QingCloud 公有云上交付 KubeSphere 容器平台全能力,提供托管的原生 Kubernetes 集群、极简的人机交互实现 CI/CD、微服务、以及集群运维管理,帮助用户更敏捷地构建云原生应用,并一站式实现应用全生命周期的统一管理,从而全面释放企业的核心业务生产力。QKE 相较于原生的 Kubernetes 集群,提供了更多完善易用的开发工具集,能够实现极简开发、强劲支持和高效交付,可以帮助用户解除核心业务开发以外的平台工作负担。除了拥有强大的平台能力,QKE 还可以无缝支持混合云与多云环境。KubeSphere 交付的公有云与私有云具有完全一致的体验,无缝打通两种环境中的应用,用户可将应用在跨公、私环境的 Kubernetes 集群中进行混合部署,赋予业务更大的灵活性。
除了云原生技术方面的突破和进展之外,本次 Kubecon 大会也同时召开了开源峰会,对开源治理提出了诸多见解和分享。
来自开源社的 Ted Liu 做了题为《开源治理实践和企业案例研究》的演讲,为企业在采用、使用开源软件以及为 OSS 社区做出贡献方面提供了明确的指导和步骤。Ted Liu 还将分享一些案例研究,探讨龙头企业如何建立他们的开源项目办公室,以简化开源治理和政策,同时还将介绍开源许可和合规性。

开源社 Ted Liu 在发表演讲
而来自阿里巴巴的 Frank Zhao 则开始探索新的开源社区管理方式,将重点放在协作自动化和开发人员行为分析,这有助于社区维护人员的管理工作。在其演讲《阿里巴巴数字推动的开源社区探索》中展示了他们是如何构建阿里巴巴开源社区机制,以及为实施该机制而构建的工具背后的思考。
本次大会的内容之丰富、话题之深入,让人深切感受到了云原生领域的如火如荼的发展,而这篇文章已经太长了,本次大会上更多值得关注的数字和消息还有:
- Linux 已经成长为世界上最重要的软件平台:100% 的超级计算机市场份额;82% 的手机市场份额;68% 的企业服务器市场份额;90% 的大型机客户;90% 的公有云工作负载;62% 的嵌入式市场份额。
- 世界上有 51% 的关键项目是在“云”上运行的,而在中国达到了 72%;世界上有 45% 的项目,仍然是在传统的环境当中,但是在中国,这个数字仅仅只是 28% 。
- Linux 基金会最新成立了一个子基金会 LFAI,领域主要是人工智能、机器学习和深度学习。中国有很多的企业都成为其成员,包括:百度、华为、嘀嘀等等。
- 京东谈论了他们是《如何运行全球最大的 Vitess》以及《在 Kubernetes 中经济高效地调度大量容器》,并透露消息其区块链 BI 数据服务将在今年 7-8 月上线公测。
让我们期待今年 11 月在圣地亚哥举办的 KubeCon + CloudNativeCon 2019 北美峰会的更多消息,据称将会迎来 1.2 万名与会者,这会成为历史上最大的一个“开源峰会”!












