怎样通过 Twitter 的开源库来随处使用 Emoji 表情符号
怎样通过 Twitter 的开源库来随处使用 Emoji 表情符号
通过 GitHub 将它们嵌入到网页和其他项目中。

Emoji, 来自日本的小巧符号,通过图像表达感情,已经征服了移动互联网的信息世界。
现在,你可以在虚拟世界中随处使用它们了。 Twitter 最近开源了他们的 emoji 符号库,使得你可以在你自己的网站,应用,和项目中使用它们。
但这需要一点体力活。 Unicode 已经识别甚至标准化了 emoji 字母表, 然而 emoji 仍然不能完全与所有的网络浏览器相兼容,这意味着大多数情况下,它们将呈现为 “豆腐块”或“空白盒子”。当 Twitter 想使得 emoji 到处可用时,这家社交网络联合了一家名为Icon Factory的公司来渲染浏览器以模仿文本信息符号的效果。Twiter 认为人们对他们的 emoji 库有很大的需求。
现在, 你可以从 GitHub 上克隆 Twitter 的整个库,从而在你的开发项目中使用它们。 下面将为你介绍如何达到上面的目的以及如何使得 emoji 更容易被使用。
为 Emoji 得到 Unicode 支持
Unicode 是国际编码标准,它为任意的符号、字母或人们想在网络上使用的数字配置了一串编码。换句话说,它是你如何在计算机上阅读文本与计算机如何读取文本之间的缺失环节。例如,对于你正看到的位于这些句子中的空格(LCTT 译注:英文分词中间的空格),计算机读取为 “ ”。
Unicode 甚至拥有其自己的原始 emoji,它们可以在没有你的任何努力的情况下在浏览器中被阅读。例如,当你看到了 一个 ❤ 符号,你的计算机正在解码字符串 “2665” 。
要在大多数情况下使用 Twitter 的 emoji 库,你只需在你的 HTML 网页中的
块中添加如下脚本:<script src="//twemoji.maxcdn.com/twemoji.min.js"></script>
这样就使得你的项目可以访问包含有已经在 Twitter 中可使用的数以百计的 Emoji 符号的 JavaScript 库。然而,创建一个仅仅包含这个脚本的文档并不能使得在你的网站中呈现出 emoji 符号,实际上,你仍需要嵌入这些 emoji 符号!
在
块中,粘贴一些可以在 Twitter 的preview.html 文件源代码 中找到的 emoji 字符串。我使用了 和 🏁,当然我并不知道在浏览器窗口中它们的样子。是的,你必须粘贴并猜测它们。你已经看出了问题,我们将在第二小节中予以解决。
和 🏁,当然我并不知道在浏览器窗口中它们的样子。是的,你必须粘贴并猜测它们。你已经看出了问题,我们将在第二小节中予以解决。无论如何,通过一些尝试,你可以将一个如下图的原始 HTML 文件---
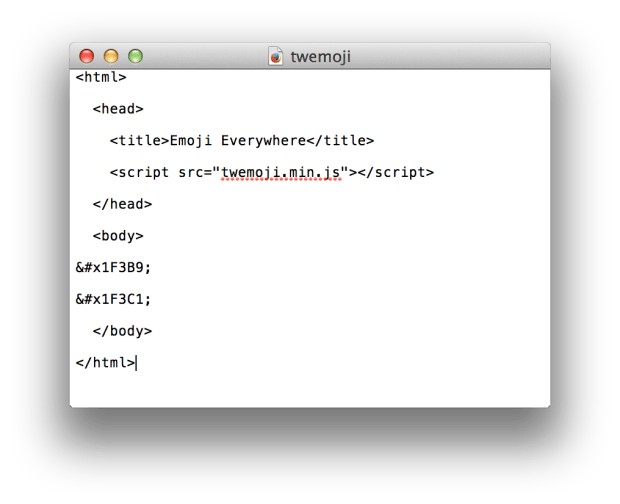
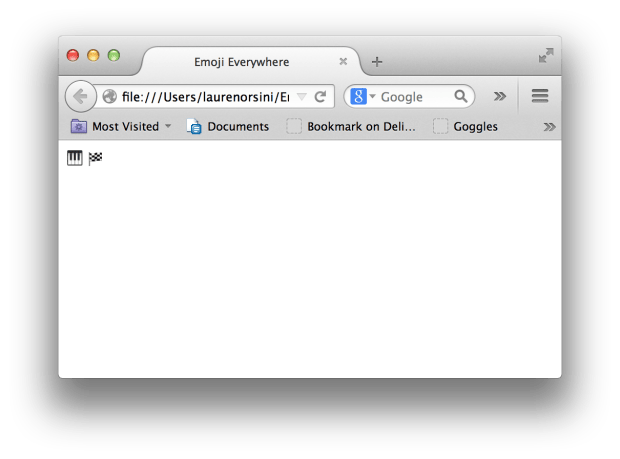
---显示为如下图的网页:
将 Emoji 转换为可阅读的语言
对于一个网站或应用,Twitter 的解决方案是非常适用的。但如果你想通过 HTML 轻易地插入你喜爱的 emoji 符号,你需要一个更易实现的解决方案,而不是记住所有代表 emoji 的 Unicode 字符串。
那正是程序员 Elle Kasai 的 Twemoji Awesome 样式大展身手的地方。
通过向任意网页中添加 Elle 的开源样式表,你可以适用 英语单词来理解你正插入的 emoji 符号的意义。所以如若你想展示一个 心形 emoji 符号,你可以简单地输入:
<i class="twa twa-heart"></i>
为了实现上面的目的,让我们下载 Elle 的项目,通过点击在 GitHub 上 “Download ZIP” 按钮。
接着,我们在桌面上新建一个文件夹,然后进入该文件夹,并将 emoji.html---我先前向你展示的 HTML 源文件--- 和 Elle 的 twemoji-awesome.css 一同放进去。
我们还需要 HTML 文件识别这个 CSS 文件,所以在 html 网页中的
块中,为 CSS 文件添加一个链接:<link rel="stylesheet" href="twemoji-awesome.css">
一旦你将上面的代码添加了进去,你便可以删除先前添加的 Twitter 的脚本链接。
现在,找到 body 块部分的代码,然后添加一些 emoji 符号。我使用了 , , 和 。
最终,你将得到如下的代码:
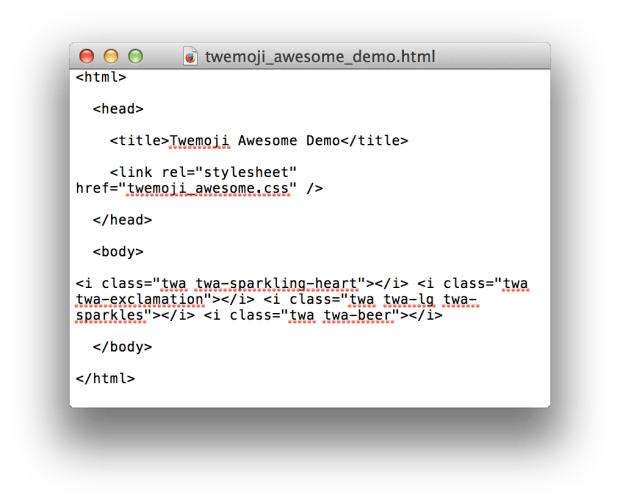
保存并在浏览器中查看上面的文件:
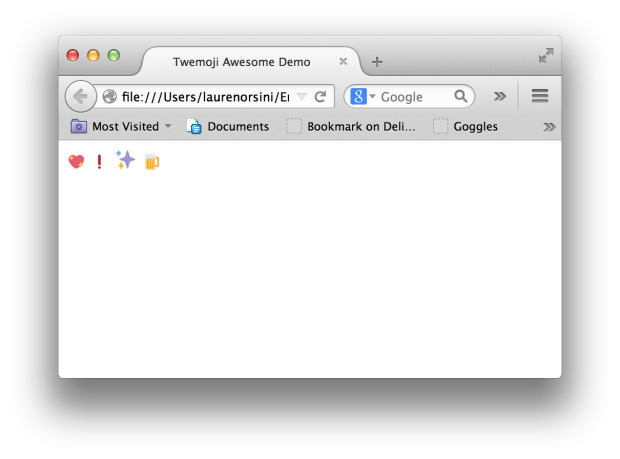
Duang!这样你不仅得到了一个可以在浏览器中支持 emoji 符号的基本网页,而且还知道了如何简单地实现它。你可以随意的在我的 GitHub 中查看这个教程,并且可以克隆这些实际的文件而不只是看看这些截图。
题图来自于得到 Emoji; Lauren Orsini 截图。
via: http://readwrite.com/2014/11/12/how-to-use-emoji-in-the-browser-window
作者:Lauren Orsini 译者:FSSlc 校对:wxy