这是我建立一个简单的 Facebook Messenger 机器人的记录。功能很简单,它是一个回显机器人,只是打印回用户写了什么。
回显服务器类似于服务器的“Hello World”例子。
这个项目的目的不是建立最好的 Messenger 机器人,而是让你了解如何建立一个小型机器人和每个事物是如何整合起来的。

技术栈
使用到的技术栈:
- Heroku 做后端主机。免费级足够这个等级的教程。回显机器人不需要任何种类的数据持久,所以不需要数据库。
- Python 是我们选择的语言。版本选择 2.7,虽然它移植到 Pyhton 3 很容易,只需要很少的改动。
- Flask 作为网站开发框架。它是非常轻量的框架,用在小型工程或微服务是非常完美的。
- 最后 Git 版本控制系统用来维护代码和部署到 Heroku。
- 值得一提:Virtualenv。这个 python 工具是用来创建清洁的 python 库“环境”的,这样你可以只安装必要的需求和最小化应用的大小。
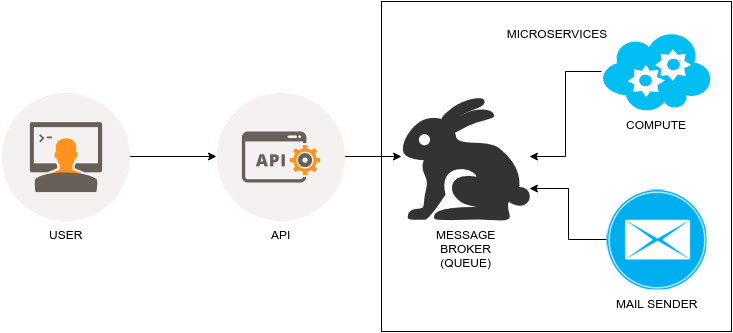
机器人架构
Messenger 机器人是由一个响应两种请求的服务器组成的:
- GET 请求被用来认证。他们与你注册的 FaceBook 认证码一同被 Messenger 发出。
- POST 请求被用来实际的通信。典型的工作流是,机器人将通过用户发送带有消息数据的 POST 请求而建立通信,然后我们将处理这些数据,并发回我们的 POST 请求。如果这个请求完全成功(返回一个 200 OK 状态码),我们也将响应一个 200 OK 状态码给初始的 Messenger请求。
这个教程应用将托管到 Heroku,它提供了一个优雅而简单的部署应用的接口。如前所述,免费级可以满足这个教程。
在应用已经部署并且运行后,我们将创建一个 Facebook 应用然后连接它到我们的应用,以便 Messenger 知道发送请求到哪,这就是我们的机器人。
机器人服务器
基本的服务器代码可以在 Github 用户 hult(Magnus Hult) 的 Chatbot 项目上获取,做了一些只回显消息的代码修改和修正了一些我遇到的错误。最终版本的服务器代码如下:
from flask import Flask, request
import json
import requests
app = Flask(__name__)
### 这需要填写被授予的页面通行令牌(PAT)
### 它由将要创建的 Facebook 应用提供。
PAT = ''
@app.route('/', methods=['GET'])
def handle_verification():
print "Handling Verification."
if request.args.get('hub.verify_token', '') == 'my_voice_is_my_password_verify_me':
print "Verification successful!"
return request.args.get('hub.challenge', '')
else:
print "Verification failed!"
return 'Error, wrong validation token'
@app.route('/', methods=['POST'])
def handle_messages():
print "Handling Messages"
payload = request.get_data()
print payload
for sender, message in messaging_events(payload):
print "Incoming from %s: %s" % (sender, message)
send_message(PAT, sender, message)
return "ok"
def messaging_events(payload):
"""Generate tuples of (sender_id, message_text) from the
provided payload.
"""
data = json.loads(payload)
messaging_events = data["entry"][0]["messaging"]
for event in messaging_events:
if "message" in event and "text" in event["message"]:
yield event["sender"]["id"], event["message"]["text"].encode('unicode_escape')
else:
yield event["sender"]["id"], "I can't echo this"
def send_message(token, recipient, text):
"""Send the message text to recipient with id recipient.
"""
r = requests.post("https://graph.facebook.com/v2.6/me/messages",
params={"access_token": token},
data=json.dumps({
"recipient": {"id": recipient},
"message": {"text": text.decode('unicode_escape')}
}),
headers={'Content-type': 'application/json'})
if r.status_code != requests.codes.ok:
print r.text
if __name__ == '__main__':
app.run()
让我们分解代码。第一部分是引入所需的依赖:
from flask import Flask, request
import json
import requests
接下来我们定义两个函数(使用 Flask 特定的 app.route 装饰器),用来处理到我们的机器人的 GET 和 POST 请求。
@app.route('/', methods=['GET'])
def handle_verification():
print "Handling Verification."
if request.args.get('hub.verify_token', '') == 'my_voice_is_my_password_verify_me':
print "Verification successful!"
return request.args.get('hub.challenge', '')
else:
print "Verification failed!"
return 'Error, wrong validation token'
当我们创建 Facebook 应用时,verify\_token 对象将由我们声明的 Messenger 发送。我们必须自己来校验它。最后我们返回“hub.challenge”给 Messenger。
处理 POST 请求的函数更有意思一些:
@app.route('/', methods=['POST'])
def handle_messages():
print "Handling Messages"
payload = request.get_data()
print payload
for sender, message in messaging_events(payload):
print "Incoming from %s: %s" % (sender, message)
send_message(PAT, sender, message)
return "ok"
当被调用时,我们抓取消息载荷,使用函数 messaging\_events 来拆解它,并且提取发件人身份和实际发送的消息,生成一个可以循环处理的 python 迭代器。请注意 Messenger 发送的每个请求有可能多于一个消息。
def messaging_events(payload):
"""Generate tuples of (sender_id, message_text) from the
provided payload.
"""
data = json.loads(payload)
messaging_events = data["entry"][0]["messaging"]
for event in messaging_events:
if "message" in event and "text" in event["message"]:
yield event["sender"]["id"], event["message"]["text"].encode('unicode_escape')
else:
yield event["sender"]["id"], "I can't echo this"
对每个消息迭代时,我们会调用 send\_message 函数,然后我们使用 Facebook Graph messages API 对 Messenger 发回 POST 请求。在这期间我们一直没有回应我们阻塞的原始 Messenger请求。这会导致超时和 5XX 错误。
上述情况是我在解决遇到错误时发现的,当用户发送表情时实际上是发送的 unicode 标识符,但是被 Python 错误的编码了,最终我们发回了一些乱码。
这个发回 Messenger 的 POST 请求将永远不会完成,这会导致给初始请求返回 5xx 状态码,显示服务不可用。
通过使用 encode('unicode_escape') 封装消息,然后在我们发送回消息前用 decode('unicode_escape') 解码消息就可以解决。
def send_message(token, recipient, text):
"""Send the message text to recipient with id recipient.
"""
r = requests.post("https://graph.facebook.com/v2.6/me/messages",
params={"access_token": token},
data=json.dumps({
"recipient": {"id": recipient},
"message": {"text": text.decode('unicode_escape')}
}),
headers={'Content-type': 'application/json'})
if r.status_code != requests.codes.ok:
print r.text
部署到 Heroku
一旦代码已经建立成我想要的样子时就可以进行下一步。部署应用。
那么,该怎么做?
我之前在 Heroku 上部署过应用(主要是 Rails),然而我总是遵循某种教程做的,所用的配置是创建好了的。而在本文的情况下,我就需要从头开始。
幸运的是有官方 Heroku 文档来帮忙。这篇文档很好地说明了运行应用程序所需的最低限度。
长话短说,我们需要的除了我们的代码还有两个文件。第一个文件是“requirements.txt”,它列出了运行应用所依赖的库。
需要的第二个文件是“Procfile”。这个文件通知 Heroku 如何运行我们的服务。此外这个文件只需要一点点内容:
web: gunicorn echoserver:app
Heroku 对它的解读是,我们的应用通过运行 echoserver.py 启动,并且应用将使用 gunicorn 作为 Web 服务器。我们使用一个额外的网站服务器是因为与性能相关,在上面的 Heroku 文档里对此解释了:
Web 应用程序并发处理传入的 HTTP 请求比一次只处理一个请求的 Web 应用程序会更有效利地用测试机的资源。由于这个原因,我们建议使用支持并发请求的 Web 服务器来部署和运行产品级服务。
Django 和 Flask web 框架提供了一个方便的内建 Web 服务器,但是这些阻塞式服务器一个时刻只能处理一个请求。如果你部署这种服务到 Heroku 上,你的测试机就会资源利用率低下,应用会感觉反应迟钝。
Gunicorn 是一个纯 Python 的 HTTP 服务器,用于 WSGI 应用。允许你在单独一个测试机内通过运行多 Python 进程的方式来并发的运行各种 Python 应用。它在性能、灵活性和配置简易性方面取得了完美的平衡。
回到我们之前提到过的“requirements.txt”文件,让我们看看它如何结合 Virtualenv 工具。
很多情况下,你的开发机器也许已经安装了很多 python 库。当部署应用时你不想全部加载那些库,但是辨认出你实际使用哪些库很困难。
Virtualenv 可以创建一个新的空白虚拟环境,以便你可以只安装你应用所需要的库。
你可以运行如下命令来检查当前安装了哪些库:
kostis@KostisMBP ~ $ pip freeze
cycler==0.10.0
Flask==0.10.1
gunicorn==19.6.0
itsdangerous==0.24
Jinja2==2.8
MarkupSafe==0.23
matplotlib==1.5.1
numpy==1.10.4
pyparsing==2.1.0
python-dateutil==2.5.0
pytz==2015.7
requests==2.10.0
scipy==0.17.0
six==1.10.0
virtualenv==15.0.1
Werkzeug==0.11.10
注意:pip 工具应该已经与 Python 一起安装在你的机器上。如果没有,查看官方网站如何安装它。
现在让我们使用 Virtualenv 来创建一个新的空白环境。首先我们给我们的项目创建一个新文件夹,然后进到目录下:
kostis@KostisMBP projects $ mkdir echoserver
kostis@KostisMBP projects $ cd echoserver/
kostis@KostisMBP echoserver $
现在来创建一个叫做 echobot 的新环境。运行下面的 source 命令激活它,然后使用 pip freeze 检查,我们能看到现在是空的。
kostis@KostisMBP echoserver $ virtualenv echobot
kostis@KostisMBP echoserver $ source echobot/bin/activate
(echobot) kostis@KostisMBP echoserver $ pip freeze
(echobot) kostis@KostisMBP echoserver $
我们可以安装需要的库。我们需要是 flask、gunicorn 和 requests,它们被安装后我们就创建 requirements.txt 文件:
(echobot) kostis@KostisMBP echoserver $ pip install flask
(echobot) kostis@KostisMBP echoserver $ pip install gunicorn
(echobot) kostis@KostisMBP echoserver $ pip install requests
(echobot) kostis@KostisMBP echoserver $ pip freeze
click==6.6
Flask==0.11
gunicorn==19.6.0
itsdangerous==0.24
Jinja2==2.8
MarkupSafe==0.23
requests==2.10.0
Werkzeug==0.11.10
(echobot) kostis@KostisMBP echoserver $ pip freeze > requirements.txt
上述完成之后,我们用 python 代码创建 echoserver.py 文件,然后用之前提到的命令创建 Procfile,我们最终的文件/文件夹如下:
(echobot) kostis@KostisMBP echoserver $ ls
Procfile echobot echoserver.py requirements.txt
我们现在准备上传到 Heroku。我们需要做两件事。第一是如果还没有安装 Heroku toolbet,就安装它(详见 Heroku)。第二是通过 Heroku 网页界面创建一个新的 Heroku 应用。
点击右上的大加号然后选择“Create new app”。
为你的应用选择一个名字,然后点击“Create App”。
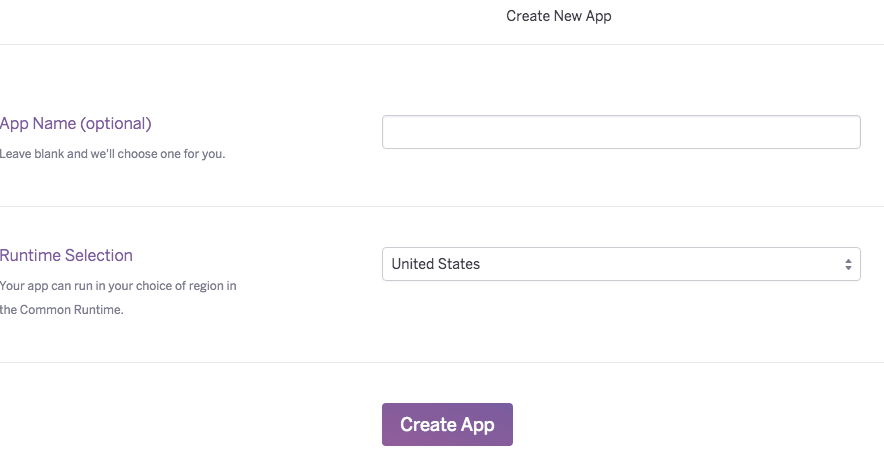
你将会重定向到你的应用的控制面板,在那里你可以找到如何部署你的应用到 Heroku 的细节说明。
(echobot) kostis@KostisMBP echoserver $ heroku login
(echobot) kostis@KostisMBP echoserver $ git init
(echobot) kostis@KostisMBP echoserver $ heroku git:remote -a <myappname>
(echobot) kostis@KostisMBP echoserver $ git add .
(echobot) kostis@KostisMBP echoserver $ git commit -m "Initial commit"
(echobot) kostis@KostisMBP echoserver (master) $ git push heroku master
...
remote: https://<myappname>.herokuapp.com/ deployed to Heroku
...
(echobot) kostis@KostisMBP echoserver (master) $ heroku config:set WEB_CONCURRENCY=3
如上,当你推送你的修改到 Heroku 之后,你会得到一个用于公开访问你新创建的应用的 URL。保存该 URL,下一步需要它。
创建这个 Facebook 应用
让我们的机器人可以工作的最后一步是创建这个我们将连接到其上的 Facebook 应用。Facebook 通常要求每个应用都有一个相关页面,所以我们来创建一个。
接下来我们去 Facebook 开发者专页,点击右上角的“My Apps”按钮并选择“Add a New App”。不要选择建议的那个,而是点击“basic setup”。填入需要的信息并点击“Create App Id”,然后你会重定向到新的应用页面。
在 “Products” 菜单之下,点击“+ Add Product” ,然后在“Messenger”下点击“Get Started”。跟随这些步骤设置 Messenger,当完成后你就可以设置你的 webhooks 了。Webhooks 简单的来说是你的服务所用的 URL 的名称。点击 “Setup Webhooks” 按钮,并添加该 Heroku 应用的 URL (你之前保存的那个)。在校验元组中写入 ‘myvoiceismypasswordverifyme’。你可以写入任何你要的内容,但是不管你在这里写入的是什么内容,要确保同时修改代码中 handle\_verification 函数。然后勾选 “messages” 选项。
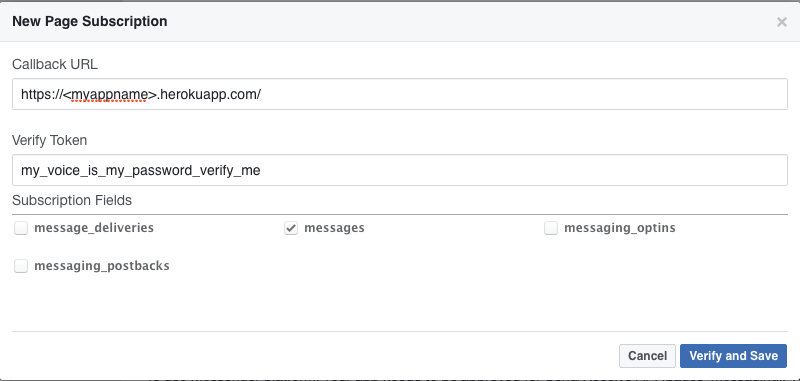
点击“Verify and Save” 就完成了。Facebook 将访问该 Heroku 应用并校验它。如果不工作,可以试试运行:
(echobot) kostis@KostisMBP heroku logs -t
然后看看日志中是否有错误。如果发现错误, Google 搜索一下可能是最快的解决方法。
最后一步是取得页面访问元组(PAT),它可以将该 Facebook 应用于你创建好的页面连接起来。
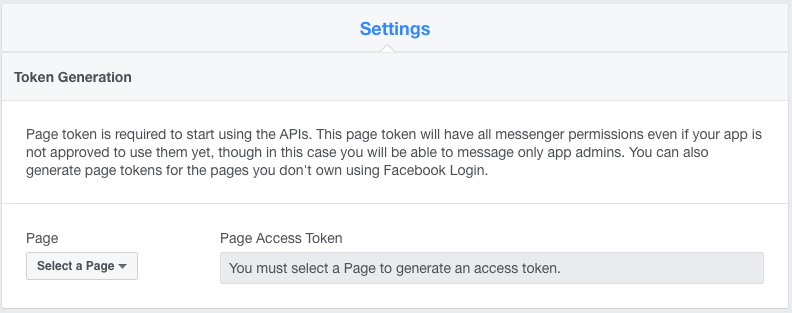
从下拉列表中选择你创建好的页面。这会在“Page Access Token”(PAT)下面生成一个字符串。点击复制它,然后编辑 echoserver.py 文件,将其贴入 PAT 变量中。然后在 Git 中添加、提交并推送该修改。
(echobot) kostis@KostisMBP echoserver (master) $ git add .
(echobot) kostis@KostisMBP echoserver (master) $ git commit -m "Initial commit"
(echobot) kostis@KostisMBP echoserver (master) $ git push heroku master
最后,在 Webhooks 菜单下再次选择你的页面并点击“Subscribe”。
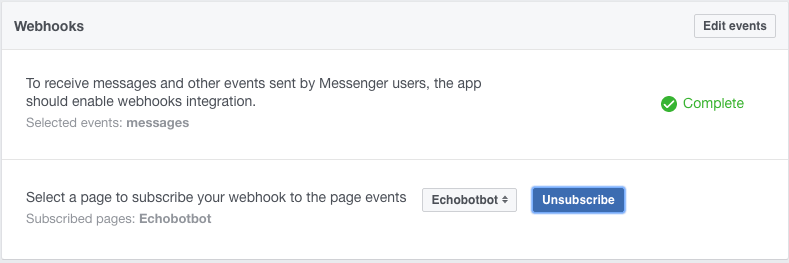
现在去访问你的页面并建立会话:
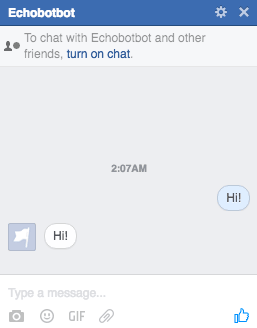
成功了,机器人回显了!
注意:除非你要将这个机器人用在 Messenger 上测试,否则你就是机器人唯一响应的那个人。如果你想让其他人也试试它,到 Facebook 开发者专页中,选择你的应用、角色,然后添加你要添加的测试者。
总结
这对于我来说是一个非常有用的项目,希望它可以指引你找到开始的正确方向。官方的 Facebook 指南有更多的资料可以帮你学到更多。
你可以在 Github 上找到该项目的代码。
如果你有任何评论、勘误和建议,请随时联系我。
via: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/
作者:Konstantinos Tsaprailis 译者:wyangsun 校对:wxy
本文由 LCTT 原创翻译,Linux中国 荣誉推出