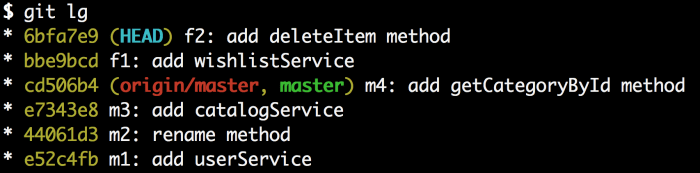
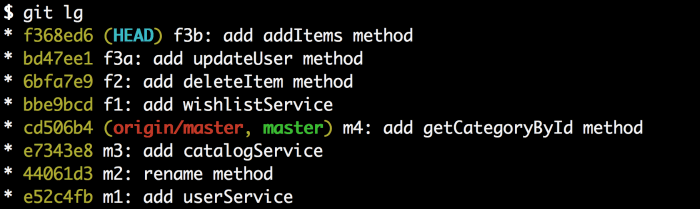
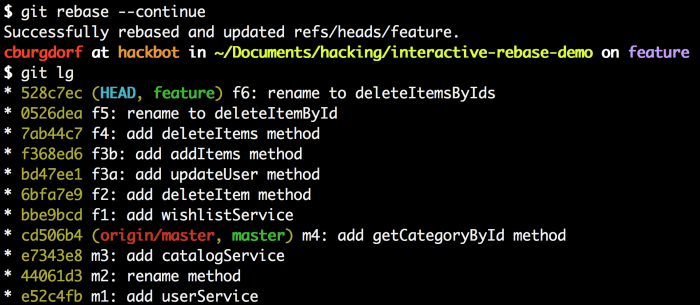
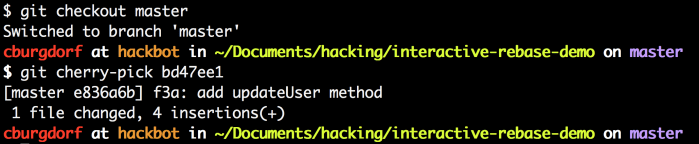
AUTH:PHILO EMAIL:lijianying12 at gmail.com
基于POST GET 的http通讯虽然非常成熟,但是很容易被人监听。 并且如果使用跨域jsonp的通讯很容易在历史记录中发现通讯网址以及参数。为了克服这些问题, 并且降低服务器成本,我们没有使用SSL而使用 RSA加密。文章中的php加密解密 JS的加密解密 互相加密解密 都能验证通过。
其中PHP依赖常见的OPENSSL LIB 。 JS依赖 jsencrypt。
我们使用jsonp get RSA加密通讯好处如下:
- 前后分离适合cdn加速。
- 安全跨域更适合松散结构的网站。
- 不用去买ssl证书了。

首先要生成密匙对
openssl genrsa 1024 > private.key
openssl rsa -in private.key -pubout > public.key
JS的RSA加密流程
下载最新版本请移步到github:jsencrypt 代码在目录BIN下面是否用压缩的根据情况决定。
生成KEY
var keySize = 1024; //加密强度
var crypt = new JSEncrypt({default_key_size: keySize}); //RSA 操作对象
//方法1 (async)
crypt.getKey(function () {
crypt.getPrivateKey();
crypt.getPublicKey();
});
//方法2:
crypt.getKey();
crypt.getPrivateKey();
crypt.getPublicKey();
客户端加密场景:
var crypt1 = new JSEncrypt(); //新建rsa对象
var publickey = '\
-----BEGIN PUBLIC KEY-----\
MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQC3N8LJFqlsa6loCgFpgZVMr/Sx\
DMQY7pr0euNQfh2g+UVPbB0MGhoc7nWL0FQhCgDedbjQw/nGFStFx7W1+0o1oRTY\
u5ebNVivZSobraUv7LJvwT8O66Zs8cxbKLqQ/nE/WwJvXomSIckH6R8iOUO8/QT9\
kv6/L0Uma3qA07pmDQIDAQAB\
-----END PUBLIC KEY-----\
';
crypt1.setPublicKey(publickey );//添加来自服务端的publickey
crypt1.encrypt('abc'); //返回值为加密后的结果
客户端解密场景:
var privatekey = '-----BEGIN RSA PRIVATE KEY-----\
MIICXQIBAAKBgQC3N8LJFqlsa6loCgFpgZVMr/SxDMQY7pr0euNQfh2g+UVPbB0M\
Ghoc7nWL0FQhCgDedbjQw/nGFStFx7W1+0o1oRTYu5ebNVivZSobraUv7LJvwT8O\
66Zs8cxbKLqQ/nE/WwJvXomSIckH6R8iOUO8/QT9kv6/L0Uma3qA07pmDQIDAQAB\
AoGBAKba3UWModbfZXQeSJLxNCqWw9zJp3ydL/keQQ35DLqgyIJAD2QKEWXvtJUT\
sMo19fyicSGOmFXQyYvPCKkmpLkOMAj1XaNpSMtSrcMx+gC01PO6Ey9rsUxW1g3u\
fpqbEk9E3a5AtCS0I61nbUpRL6rqMtR5o2wcNR3TLtJt7pjxAkEA7hlFJKU1zWGp\
OvvkJDnHc2NOCEJoGjqCR9wwv96+/xAykl2laI6WvEbbhjoO0+8+d17oigjhneS5\
2UKFcfqw7wJBAMT+MCQ5TYLQlvjrBaDMqOdLsqtaDE6CpkrgwV820QMvHOo3R4Xd\
uSbrA2tOr9t2/x+FzF971lRGdPFIch9UYMMCQQCZtO6SDaWCBP3++gX57OL5dq41\
XsldxU+9nERMWTvr5UUAgDv8F7Dvsr6dFHXmE5i77yUnlzwvdi0UOIF1Z2U5AkBV\
wyRKYPgx34Ya0JcerntKV1Zt60I4XADx0G/feAn/DN/VyENHMISPQPm4GgXN0jy4\
CJQ1bcCd6B65fQTSRvXpAkA2Vv5yXzeKDls/AyxHEoros/VYftVc1HOFC++q13Rw\
NH2rnlRT8FMTFEqL9MYRqvvYAFf5VmH0M1Nx5t4LRN+l\
-----END RSA PRIVATE KEY-----\
';
var crypt2 = new JSEncrypt();//新建加密对象
crypt2.setPrivateKey(privatekey);//给加密对象设置privatekey
crypt2.getPublicKey();//Tip 我们是不需要存储publickey的直接用private能得到publickey
crypt2.decrypt("MeUqWB5LwTh8crzPqbZtEtKuZxYvPWH9CTCChK1qoBzIgIXGPCdzNMbiH0cCYHl5qWSERIDOgDIgv4dXsIMjEJ5q0cp/qNQYHM5va0iw0UvKvQB1E8aWtY2nFEPy4F+ArQ0Mj/ijr/CntEP1jHKC3WU9nu2kYrBIBnbj14Bs+kI=");//调用解密方法
但是虽然写到了这里,加密方面还是不够用,因为1024长度的RSA加密最多只能加密长度为117的字符串。而URL长度最多为4k因此这里我们要让加密长度达到2691以达到能用的程度。
那么这种加密长度大概能容纳多少数据呢? 我们借助json-generator来帮忙生成JSON
sdata =[
{
"_id": "542f9ac2359c7d881bc0298e",
"index": 0,
"guid": "db1dacc1-b870-4e3c-bc1a-80dfd9506610",
"isActive": false,
"balance": "$1,570.15",
"picture": "http://placehold.it/32x32",
"age": 36,
"eyeColor": "blue",
"name": "Effie Barr",
"gender": "female",
"company": "ZORK",
"email": "[email protected]",
"phone": "+1 (802) 574-3379",
"address": "951 Cortelyou Road, Wikieup, Colorado, 4694",
"about": "Sunt reprehenderit do laboris velit qui elit duis velit qui. Nostrud sit eiusmod cillum exercitation veniam ad sint irure cupidatat sunt consectetur magna. Amet nisi velit laboris amet officia et velit nisi nostrud ipsum. Cupidatat et fugiat esse minim occaecat cillum enim exercitation laboris velit nisi est enim aute. Enim do pariatur
",
"registered": "2014-05-08T15:26:35 -08:00",
"latitude": 48.576424,
"longitude": 146.634137,
"tags": [
"esse",
"proident",
"quis",
"consectetur",
"magna",
"tempor",
"anim"
],
"friends": [
{
"id": 0,
"name": "Trisha Cannon"
},
{
"id": 1,
"name": "Todd Bullock"
},
{
"id": 2,
"name": "Eileen Drake"
},
{
"id": 3,
"name": "Ferrell Kelly"
},
{
"id": 4,
"name": "Fischer Blankenship"
},
{
"id": 5,
"name": "Morales Mann"
},
{
"id": 6,
"name": "Brandie Pittman"
},
{
"id": 7,
"name": "Virgie Kerr"
}
],
"greeting": "Hello, Effie Barr! You have 1 unread messages.",
"favoriteFruit": "apple"
},
{
"_id": "542f9ac21c260d03e763a4f2",
"index": 1,
"guid": "9e3a3d8a-26f8-46b7-aca0-336a194808b1",
"isActive": true,
"balance": "$3,617.89",
"picture": "http://placehold.it/32x32",
"age": 31,
"eyeColor": "brown",
"name": "Butler Best",
"gender": "male",
"company": "SPORTAN",
"email": "[email protected]",
"phone": "+1 (905) 428-3046",
"address": "798 Joval Court, Wanship, Delaware, 8974",
"about": "Nostrud occaecat id sunt pariatur ad nisi do veniam sit officia non consequat amet fugiat. Est eiusmod labore ut cillum qui eu elit ut eiusmod exercitation. Ut anim nostrud eiusmod voluptate tempor proident id do pariatur. In Lorem ullamco ea irure adipisicing. Quis est dolor ex commodo aliqua nisi elit sit elit anim fugiat sunt amet. Enim consequat ipsum occaecat ipsum tempor deserunt dolor veniam nostrud. Anim cillum ullamco cupidatat aute velit fugiat sit enim in amet anim mollit dolor eiusmod.
",
"registered": "2014-08-02T06:15:44 -08:00",
"latitude": -20.529765,
"longitude": 2.396578,
"tags": [
"consequat",
"enim",
"magna",
"sunt",
"Lorem",
"quis",
"commodo"
],
"friends": [
{
"id": 0,
"name": "Kenya Rice"
},
{
"id": 1,
"name": "Hale Knowles"
},
{
"id": 2,
"name": "Michael Stephens"
},
{
"id": 3,
"name": "Holder Bailey"
},
{
"id": 4,
"name": "Garner Luna"
},
{
"id": 5,
"name": "Alyce Sawyer"
},
{
"id": 6,
"name": "Rivas Owens"
},
{
"id": 7,
"name": "Jan Petersen"
}
],
"greeting": "Hello, Butler Best! You have 8 unread messages.",
"favoriteFruit": "banana"
}
]
表单json能达到这么长已经是很极端的情况了。因此这种方法绝对是够用的。
长表单内容加解密方法:
function encrypt_data(publickey,data)
{
if(data.length> 2691){return;} // length limit
var crypt = new JSEncrypt();
crypt.setPublicKey(publickey);
crypt_res = "";
for(var index=0; index < (data.length - data.length%117)/117+1 ; index++)
{
var subdata = data.substr(index * 117,117);
crypt_res += crypt.encrypt(subdata);
}
return crypt_res;
}
function decrypt_data(privatekey,data)
{
var crypt = new JSEncrypt();
crypt.setPrivateKey(privatekey);
datas=data.split('=');
var decrypt_res="";
datas.forEach(function(item)
{
if(item!=""){de_res += crypt.decrypt(item);}
});
return decrypt_res;
}
##########NextPage[title=]##########
PHP的RSA加密
php加密解密类
首先要检查phpinfo里面有没有openssl支持
class mycrypt {
public $pubkey;
public $privkey;
function __construct() {
$this->pubkey = file_get_contents('./public.key');
$this->privkey = file_get_contents('./private.key');
}
public function encrypt($data) {
if (openssl_public_encrypt($data, $encrypted, $this->pubkey))
$data = base64_encode($encrypted);
else
throw new Exception('Unable to encrypt data. Perhaps it is bigger than the key size?');
return $data;
}
public function decrypt($data) {
if (openssl_private_decrypt(base64_decode($data), $decrypted, $this->privkey))
$data = $decrypted;
else
$data = '';
return $data;
}
}
密匙文件位置问题,是放到访问接口的附近就可以了如果是CI的话就放到index.php旁边就行了。 但是要注意一点,一定要做访问设置,不然key会暴出来的,那时候信息一旦截获就惨了。
类的使用
$rsa = new mycrypt();
echo $rsa -> encrypt('abc');
echo $rsa -> decrypt('W+ducpssNJlyp2XYE08wwokHfT0bm87yBz9vviZbfjAGsy/U9Ns9FIed684lWjYyyofi/1YWrU0Mp8vLOYi8l6CfklBY=');
长数据加密解密
function encrypt_data($publickey,$data)
{
$rsa = new mycrypt();
if($publickey != ""){
$rsa -> pubkey = $publickey;
}
$crypt_res = "";
for($i=0;$i<((strlen($data) - strlen($data)%117)/117+1); $i++)
{
$crypt_res = $crypt_res.($rsa -> encrypt(mb_strcut($data, $i*117, 117, 'utf-8')));
}
return $crypt_res;
}
function decrypt_data($privatekey,$data)
{
$rsa = new mycrypt();
if($privatekey != ""){ // if null use default
$rsa ->privkey = $privatekey;
}
$decrypt_res = "";
$datas = explode('=',$data);
foreach ($datas as $value)
{
$decrypt_res = $decrypt_res.$rsa -> decrypt($value);
}
return $decrypt_res;
}
JSONP 跨域通讯
我们经过千辛万苦经过加密终于能做到通讯安全了。 当然我们的下一步是通过JSONP 的get通讯来实现跨域通讯啦。 经过测试:我们的JS中最长的Case url长度是3956 在加上跨域url callbac参数,经过测试正好差20到4095 (一般的URI长度限制为4K)
$.ajax({
type:"get",
async:false, // 设置同步通讯或者异步通讯
url:"http://22500e31b5a12457.sinaapp.com/ubtamat/getPubKey?c=hknHQKIy3dyeeajyAwZ+raUkV1ezFbgU8zk+54cNQtrcEGozUjXpYhbC6fxz2hCOgp9feIsM1xKJFm5pkAGQ2UcUOc5EJNCAz6L0mXkZbTBmh3PufWxOE7TaicqRCRtZGGNB2qpm2WruXjYg1lPcrPz/rhFZx4DSJvEHkCm7ZU0=......(加密后的结果太长,省略)",
dataType:"jsonp",
jsonp: "",
});
header("Content-type: application/javascript; charset=utf-8");
$response = "console.log('test response!')";
$callback = $this->input->GET('callback');
echo $callback.$response;
PHP代码是CI框架controler中的部分代码 并且经过了必要的裁剪。 更加细节的参数都放到GET里面就可以了。 处理之后按照上面的形式处理返回值就ok 如果你配置成功了,你将会在网页的控制台上看到自己动态的, 或者像我一样静态的控制台输出。 如果要是想获取数据到网页的话还是要借助回调函数来实现
JSONP跨域获取通讯结果
请看下面代码:
客户端代码
var global = null;
function jpc(result)
{
global = result.msg;
}
$.ajax({
type:"get",
async:false, // 设置同步通讯或者异步通讯
url:"http://22500e31b5a12457.sinaapp.com/ubtamat/getPubKey",
dataType:"jsonp",
jsonp: "jpc",
});
服务器端代码
header("Content-type: application/javascript; charset=utf-8");
$response = "jpc({'msg':123456})";
$callback = $this->input->GET('callback');
echo $callback.$response;
此次通讯的结果会在jcp当中调用执行,并且返回的内容会记录到 global 变量当中。
实战
从上文中,我们已经找到了整个加密过程方法了,但是距离实战还是有一定距离的。 首先我们实战的话需要克服接口比较少,功能比较多,单个接口维护用时比较长的问题。
为了解决上面的问题我们做出如下设计。
客户端方面:
设计一个通讯类:只管跟服务器通讯。别的业务什么都不管。
//create connection object.
var ConnServ = new Object();
ConnServ.tmpResponse = "not initial";
//call back function register slot.
ConnServ.CallBackFunction=function(){console.log(
"call back function set error ! U must set a business call back function!"
)};
//input only encrypted data!!!
//send data to server
ConnServ.send=function(data)
{
data = data.replace(/\+/g,"$"); //replace all + as $
$.ajax({
type:"get",
async:false,
url:"http://22500e317.sinaapp.com/ubtamat?c="+data,
dataType:"jsonp",
jsonp: "jpc"
});
return "Send Finish";
}
//default call back funcation
function jpc(res)
{
ConnServ.tmpResponse = res.msg;
ConnServ.CallBackFunction();
}
//public key store.
ConnServ.getpublickey = function()
{
return "\-" +
"----BEGIN PUBLIC KEY----- " +
...................................................
"-----END PUBLIC KEY-----";
}
在上面代码中请注意,RSA加密过后的字符串当中有一个非法字符+要转换成其他合法字符发送到服务器才可以。 不然参数会错误。 等传输到服务器中自己转换回来在解密就好了。
服务器端方面:
首先我们接收到消息之后要对消息进行解密,之后根据报文内容选择服务器上的功能。然后把其他参数输入到业务类中执行即可。 因此我们使用了命令模式来实现单一接口的丰富业务功能。 其他的我们需要对CI框架的配置进行调整: 首先global config里面需要调整 $config['global\_xss\_filtering'] = FALSE; 因为如果传输过来的报文解密不了就直接抛弃不进行处理(防止CC攻击第一层)这样就从url上防止了攻击的可能性。 当然我们还是没有完全避免注入风险这时我们就需要在业务类里面调用安全模块:
$this->security->xss_clean()
来实现第二层的XSS攻击。这是服务器端设计主要需要说的位置。
服务器获取数据处理全过程
- 从get接口获得参数c的加密数据
- 对数据进行RSA解密。
判断数据包时间戳。如果超时直接抛弃(防止从浏览器记录中直接发送request到服务器,下面是安全方面的说明)
- 首先如果不修改数据只修改时间戳不可能从截获的数据报文中实现,因为需要重新加密,如果想得到内容需要服务器上的privatekey解密保证安全
- 如果数据包截获直接发送数据包在超时范围内直接获取数据包内容,也不能实现攻击,因为在客户端有临时RSA密匙对生成并且在发送的时候会同时发送publickey 给服务器做session的存储内容并且伪装客户的客户端没有privatekey所以获取任何关于登陆之后的消息根本无法解析。
- 对解密后的数据进行xss检查
- 解析报文中需要调用什么功能直接调用反射得到业务类的实例
- 调度业务类,并且把得到的参数赋值给业务执行函数的参数。
服务器处理数据过程只跟业务有关
服务器返回数据全过程
- 业务处理完成之后针对每一个用户的登陆情况对返回值进行加密。
- response
以上业务涉及的部分代码(给出的代码未涉及以上说的安全部分。)
//CI 控制器里面的方法
public function index()
{
header("Content-Type: text/html;charset=UTF-8");
$callback = $this -> input->GET('callback');
$input_data = str_replace("$","+",$this->input->GET('c'));
$input_data =$this -> rsa->decrypt_data($input_data);
if($input_data == ""){return;}//如果数据不对解析就会失败,直接抛弃数据包,避免cracker构造数据包问题
//这里插入时间戳检查代码
//这插入xss检查
$output_data = command($input_data);
$response = "jpc({'msg':".$output_data."})";
$callback = $this->input->GET('callback');
echo $callback.$response;
}
//命令模式中的业务调度方法
function command($input)
{
try
{
$obj_input = json_decode($input);
$action = $obj_input -> {"action"};
$business_action = new ReflectionClass($action);
$instance = $business_action->newInstanceArgs();
$output = $instance->Action($obj_input);
//对output变量进行rsa加密
return "'".$output."'"; // here only accept string
}
catch(Exception $e)
{
return "'".$e->getMessage()."'";
}
}
以下是配合业务进行的工具函数:
//命令接口定义
interface ICommand {
function Action($arg_obj);
}
//把此函数放到system/core/common.php
//实现了输入一个文件夹就自动加载所有文件夹中的所有的类。
if ( ! function_exists('require_once_dir'))
{
function require_once_dir($path)
{
$dir_list = scandir($path);
foreach($dir_list as $file)
{
if ( $file != ".." && $file != "." )
{
require_once($path."/".$file);
}
}
}
}
//使用:
//在application/config/autoload.php中添加类似如下代码:
require_once_dir(APPPATH."/controllers/lib");
require_once_dir(APPPATH."/controllers/actions");
以下是实现业务的例子:
class register implements ICommand{
public function Action($arg_obj)
{
return "we are do nothing: ".json_encode($arg_obj);
}
}
通过以上基本方法,我们可以实现,只要业务继承我们声明的接口就可以开始写业务了。 别的什么都不用管,专注于业务即可,其他的安全、IO等问题都已经一并解决。 并且每一个业务都进行了rsa加密xss攻击过滤伪造数据包攻击。 以及在response加密只能是固定客户端才能看到报文内容的全过程。 但是一定要注意一点,注册这个业务后面要嵌套登陆进行,不然看不到返回值。
数据包必须包含的要素:
- acton (业务名)
- req\_time (请求时间)
- public\_key (如果是注册跟登陆时候需要提交临时公匙)
总结
因为时间仓促所以只能写到这里了。 如果您发现了我文章中的bug欢迎发email批评指正。非常感谢! 同时本方案也会成为我们开源社区linux52.com后台系统中的接口设计方案。 当然我们社区所有维护的文档都会进行反复验证,如果出问题我们会及时更新。 以维护文档的正确性。 点击=这=里=查看文档最新版本。
关键词
php js rsa get jsonp 跨域 安全